 关于DRAM的性能分析和发展
关于DRAM的性能分析和发展
如果人类创造了一个真正有自我意识的人工智能,那么等待数据到达可能会让它倍感沮丧。
过去二十年来,基于 DRAM 的计算机内存的存取带宽已经提升了 20 倍,容量增长了 128 倍。但延迟表现仅有 1.3 倍的提升,卡内基梅隆大学的研究者 Kevin Chang 如是说,他提出了一种用于解决该问题的新型数据通路。
现代计算机需要大量高速度、高容量的内存才能保证持续运转,尤其是工作重心是内存数据库、数据密集型分析以及越来越多的机器学习和深度神经网络训练功能的数据中心服务器。尽管研究人员已经在寻找更好、更快的替代技术上努力了很多年,但在性能优先的任务上,DRAM 仍旧是人们普遍采用的选择。
这有助于解释今年的 DRAM 销量激增,尽管据 IC Insights 报告称供应有限让其平均售价增长了 74%。售价激增让 DRAM 市场收入达到了创纪录的 720 亿美元,帮助将 IC 市场的总收入推升了 22%。据这份 IC Insights 报告说,如果没有来自 DRAM 价格的额外增长(过去 12 个月增长了 111%),那么 2017 年整个 IC 市场的增长将只能达到 9%,相比而言 2016 年仅有 4%。
对于 DRAM 这样一个很多人都想替代的成熟技术而言(因为它的速度达不到处理器一样快),这个数字确认惊人。当前或未来有望替代 DRAM 的技术有很多,但专家们似乎认为这些技术还无法替代 DRAM 的性价比优势。就算用上 DRAM 技术上规划的改进方案以及 HBM2 和 Hybrid Memory Cube 等新型 DRAM 架构,DRAM 和 CPU 之间的速度差距依然还是存在。
Rambus 的系统与解决方案副总裁和杰出发明家 Steven Woo 在 CTO 办公室中说,来自 JEDEC 的下一代 DRAM 规格 DDR5 的密度和带宽都是 DDR4 的 2 倍,可能能够带来一些提速。
对于需要密集计算而且对时间敏感的金融技术应用以及其它高端分析、HPC 和超级计算应用而言,这将会非常重要——尤其是当与专用加速器结合起来时。
Woo 说:“对更高内存带宽和更大内存容量的需求是显然存在的,但 DDR5 本身并不足以满足这些需求,我们也不清楚其它哪些技术可能会取得成功。我们已经看到很多处理过程(比如加密货币挖矿和神经网络训练)正从传统的 x86 处理器向 GPU 和专用芯片迁移,或者对架构进行一些修改,让数据中心中的处理更靠近数据的存储位置,就像边缘计算或雾计算。”

