 基于深度学习的推荐算法大部分都存在不同程度的数据集缺失和源码缺失
基于深度学习的推荐算法大部分都存在不同程度的数据集缺失和源码缺失
【导读】来自意大利米兰理工大学的 Maurizio 团队近日发表了一篇极具批判性的文章,剑指推荐系统领域的其他数十篇论文,指出这些论文中基于深度学习的推荐算法大部分都存在不同程度的数据集缺失和源码缺失,导致它们无法复现,而那些可复现的算法,其性能也难以达到预期,甚至难以超越基于传统的、简单的机器学习推荐算法。
推荐系统领域研究的潜在问题
近年来,基于深度学习的算法是非常热门的研究方向,其在许多领域,如计算机视觉,自然语言处理等领域都取得了巨大的成功,因此许多研究人员也期待能借助深度学习方法在推荐系统领域取得突出的进展,例如基于长期依赖配置和基于场景的 top-n 推荐算法。近年来也有许多基于深度学习的推荐算法发表在知名会议和期刊上,然而过去有工作指出这些深度学习推荐算法并不是完全可信的,主要存在以下三个问题:
许多声称有提升的方法事实上并不能超越经过合理调参的基准对比工作,甚至不能超越很简单的传统方法。具体来说,这些方法在实验上存在一定的缺陷。
基准对比工作的选择问题:许多方法选择的对比工作本身就有问题,不是广义上的基准工作。并且该领域的基准工作很混乱,不太统一。
不同工作采用的数据集,验证方法,性能指标,数据预处理步骤都不同,这使得性能对比很困难,无法确定哪个工作在相同的应用环境中表现最好。而且很多工作不开源数据和代码,这不符合现在的代码开源趋势,甚至即使开源了,也不把完整代码放出来。
系统的算法评估标准
