 关于英特尔发力FPGA的相关事件分析
关于英特尔发力FPGA的相关事件分析

芯片巨头英特尔已经谈论 CPU-FPGA 复合计算很长时间了,以至于我们有时候不记得其 Xeon-Arria 混合计算单元并不是一款量产产品——这种计算单元是将一个 Xeon 服务器芯片和一个中端 FPGA 放入单个 Xeon 处理器插槽中。但英特尔正在努力攻坚这一领域,并且最近也向 The Next Platform 透露了当前的规划。
这种 CPU-FPGA 混合器件类似于 AMD 的加速计算单元(APU/Accelerated Computing Units),只是 APU 是将计算和 GPU 加速放入单个处理器封装中。CPU-FPGA 混合器件有望得到广泛的采用,尤其是想要将特定类型的负载从 CPU 迁移到加速器上的超大规模计算用户和云计算开发商。
尽管英特尔有自家的 GPU 并且也已经为特定的市场将其放入到了 CPU 封装中或 CPU die 上(比如基于 Xeon E3 芯片的用于加速媒体处理的低端工作站和低端服务器),但英特尔在将 Xeon 处理器上的负载迁移到其它器件上的热情并不高。它首先打造了并行 X86 处理器的 Knights 系列来作为辅助引擎,之后又将其做成了一款完整的处理器 “Knights Landing” Xeon Phi 7200,这款处理器在 2015 年底开始初步出货,并在 2016 年夏季正式发布。英特尔已经终结了 Knights Landing 芯片的协处理器版本,它们从未真正出货,因为客户只是需要使用可以运行他们自己的操作系统的 Xeon Phi 的托管版本。
也就是说,FPGA 和 GPU 一样,只是一种迁移计算负载的模式;英特尔正在努力将各种各样的 FPGA 配置带进这一领域,以确保计算负载确实能以某种形式从 Xeon CPU 迁移到 Xeon Phi(可用于传统的 HPC 和新兴的人工智能负载,主要是用于神经网络训练)或 Altera FPGA 或之前提到的那些低端的 CPU-GPU 混合器件。英特尔肯定不希望英伟达的 Tesla GPU 加速器或 AMD 的 Epyc CPU 和 Radeon Instinct GPU 组合占领这些市场。
英特尔在与 FPGA 制造商 Altera 达成了代工合作协议之后就开始谈论 Xeon-FPGA 混合计算器件了,Altera 也是英特尔的第一个这样的客户。之后两家合作一路深化,直到 2015 年 6 月,英特尔用 167 亿美元收购了整个 Altera。在今年休假离开之前负责管理英特尔的数据中心组的 Diane Bryant 曾在 2014 年 6 月即兴宣布了第一款 CPU-FPGA 器件,那是在英特尔收购 Altera 的一年之前。那时候,Bryant 说向这种计算复合体中加入 FPGA 可以提供多达 10 倍的加速,这可以通过使用 QuickPath Interconnect(QPI)链路直接将 FPGA 连接到 Xeon 处理器上实现。该链路通常用于多处理器系统中的 NUMA 扩展,相比于使用 PCI-Express 外设总线,它的性能可高出 20 倍。
英特尔最后真的收购了 Altera,这没什么惊奇的。Altera 是 FPGA 领域的两大主要玩家之一,另一家是赛灵思(Xilinx)。如果非要说有让人惊讶的地方,那就是英特尔出的钱太多了,毕竟 Altera 的年收入还不到 20 亿美元。英特尔和 Altera 的这笔交易也让我们看到了英特尔的担忧。这家公司将会使用 FPGA 来对抗 GPU,之后该公司还表示预计在 2020 年之前,三分之一的云开发商(也包括超大规模计算用户)的系统中都会使用 FPGA。由于 FPGA 在一些负载上有 10 到 20 倍的性能优势,加上数量巨大,所以可能会给 Xeon 的销量带来巨大影响。(目前我们尚未看到这种效果,但想象一下如果用 CPU 来实现深度学习奇迹,得需要多少 CPU 和多高的成本。这方面的创新可能根本就没有发生过。)