图 1:新标准的引入;来自 Cadence
据 Babblabs 公司 CEO 兼斯坦福大学 System X 的战略顾问 Chris Rowen 说,对于在神经网络上训练机器学习应用而言,GPU 显然最受欢迎的,但芯片制造商和系统制造商也在实验一些稍微成熟的技术,比如 GDDR5,这是一种为游戏机、显卡和 HPC 开发的同步图形 RAM,英伟达也正是这么使用它的。
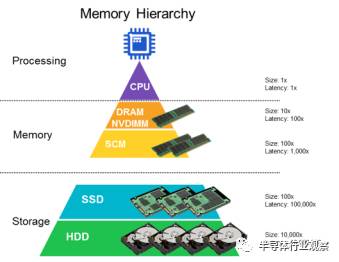
图 2:内存在芯片层次结构中的位置;来自 Rambus
由 SK 海力士和三星制造的 HBM2 将一些高速 DRAM 芯片放在了增加了一些逻辑处理的层级以及提供了到处理器的高速数据链路的 interposer 之上,从而让内存与处理器之间的距离比 GDDR5 的设计更近。HBM2 是高速度至关重要的 2.5D 封装中的一项关键元素。HBM2 是一项与 Hybrid Memory Cube 相竞争的 JEDEC 标准。Hybrid Memory Cube 是由 IBM 和美光开发的,使用了过硅通孔(TSV)来将不同的内存层连接到基础逻辑层。
应用硅光子学的光学连接(optical connection)也能实现加速。到目前维持,大多数硅光子学应用都在数据中心中的服务器机架和存储之间以及高速网络连接设备内部。业内专家预计这种技术将会在未来几年里向离处理器更近的位置迁移,尤其是当其封装技术得到完全验证并且设计流程将这项技术包含进来之后。光学方法的优势是发热很慢而且速度非常快,但光波还是要在转换成电信号之后才能存储和处理数据。
另外还有 Gen-Z、CCIX、OpenCAPI 等新型互连标准,也有 ReRAM、英特尔的相变 3D Xpoint、 3D NAND 和磁相变 MRAM 等新型内存类型。
NVDIMM 速度更慢但容量更大,增加电池或超级电容可以实现非易失性,从而让它们可以使用更低的功耗缓存比普通 DRAM 更多的数据,并且还能保证它们在断电时不会丢失交易数据。据八月份来自 Transparency Market Research 的一份报告称,支持 NVDIMM 的芯片制造商包括美光和 Rambus,预计其销售额将会从 2017 年的 7260 万美元增长到 2025 年的 1.84 亿美元。
选择这么多,可能会让人困惑,但针对机器学习或大规模内存数据库或视频流来调整内存性能会让选择更轻松一些,因为其中每种任务都有不同的瓶颈。Rowen 说:“实现带宽增长有一些主流的选择——DDR3、DDR4、DDR5,但你也可以尝试其它选择,从而让内存带宽满足你想做的事情。”
Rowen 说,对于有意愿编写直接控制 NAND 内存的代码的人来说,整个问题可能还会更简单;而如果是鼓捣协议和接口层,让 NAND 看起来就像是硬盘并且掩盖在上面写入数据的难度,那就可能会更加困难。“有了低成本、容量和可用性,我认为在让闪存存储包含越来越多存储层次上存在很多机会。”
冷却 DRAM
Rambus 的内存与接口部门的首席科学家 Craig Hampel 说,每一种内存架构都有自己的优势,但它们都至少有一个其它每一种集成电路都有的缺点:发热。如果你能可靠地排出热量,你就可以将内存、处理器、图形协处理器和内存远远更加紧密地堆积到一起,然后可以在节省出的空间中放入更多服务器,并且还能通过减少内存与系统其它组件之间的延迟来提升性能。
液体冷却是让绝缘矿物油流经组件的冷却方法。据 IEEE Spectrum 2014 年的一篇文章称,液体冷却让香港的比特币挖矿公司 Asicminer 的 HPC 集群的冷却成本降低了 97%,并且还减少了 90% 的空间需求。
自 2015 年以来,Rambus 就一直在与微软合作开发用于量子计算的内存,这是微软开发拓扑量子计算机工作的一部分。因为量子处理器只能在超低温环境下运行(低于 -292℉/-180℃/93.15K),所以 Rambus 正为该项目测试的 DRAM 也需要在这样的环境下工作。Rambus 在 4 月份时扩展了该项目,那时候 Hampel 说该公司已经确信寒冷能带来重大的性能增益。
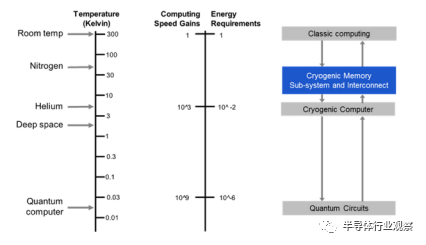
图 3:低温计算和存储;来自 Rambus
比如,当 CMOS 足够冷时,CMOS 芯片的数据泄露(data leak)就会完全停止。几乎就会变成非易失的。它的性能会增长,能让内存的速度赶上处理器的速度,从而消除 IC 行业内一大最顽固的瓶颈。在 4K 到 7K 这样极端低温的环境下,线材将变成超导体,让芯片仅需非常少的能量就能实现长距离通信。
低温系统还有额外的优势。比起空调制冷,低温系统能从堆叠的内存芯片中抽取出更多热量,从而可实现更大的堆叠(或其它组装方式)密度,实现更高效的协作。Hampel 说:“抽取热量让你能将服务器机架的大小减小多达 70%,这意味着数据中心每立方英尺的密度增大了。这让它们更容易维护,也可以更容易地将它们放在之前无法到达的地方。”
更重要的是,如果在处理器层面上实现的效率提升与数据中心其它地方的提升基本一致,那么低温系统可以让现有的数据中心更有成本效益和实现更高效的计算,从而可以减少对更多数据中心的需求。
而且不需要非常冷就可以收获其中大多数效益;将内存冷却到 77K(-321℉/-196℃)就能得到大多数效益了。
Hampel 说:“液氮很便宜——每加仑几十美分,而且在达到大约 4 K 的超级冷之前,成本上涨其实也并不快。降到50K 左右其实并不贵。”
接近处理器
据 Marvell 存储部门总监 Jeroen Dorgelo 说,超低温冷却可以延长数据中心中 DRAM 的寿命,但随着行业从 hyperscale 规模向 zettascale 规模演进,已有的任何芯片或标准都无法应付这样的数据流。他说,DRAM 虽快但功率需求大。NAND 不够快,不适合扩展,而大多数前沿的内存(3D XPoint、MRAM、ReRAM)也还无法充分地扩展。
但是大多数数据中心还没有处理好变得比现在远远更加分布式的需求。据 Marvell 的连接、存储和基础设施业务部网络连接 CTO Yaniv Kopelman 说,分布式有助于减少远距离发送给处理器的数据的量,同时可将大多数繁重的计算工作留在数据中心。
IDC 的数据中心硬件分析师 Shane Rau 说,社交网络、物联网和几乎其它每个地方的数据所带来的压力正迫使数据中心蔓延扩展——在全国各地建立两三个大规模数据中心,而不是在单一一个地方建一个超大规模数据中心。
Rau 说:“规模确实不一样,但问题的关键仍然是延迟。比如说,如果我旁边就有一个数据中心,我就不需要将我的数据移动太远距离,而且我可以在我的笔记本电脑上完成一些处理,更多的处理则在本地数据中心中进行,所以在数据到达它要到达的位置时已经经过一些处理了。很多人在谈将处理工作放到存储的位置是为了平衡不同设备基础上的瓶颈。现在,规模问题更多是关于让数据中心在边缘完成一些工作,即数据的产生位置和数据的最终去处之间。”
-
处理器
+关注
关注
68文章
19250浏览量
229610 -
DRAM
+关注
关注
40文章
2309浏览量
183426 -
数据中心
+关注
关注
16文章
4758浏览量
72025
发布评论请先 登录
相关推荐
DRAM的基本构造与工作原理
DRAM与NAND闪存价格大幅下跌
SRAM和DRAM有什么区别
DRAM存储器的基本单元
晶闸管与IGBT的性能分析
DRAM芯片的基本结构
DRAM内存操作与时序解析

DRAM价格下半年或将持续上涨
使用新的DRAM进步来提高嵌入式系统的性能
三星电子:2025年步入3D DRAM时代
三星2025年后将首家进入3D DRAM内存时代
DRAM供应链在改善亏损的同时,需应对需求挑战
JEDEC发布:GDDR7 DRAM新规范,专供显卡与GPU使用






 工商网监
工商网监
评论