为了深入探究基于深度学习的推荐算法是否存在以上问题,作者制定了两个算法评估标准:
可复现性:能否通过代码和数据集重现文中的实验结果
性能评估:这些工作和基准工作相比能提高多少
在此标准的基础上,作者评估了近几年发表在顶尖会议上,运用深度学习方法来实现 top-n 推荐的 18 篇工作,最后发现:只有七篇工作是可复现的;而这 7 篇工作中,有 6 篇都没能超越传统的、经过合理调参的启发式方法。即使是简单地将最流行的items推荐给每个用户(TopPopular),也能在特定的性能指标衡量下超越深度学习方法达到最优。
文章可复现性判断
(一)调研文章范围
作者收集了2015年到2018年 KDD、SIGIR、WWW 和 RecSys 会议上的研究工作,这些论文都是采用基于深度学习的方法来解决top-n分类问题的。在此基础上,只考虑与精度评估有关的工作,因此最终筛选出了18篇文章。
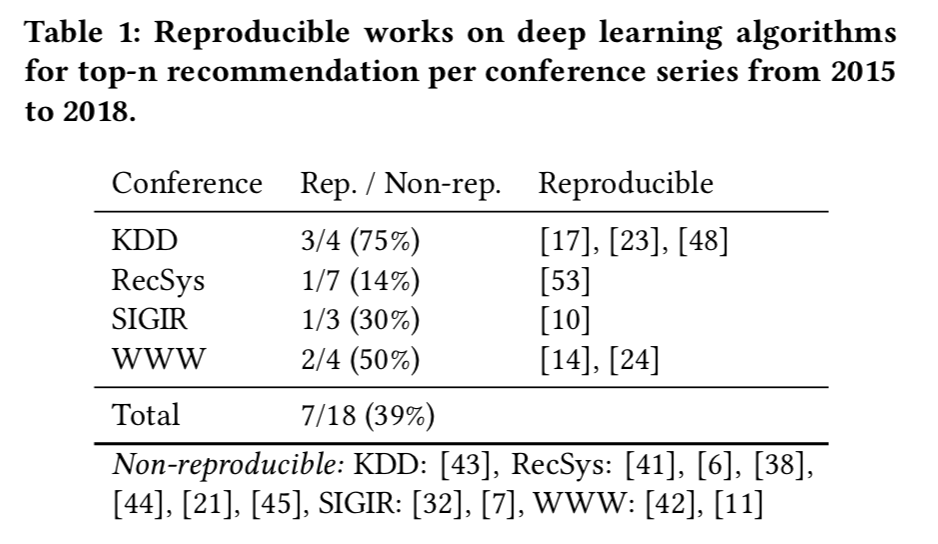
(二)可复现性的数据和代码标准
首先,尽量通过文章原作者提供的源码和数据来复现结果。由于有太多的实现细节以及验证程序需要考虑,想要单纯的依靠作者提供的资源来重现文中的结果是很难的。为了解决这个问题,作者扩大了代码和数据的搜索范围,只要是和原文章有关的代码,即便不是官方代码也考虑在内,如果实在找不到现成的实现代码和数据,就联系原文作者并等待30天。在进行了以上步骤后,将同时满足以下两个条件的文章定性为可复现文章,具体的:
1、有源代码,并且源代码只需要微小的细节改动(例如调整路径,调整工作环境)就能正确运行。如果只是有一个代码框架,而缺少许多细节,是不满足这个要求的。