到目前为止,英特尔 Xeon 还在热销,即使 FPGA 和 GPU 等加速器正在侵蚀 Xeon 的业务。除了 SmartNIC 网络接口和其它网络功能虚拟化工作,FPGA 也已被用于执行服务器加密以及加速关系数据库,正如 Swarm64 做的那样。在一些案例中,FPGA 卡有自己的内存和计算,只将一些核心的串行任务交给 CPU 做,比如来自 Nallatech 的双 FPGA 协处理器就是这样。
顺便一提,让 FPGA 与处理器协同工作并不是什么新花样。赛灵思和 Altera 都在同一个片上系统封装中集成 FPGA 和 ARM 处理器很多年了,而且英特尔本来也可以在用于超大规模计算的 Xeon D X86 芯片设计上做同样的事。事实上,这个本可以做到的事情后来造就了第二代测试台 CPU-FPGA 混合器件,英特尔在 2016 年 3 月展示了这种器件。
英特尔可编程解决方案组的 FPGA 软件解决方案高级总监告诉 Bernhard Friebe 说,这种器件在同一个封装中放入一个 15 核的 Broadwell Xeon 处理器和一个 Arria 10 FPGA,这不是 Stratix 10 一样的顶级部件。该器件使用了英特尔的 14nm 工艺生产,目前正在实验性生产,有望在今年年底前开始出货。
英特尔采用的是双管齐下的 FPGA 战略:一是 CPU-FPGA 混合器件,比如共享同一个插槽的 Broadwell-Arria 封装;二是分立的 Xeon CPU 与 Arria 或 Stratix FPGA 通过 PCI-Express 总线彼此相连。
据 Friebe 说,英特尔的当前计划是基于 Arria 10-GX FPGA 打造自己的 PCI-Express 卡,英特尔将其称为可编程加速卡(PAC/programmable acceleration card),并计划在 2018 年上半年开始销售。后面也会有基于 Stratix 10 FPGA 的 PAC,但英特尔没说什么时候会有。我们估计大概在 2018 年年底。
英特尔的 CPU-FPGA 混合器件包含一款尚未命名的 “Skylake” Xeon SP 处理器加 Arria 10 FPGA 组合器件。这些 CPU-FPGA 混合器件将会在实验性的 Broadwell-Arria 器件基础上继续前进,并会使用更快的 UltraPath Interconnect(UPI)链路在一个 Socket P 插槽中将 FPGA 直接连接到 Skylake 芯片。我们也知道这是一种单插槽机器,所以这可能意味着会有一个 bin 相对低的 Skylake 部件(也许是 Silver 或 Bronze),也可能只有一个 UPI 链路。(更多不一定更好。)
目前还不清楚这两个计算元件之间的链路数量是 1 还是 2 还是 3,但是鉴于 Skylake 可以有 1、2 或 3 个 UPI 端口,根据模型的不同,这三者皆有可能。我们也不清楚英特尔打算在这两个器件之间使用什么一致性模型,但很显然这能让 CPU 和 FPGA 可以读写同一个内存并且无需在两个器件传递数据——不管是直接传递还是使用虚拟寻址移动指针。如果英特尔选择 CCIX、Gen-Z 或 OpenCAPI 这三种新兴的协议,情况就会相当有趣,因为这些协议在器件之间提供的一致性能使得内存寻址对编程者而言不可见。我们应该会看到。
我们可以确定地说英特尔正在专注研发编程环境,这样不管 CPU 和 FPGA 是分立的还是混合在同一个插槽中,都能使用同样的工具。英特尔将其称为 Acceleration Stack,这是一个基于 OpenCL 的完备的编程环境。OpenCL 是一种常用的高级编程语言,可以与 Verilog 和 VHDL 配合用于 FPGA 开发。
这种用于 FPGA 的 Acceleration Stack 是专门为英特尔器件设计的。据 Friebe 说,Acceleration Stack 组合了英特尔的系统与 FPGA 的固件与 Open Programmable Acceleration Engine(OPAE)开源框架。其中包含用于运行在裸机上的操作系统的实体 FPGA 驱动和一个虚拟 FPGA 驱动——这个虚拟 FPGA 驱动可以运行在服务器虚拟化管理程序之下,从而可在虚拟机上实现功能。
