 关于新版 ISO 26262-6 之基于模型的设计的分析和应用
关于新版 ISO 26262-6 之基于模型的设计的分析和应用
为什么ISO26262这样的国际标准里会频频提到基于模型设计?
原因非常简单——基于模型设计在汽车行业已经被广泛应用了。作为国际标准,ISO26262的目的之一应该是通过标准的方式规范行业开发行为,所以制定标准的基础就是这种开发行为在行业的广泛应用。这在民航领域的DO-178也可以得到印证,早在1992年发布的DO-178B,标准里没有任何关于基于模型设计的讨论——因为那个年代没有公司使用基于模型设计开发民航软件,而到2011年发布DO-178C的时候,同时发布了附件DO-331专门讨论基于模型的设计在民航软件开发中的应用,因为在2011年,基于模型设计已经在民航领域广泛应用了。
基于模型设计的讨论在ISO26262-6里面,跟第一版一样,除了标准正文的各种条款里提到基于模型设计模式下应该如何要求之外,还专门有附录B讨论基于模型设计。本篇主要介绍附录B的一些变化。
线下交流
ISO 26262研讨会
主要介绍MathWorks工具链对于ISO26262和SOTIF的支持情况,涵盖满足ISO26262要求的模型验证和代码验证、符合ISO26262软件开发过程中的工具审核问题,以及针对无人驾驶应用的场景建模仿真等方向。扫描二维码注册>>
跟第一版不同的是,第一版的附录B基本上只提到了基于模型设计如何如何的好,而第二版除了保留了这些优势的陈述之外,还提到了在这种开发模式下的注意事项。主要优势如标准所言,基于模型设计将“软件生命周期的各个阶段实现了更强的聚合(Strongercoalescence),并且认为:
“Thispotentialbenefitsofthisapproach(e.g.continuity,informationsharingacrossthesoftwarelifecycle,consistency)areappealing.”
同时跟了一句:
“butthisapproachmayalsointroduceissuescausingsystematicfaults(SeeB.3).”
于是就有了B.3,下面我们就对照B.3着重看一下可能有哪些风险以及如何应对。
一. 文本性描述
标准对单一的建模语言可能不足以充分描述需求、架构以及单元设计有所顾虑。确实如此,如果你认为既然选择了基于模型设计,所有的需求、设计都使用图形化描述,完全没有文字说明的话,那的确是有问题的。标准要求在图形化描述不足以完整描述需求、设计的时候,增加文字性描述。
这部分内容不仅仅在附录里有体现,在标准正文里也有改变,Table2中的1a,就是新增的内容,并且针对不同的ASIL等级,都给出了++的要求。
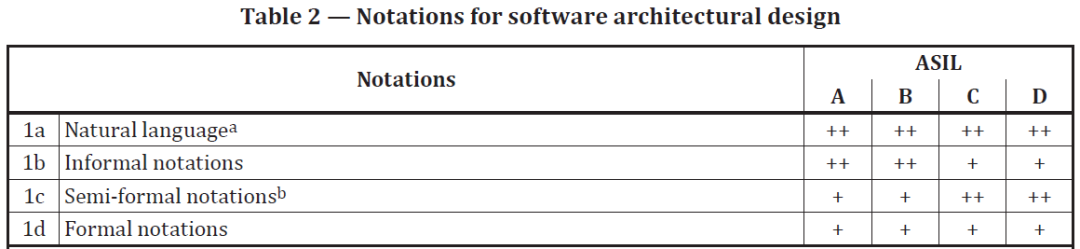
从本人的开发经验,以及这些年接触到的客户来看,没遇到有用户仅依赖于模型而不使用文字描述的案例,标准里对这部分内容的增加,或许是制定标准的人或者做标准认证的人遇到了这种情况。
其实Simulink模块有很几种方式可以增加文字性的描述,比如简单的文字注释,或者正式的需求文档,如下图:

