 Facebook的研究人员提出了Mesh R-CNN模型
Facebook的研究人员提出了Mesh R-CNN模型
随着计算机视觉的发展,2D目标检测在精度和速度方面已经得到了巨大的提升,并在各个领域取得了令人瞩目的成绩。但2D检测却忽视了物体的三维信息。目前的3D形状预测研究主要基于合成数据集和当个目标的预测。
为了解决这一问题,来自Facebook的研究人员提出了Mesh R-CNN模型,可以从单张输入图像中检测不同物体,并预测出每个物体对应的三角网格,将二维目标检测的能力成功地拓展到了三维目标检测和形状预测。

三维目标检测与形状预测
近年来深度学习在三维形状理解领域有了很大的提升,研究人员们利用神经网络对体素、点云、网格等三维表示进行学习,推进了三维世界表示和理解的发展。但这些技术主要基于合成数据集进行开发和研究,缺乏复杂的形状和条件,相比二维图像的大型数据集还远远不够。研究人员认为三维研究领域需要开发新的识别与理解系统,可以在非限制环境、复杂形状、多物体以及光照条件变化的情境下稳定运行。
为了实现这一目标,研究人员开发了2D感知和3D形状预测的方法,可以在单张RGB输入的情况下实现目标检测、实例分割以及目标3D三角网格预测的功能。这一方法基于Mask R-CNN改进而来,增加了网格预测分支来输出高分辨的目标三角网格。这种方法预测出的网格不仅能够捕捉不同的3D结构中,同时可以适用于不同的几何复杂度。Mesh R-CNN克服了先前固定网格模板的形态预测方法,利用多种三维表示方法完成预测。
Mesh R-CNN首先预测出目标粗糙的体素、随后转换为网格并利用精确的网格预测分支进行优化,最后实现了对于任意几何结构的精细预测。
Mesh R-CNN
这一研究的目标是通过单张图像输入,对图像中的物体进行检测、获取不同物体的类别、掩膜和对应的三维网格,并对真实世界中的复杂模型进行有效处理。在2D深度网络的基础上,研究人员改进并提出了新的架构。

这一模型主要分为三个部分,包括了预测box和mask的检测分支、预测体素的分支和mesh优化分支。受到RoIAlign的启发,研究人员在网格预测中加入了VertAlign将输入图像与特征进行对应。
体素预测分支与box/mask预测分支的输入相同,都使用了与图像对齐的特征。模型最后将目标检测、语义分割损失与网格预测损失结合起一同对网络进行端到端的训练和优化。Mesh R-CNN的核心是网格预测器,它将对齐的图像特征进行输入,并输出目标的三维网格。与二维图像的处理相似,研究人员同时也维护了特征在不同阶段的对齐,包括区域和体素对应的对齐操作(RoIAlign和VertAlign),并捕捉图像中所有实例的3D形状。
这意味着每一个预测出的网格都具有自己的拓扑结构(包括网格种类、一定数量的顶点、边和面)以及几何形状。这一模型可以预测不同形状和拓扑结构的网格。
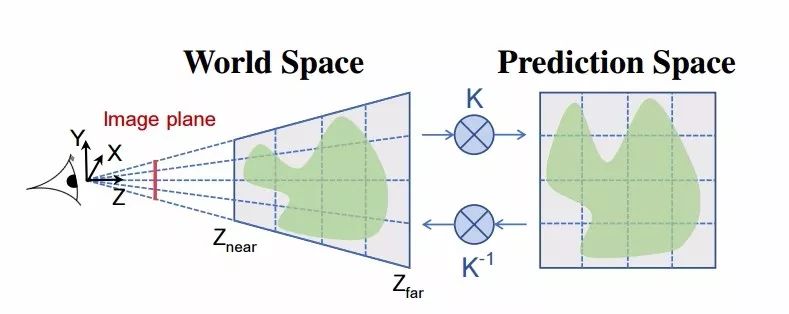
模型的体素分支将针对每一个检测到的物体预测栅格在空间中的占据概率,并得到三维模型最终的形状结果。可以将其视为3D版的Mask R-CNN,利用GxGxG的栅格在三维空间中预测出目标的外形。
同样和Mask R-CNN类似的是,对于体素的预测同样适用了来自RoIAlign的特征,并得到G个通道特征,其中的体素表示了输入位置的占据分数,在实验中研究人员使用了24x24x24大小的体素表示。

随后立方体化方法(Cubify)将3D体素的占据概率转换为三角网格模型。它将输入的占据概率二进制输出,每一个体素占据点被一个立方体的三角网格代替,包含了8个顶点、18条边和12个面。相邻立方体共享边,紧邻的面被消除,最终得到与体素形态学相同的网格表示。
最后需要将得到的网格进一步优化以获取更为精确的结果。与很多体素/网格的优化方法相同,首先需要将顶点与图像特征对齐,随后利用图网络卷积的方法在每一条mesh边上对信息进行传播,最后将得到的结果用于更新每一个顶点的位置。
上面三个步骤在优化过程中不断进行。最后为了给mesh优化分支建立损失,研究人员在网格表面进行稠密的采样得到点云来计算网格优化分支的损失。
结果
最终研究人员在ShapeNet 数据集和Pix3D数据集上验证了这种方法的有效性。可以看到新提出的方法可以有效地预测带有孔洞的物体。
同时对于复杂环境中的三维物体也有良好的预测效果:
文章附录里给出了包括立方体化、网格采样、消融性分析以及与各种方法的比较,如果想要了解更多的实现细节,请参看:
https://arxiv.org/pdf/1906.02739.pdf
ref:
paper:https://arxiv.org/pdf/1906.02739.pdf
logopicture:https://dribbble.com/shots/1143435-Pikachu-Polymon
-
图像
+关注
关注
2文章
1085浏览量
40476 -
Facebook
+关注
关注
3文章
1429浏览量
54774 -
数据集
+关注
关注
4文章
1208浏览量
24710
原文标题:Facebook研究员提出Mesh R-CNN,向三维进击的目标检测!
文章出处:【微信号:thejiangmen,微信公众号:将门创投】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
介绍目标检测工具Faster R-CNN,包括它的构造及实现原理

什么是Mask R-CNN?Mask R-CNN的工作原理
手把手教你操作Faster R-CNN和Mask R-CNN
研究人员们提出了一系列新的点云处理模块

JD和OPPO的研究人员们提出了一种姿势引导的时尚图像生成模型
研究人员提出了一个名为CommPlan的框架
Facebook向研究人员发布友谊数据
基于改进Faster R-CNN的目标检测方法
华裔女博士提出:Facebook提出用于超参数调整的自我监督学习框架
基于Mask R-CNN的遥感图像处理技术综述
用于实例分割的Mask R-CNN框架
PyTorch教程14.8之基于区域的CNN(R-CNN)

PyTorch教程-14.8。基于区域的 CNN (R-CNN)






 工商网监
工商网监
评论