英特尔的想法是构建一个一致的 API 集合,可通过 C 语言访问,可以用于混合或分立的设置,并且像 OPAE 代码一样开源,在 GitHub 上放养。这个 FPGA API 使用了 BSD 许可,这个 FPGA 驱动使用了 GNU GPLv2 许可。有很多公司必须获得许可的 OpenCL 工具,英特尔也有自己的,称为 Intel FPGA for OpenCL,它可以进行各种优化以便在 FPGA 上运行。
如果这些工具能吸收 C 语言代码并将其转换成 OpenCL 代码,然后转换成 VHDL,那么这可能会非常有用。我们预计,有了这个 OPAE 软件层,这个堆栈中更高层的应用框架就会与 OPAE 通信以便将负载迁移到 FPGA 上,这样可以极大简化编程任务。当然,OpenCL 代码也会被自动编译成 FPGA 可用的 VHDL。
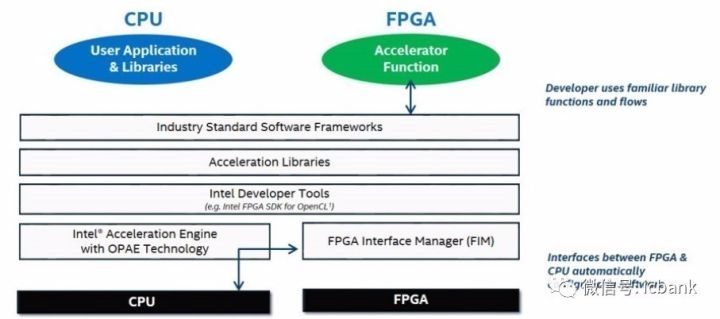
英特尔关注的核心是让 FPGA 编程更简单,同时也保持其两大分支的一致性。FPGA 本质上编程就更难一些。你怎么看待介于硬件和软件中间的东西?
也许最有意思的地方在于英特尔非常坚定地要使用 FPGA 来加速机器学习负载,尤其是用于推理阶段,而且它还将为此推出自己的预配置 FPGA 算法,其客户可以像获取软件一样获得这些算法的许可。这也是大概两年半之前出现关于英特尔收购 Altera 的传言时我们所做过的预测。
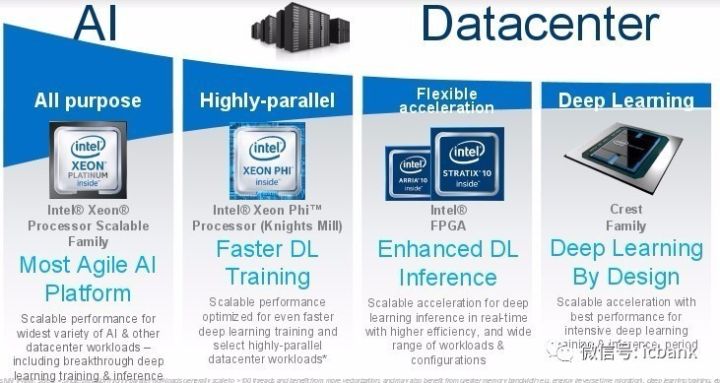
但英特尔在人工智能方面有很多不同的计划齐头并进,不知道他们的客户会做何选择。
我们一直疑惑的是该在什么时候使用混合设置,又该在什么时候使用分立的 CPU 和 FPGA 设置。混合器件的计算能力中规中矩,但却有更高的内存带宽和更低的延迟;分立方法则可以组合更多 CPU 计算(使用 Xeon SP 的 2、4 或 8 插槽)和更多 FPGA 计算(可以加入多达 16 个 PCI-Express 卡,在服务器中有 8 个。FPGA 本身有大量不同的连接和 I/O 选择,因为这也可以使用 VHDL 编程。
“根据你想做的事情的不同,有很多不同的使用模式。”Friebe 说,“集成解决方案主要用作旁路加速器。数据进入 CPU,然后它将任务分配给 FPGA,结果又返回 CPU,你就得到了加速。使用分立的卡时,你可以扩展到其它使用模式。比如,你可以在在线的或流传输的模式中使用这样的 FPGA,其中数据可以经由高带宽接口直接输入 FPGA;然后经过 PCI-Express 链路,这些经过 FPGA 加工过的数据可以被发送到 CPU 做进一步处理。”
也可能有一些场景需要在同一个系统中同时使用这两种方法,毕竟过去发生过更奇怪的事情。
-
FPGA
+关注
关注
1664文章
22503浏览量
639252 -
英特尔
+关注
关注
61文章
10322浏览量
181086 -
人工智能
+关注
关注
1820文章
50325浏览量
266955
发布评论请先 登录
被指存散热硬伤,英特尔代工iPhone芯片几无可能?
AI工作站本地养龙虾!英特尔双芯混合算力,告别云端Token焦虑

杰和科技亮相英特尔高峰论坛 以全栈智算方案助力产业智能升级

英特尔Arria V系列FPGA器件全面解析:特性、性能与应用考量
英特尔Arria 10器件:高性能与低功耗的完美结合
五家大厂盯上,英特尔EMIB成了?
锐宝智联入选英特尔首批尊享级合作伙伴

英特尔举办行业解决方案大会,共同打造机器人“芯”动脉

向新而生,同“芯”向上!2025英特尔技术创新与产业生态大会在重庆举行

英特尔连通爱尔兰Fab34与Fab10晶圆厂,加速先进制程芯片生产进程
使用英特尔® NPU 插件C++运行应用程序时出现错误:“std::Runtime_error at memory location”怎么解决?
英特尔锐炫Pro B系列,边缘AI的“智能引擎”

分析师:英特尔转型之路,机遇与挑战并存
直击Computex2025:英特尔重磅发布新一代GPU,图形和AI性能跃升3.4倍




评论