2、至少有一个文中用到的数据集是可以获得并使用的(某些文章用的数据集是自建数据集或者不是公开数据集,对于作者而言很难获取)。而且训练集和验证集的划分方法也是在文中或者源码中进行明确阐述的。
最终,18篇文章中只有 7 篇满足以上条件,具备可复现性。作者还表示:“这是一个惊人的结果,如果深入追究可能会涉及到学术造假问题,就不贴那些结果不能复现的文章编号了”。
可复现工作的性能评估
在挑选出 7 篇可复现的工作后,作者进一步的评估了它们的性能。为了保证不同方法之间的可对比性,本文介绍了两种评估策略。第一种评估策略是将所用的方法和基准方法在同样的测试流程和测试集上进行评估,这有助于横向对比不同的方法在同一数据集上的性能差异,虽然这种策略在之前的类似文章中已经用过,但会导致验证方法和每个方法的原始文章中采用的方法有一定的差距,因此不能完全反应原始方法的性能(不完全复现)。
为了解决这个问题,作者提出将超参调优过程和测试过程分开进行,保证所有的方法(包括基准)方法都使用相同的测试代码,但是允许它们有不同的调参过程,这样每种方法都可以按照原文中提出的调参策略在自己的数据集上,即保证完全复现了原文方法,又保证不同方法之间具有可对比性。
基准方法的选择
所有的基准方法都是简单的非神经网络,启发式算法,或者说基于传统机器学习和统计学的方法。选择简单的非深度学习方法作为基准方法,通过和基于深度学习的方法进行对比,以验证模型复杂度的提升能否带来性能上的显著提升,作者得到的结论是不能。一方面是因为该领域的研究过于跟风使用深度学习方法,没有细致严谨地去研究问题的本质,另一方面也是因为神经网络本身没有那么强大(现在有许多工作都是对神经网络的真实能力提出了质疑),当然,学术上的不严谨也是一个重要原因(可能存在的造假行为)。
