 JD和OPPO的研究人员们提出了一种姿势引导的时尚图像生成模型
JD和OPPO的研究人员们提出了一种姿势引导的时尚图像生成模型

时尚总在引领潮流。
在人工智能、增强现实、可穿戴、虚拟试妆等技术的加持下,时尚行业特别是在线时尚行业获得了飞速的发展。为了吸引客户更多的目光、更棒的视觉体验、更好地展现商品,高清大图、模特多角度摆拍已经成了服装、箱包、鞋类、美妆等线上商家的宣传标配。在网上购物时,大家都想看看模特衣服在各种角度姿势下的样子,但是越多越全面的姿势摆拍也就意味着越大的投入。为了降低宣传成本,很多研究开始聚焦于如何合成高质量的逼真图像。
在这篇文章中来自北卡罗来纳大学、JD和OPPO的研究人员们提出了一种姿势引导的时尚图像生成模型,可以基于模特当前姿势,生成出其他各种不同姿势下的相同着装的新图像!也许在这样技术的帮助下,模特再也不用辛苦一分钟拍二十个动作了~
生成新姿势下的时尚图像
研究人员的主要目的在于训练一个生成模型,将模特在当前姿势上的图像迁移到其他的目标姿势上去,实现对于衣着等商品的全面展示。
这一模型主要由生成器和判别器构成,与先前工作不同的是这一模型架构中包含了两个不同的判别器!其中生成器由两个编码器构成,分别用于从图像和对应的动作关键点特征图进行编码,而解码器则用于从动作和衣着的特征中合成目标图像。对于判别器来说,除了判定生成图像是否逼真外、还需要判定动作与生成图像的连续性以保证生成图像动作的连续性和鲁棒性。
模型的主要架构,生成器的编码器包含了对于图像的编码器Ei和对动作的编码器Ep,基于U-Net和bi-LSTM共同构建而成,而两个判别器分别用于判定图像的真伪并保证生成图像与动作间的连续性。
时尚图像生成器
生成器中主要包含了两个编码器和一个解码器用于处理图像和对应姿势,生成器探索了输入图像的视觉语义特征和位姿信息,并生成对应姿势下的新图像。图像编码器:图像编码器的目标是从单张或多张图像中湖区语义编码信息。研究人员首先使用了ResNet作为主干网络抽取不同尺度的特征,包括纹理、颜色、边缘线条信息等。随后将这些特征输入到双边长短时记忆网络(bc-LSTM)中用于从相同衣着不同视角的模特图像中抽取共同的特征,将不同种类的图像特征进行转换,同时对不同特征下的背景和噪声进行处理。最终得到了可以表达图像视觉语义信息的编码Ci,用于后续图像的生成。位姿编码器:模型同时需要位姿数据来为生成图像进行引导,研究人员利用了18个关键点来表示人体位姿,用不同颜色的直线相连并以RGB的格式进行表示。通过U-Net的架构和3*3的卷积从位姿图中抽取高层次语义特征Cp并在解码过程中通过跳接层连接进行特征共享。解码器:其主要目的是通过图像编码Ci 和动作编码Cp重建出逼真的图像。首先将图像编码与位姿编码的编码拼接在一起,并基于U-Net架构和跳接层将视觉语义信息与动作编码信息匹配起来,进行有效的图像生成。判别器:其主要目标是引导模型生成比先前模型更逼真图像。在训练过程中研究人员利用两个判别器来同时进行对抗训练,主要采用了与PatchGAN类似的实现。其中Di用于判别生成图像是否逼真,与先前的模型类似;而Dp则用于判定生成图像与对应动作的连续性。Dp的输出是真实图像与对应位姿和这一位姿下生成的图像,用于判定图像是否与位姿匹配,它对于生成与位姿对应的时尚图像具有重要的作用,能帮助网络生成更为复杂的动作姿势,同时保持连续性和鲁棒性。
结果展示
通过DeepFashion和Market-1501数据的训练后研究人员得到了不错的结果。
Deep Fasion 数据集
Market-1501数据集
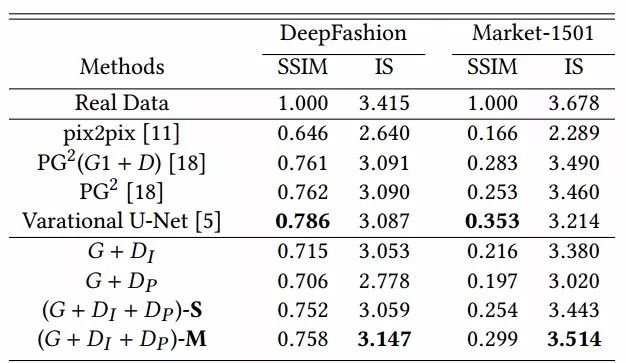
生成的结果与先前方法的比较,其中S和M代表了单张和多张图像输入的生成结果:
在数据集上的表现还不错,从源图像生成了新的姿势:
-
解码器
+关注
关注
9文章
1225浏览量
43755 -
图像
+关注
关注
2文章
1096浏览量
42437 -
模型
+关注
关注
1文章
3811浏览量
52257
原文标题:从姿势到图像——基于人体姿势引导的时尚图像生成算法
文章出处:【微信号:thejiangmen,微信公众号:将门创投】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
一种图像语义分层处理框架,可以实现像素级别的图像语义理解和操纵
研究人员提出了一种柔性可拉伸扩展的多功能集成传感器阵列
特伦托大学与Inria合作:使用GAN生成人体的新姿势图像
OpenAI的研究者们提出了一种新的生成模型,能快速输出高清、真实的图像
以色列研究人员开发出了一种能够识别不同刺激的新型传感系统
研究人员们提出了一系列新的点云处理模块

Facebook的研究人员提出了Mesh R-CNN模型

研究人员推出了一种新的基于深度学习的策略
研究人员开发出了一种称为LB-WayPtNav-DH的机器人导航新框架
研究人员开发了一种新颖的机器学习管道
微软亚洲研究院的研究员们提出了一种模型压缩的新思路
一种基于改进的DCGAN生成SAR图像的方法




评论