本文主要采用了如下几种基准方法:
TopPopular:直接统计“最流行”的items(物品,项目)并推荐给每个用户,这里的“最流行”可以用不同的指标来衡量。
ItemKNN:基于K最近邻算法的一种推荐算法,衡量指标是物品之间的距离,因此是基于相似物品的推荐算法。首先通过TF-IDF或BM25算法获取每个物品对每个用户的隐式评分(评价向量,rating vector,可以简单理解为该用户对该物品的需求程度),然后按照以下公式计算两个物品之间的距离:
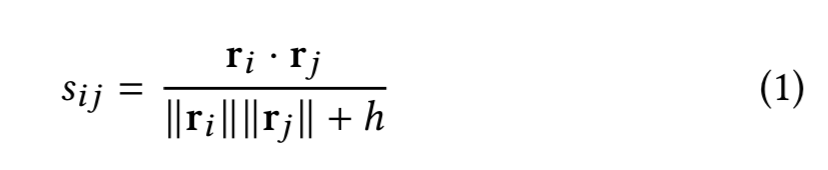
UserKNN:基于相似用户的推荐算法,类似于ItemKNN,只不过计算样本点变成了每个用户自身的评级。
ItemKNN-CBF:基于内容过滤的相似物品推荐算法,CBF表示content-based-filtering,在标准ItemKNN的基础上,将物品自己的特征向量作为距离衡量向量。
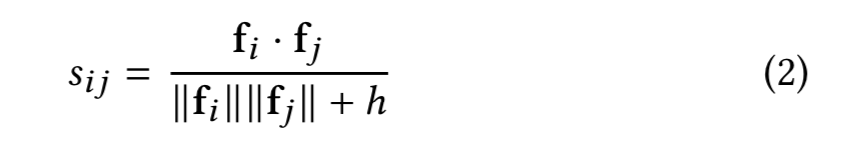
ItemKNN-CFCBF:将每个物品的排名向量和特征向量结合,这样每个物品就由两个向量表示,通过计算两个物品的向量之间的余弦夹角来衡量相似度。
 :基于随机游走的方法,从用户 u 游走到物品 i 的概率为:
:基于随机游走的方法,从用户 u 游走到物品 i 的概率为:
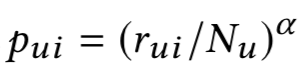
是物品 i 对用户 u 的评级向量,是用户 u 的评级,α 是阻尼因子。同理,从商品 i 游走到用户 u 的概率为:
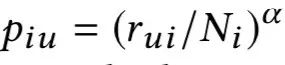
其中是商品 i 的评级。最后,两个商品 i,j 的相似度计算公式为:

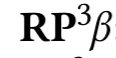 是
是 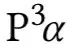 另一个版本,将
另一个版本,将  输出的相似度进一步地按系数 β 扩张,所有基准方法都采用贝叶斯搜索来获取最优参数。
输出的相似度进一步地按系数 β 扩张,所有基准方法都采用贝叶斯搜索来获取最优参数。
算法性能测试与对比结果
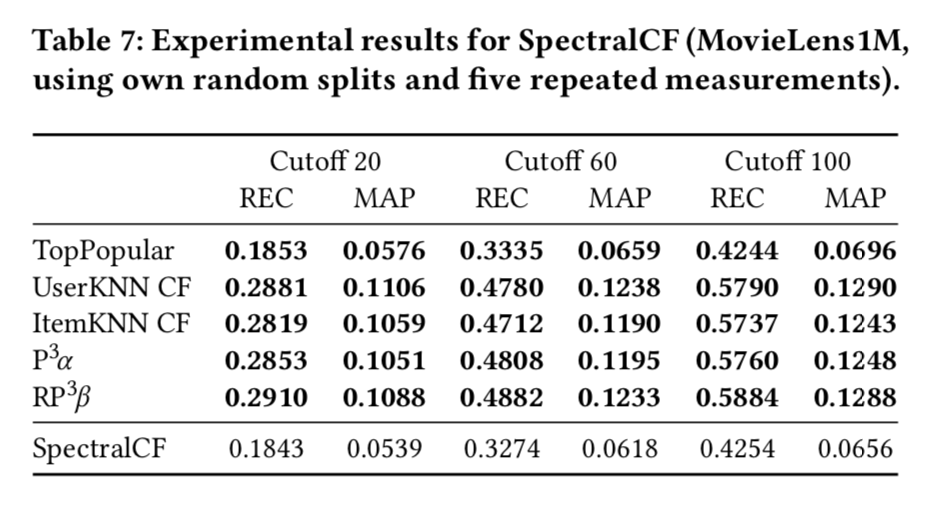
通过将可复现的 7 个方法与基准方法在相同数据集上进行测试,可以评估这些可复现方法的真实性能。这里主要评估之前挑选的7中可复现方法,其中只有Collaborative Variational Autoencoder(CVAE)能在同等训练条件下超越传统方法,其他算法都不如同等测试条件下的传统方法。
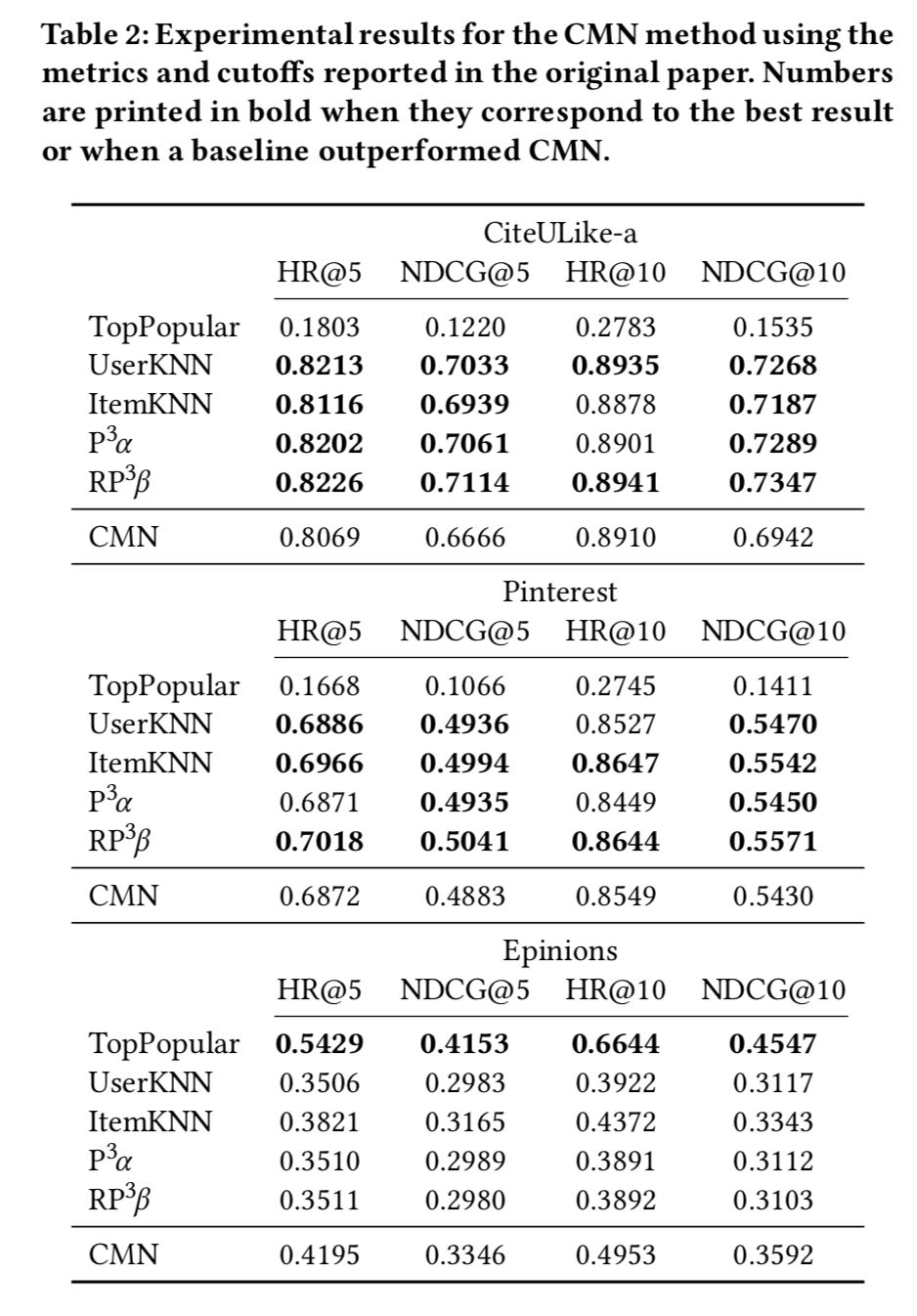
CMN方法的实验结果
MCRec方法的实验结果

CVAE实验结果
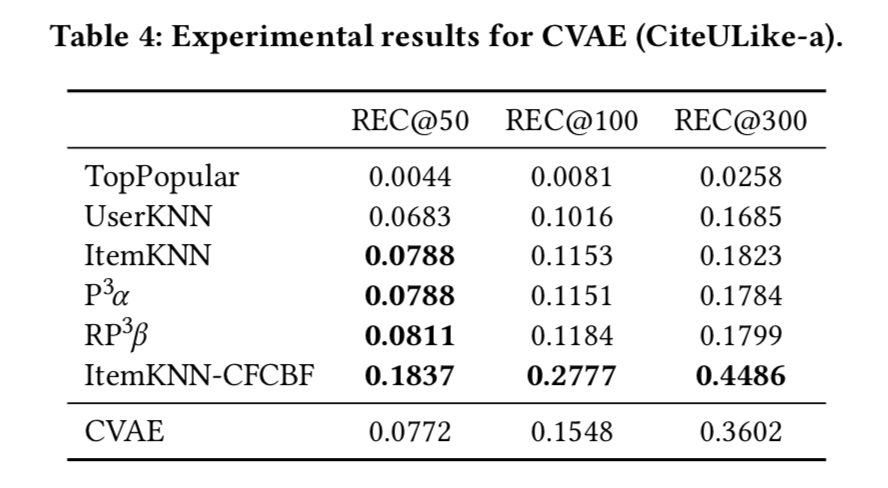
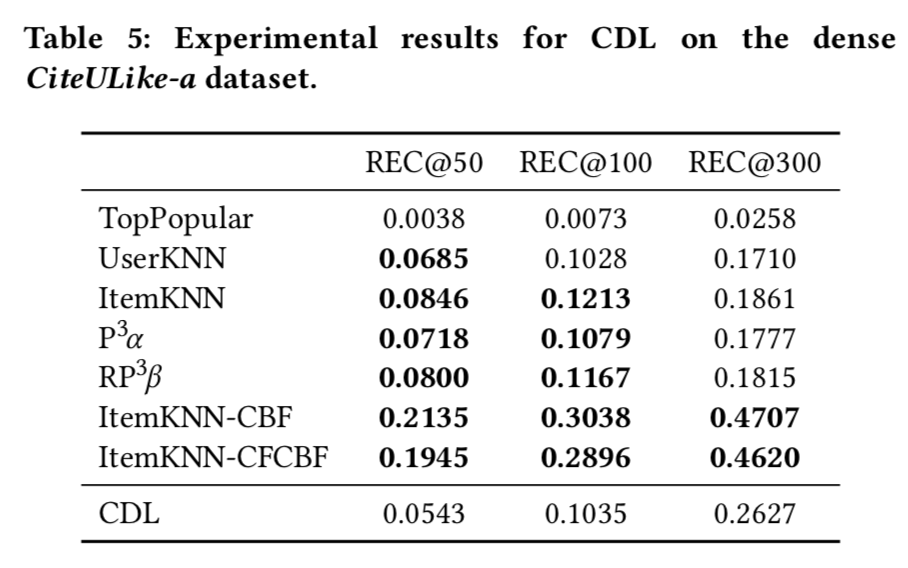
CDL实验结果
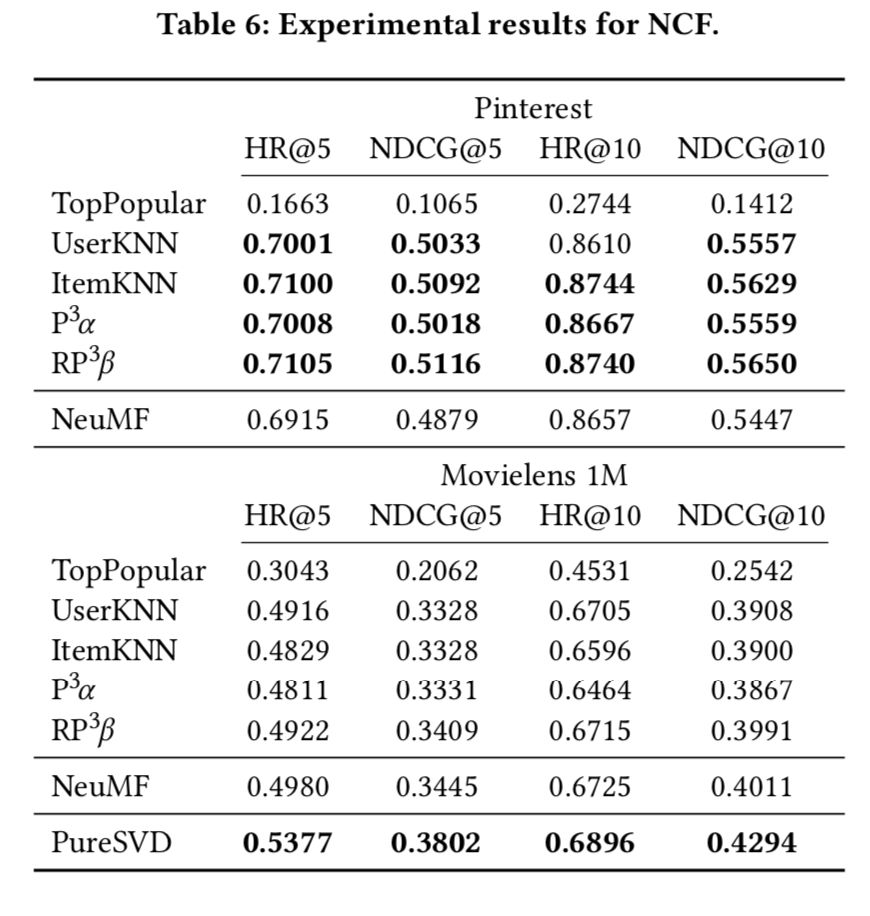
NCF 实验结果
SpectralCF 实验结果
结论
本文主要关注近年来发表在热门会议上的基于深度学习的 top-n 推荐算法,聚焦于它们的可复现性和真实性能。结果表明大部分算法都无法重现理想结果,甚至无法超越传统的启发式算法,这说明推荐算法领域的研究和审核需要更加严谨和仔细,算法的性能评估需要更加标准,正确的方法。文中提到的那些无法复现和效果低于预期的工作肯定会被重新审核,甚至退回。
-
数据集
+关注
关注
4文章
1208浏览量
24689 -
深度学习
+关注
关注
73文章
5500浏览量
121113 -
自然语言处理
+关注
关注
1文章
618浏览量
13552
原文标题:数十篇推荐系统论文被批无法复现:源码、数据集均缺失,性能难达预期
文章出处:【微信号:rgznai100,微信公众号:rgznai100】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
电压缺失
处理数据缺失的结构化解决办法
能见度与缺失分析的改进PageRank算法

无线传感网络缺失值估计方法
基于距离最大化和缺失数据聚类的填充算法
基于加性噪声的缺失数据因果推断
外媒:iOS14.3仍存在SMS短信和消息通知缺失问题

基于张量的车辆交通数据缺失估计方法
缺失值处理你确定你真的会了吗






 工商网监
工商网监
评论