实现这部分要求,难度不大。
二. 背靠背(back-to-back)测试
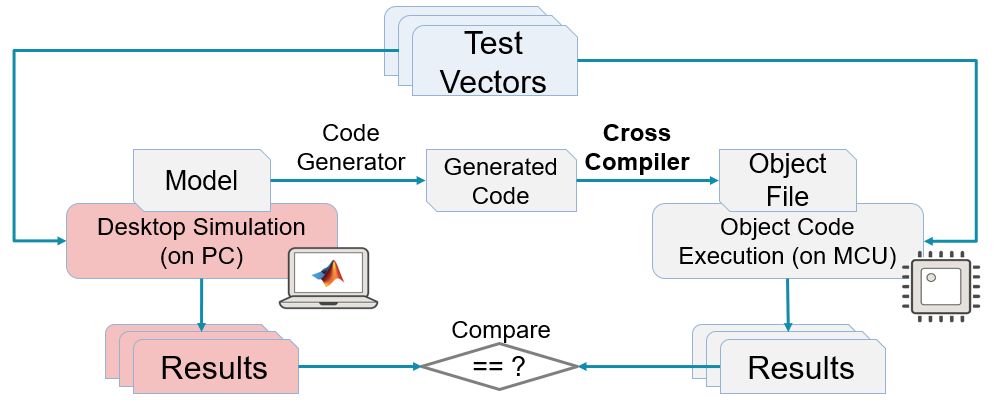
上图就是一种背靠背测试的实现方式,这里的目标代码运行在MCU上,我们称之为PIL。PIL之外,SIL测试也是一种背靠背测试,前面也有介绍(为什么一定要做SIL测试)。
显然上述图中的PIL测试是为了检查模型生成的代码在MCU上运行,从行为上讲,跟模型是否一致。
如果同样的测试向量(TestVectors)在两边运行的结果一致,那么我们可以认为代码和模型在行为上一致。注意,需要有个前提,那就是测试数据足够多,可以覆盖所有软件结构以及信号范围,那是最好的。通常,我们在这个时候除了重用功能测试的测试用例之外,还可以通过工具自动生成一些测试用例,以便可以达到更高的覆盖要求。SimulinkDesignVerifier提供测试数据自动生成功能可以用于这个阶段。
代码和模型之间的背靠背测试,主要是为了防止模型到代码的转换过程中出现错误,标准还提到了其他两种转化的过程中也可能出错:
一是从连续模型往离散模型转换的过程(离散化)中引入错误;
二是从浮点模型往定点模型转换过程(定点化)中可能出现的错误。
这种担心是有必要的,在这两种转换过程中确实可能引入错误,实践中,建议对离散化、定点化前后的模型做一个背靠背测试。
对于定点化,除了明显的定点错误会导致出错之外,还可能会隐藏一些测试数据或者测试场景覆盖不到的溢出。所以,定点化之后的模型建议通过SimulinkDesignVerifier检查一下是否有溢出问题。
另外,标准提到了仿真或者验证的工具依赖问题,其实从SIL和PIL测试中,算法的运行平台已经是完全不同的了,模型仿真的时候,是Simulink引擎解析模型运行,SIL测试的时候,运行的是生成代码编译之后的动态链接库,PIL更是运行到了目标处理器之上。
三. 安全相关的代码设置
代码的安全相关设置,可以通过代码生成设置和建模实现,比如,标准提到的溢出问题,在生成代码的设置里,就有默认的优化设置如下:

当然,如果你非常关心代码效率,并且能够确保数据不会发生溢出,也可以通过勾选上述选项达到代码优化的目的,切记,前提是确保数据不会发生溢出!
如何确保?人工确保非常困难,可以通过形式化工具SimulinkDesignVerifier实现。
另外,还有一些对代码的保护要求,比如,有安全要求的代码要放到专属的Flash区域。通常,代码上可以通过在这段代码前后增加#pragma的方式实现,这可以通过自定义存储类的方式实现。
还有一类要求,比如在运行某段代码的时候不响应中断:

这可以通过建模实现,比如,模型中增加SystemOutputs模块,设置相关参数得以实现。
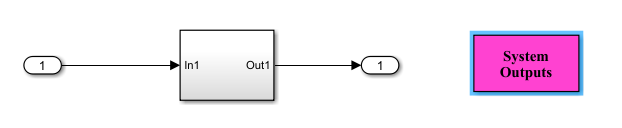
如果还有其他的安全要求,也可以跟我们交流。
四. 代码优化问题
针对不同的优化目标,代码可以做不同的优化,比如说,在新能源汽车领域,BMS开发中可能更关心代码的RAM占用,而电机控制器开发中更关心代码的执行速度。对于这两种情况,显然优化目标不同,选择的优化设置也会有所区别。
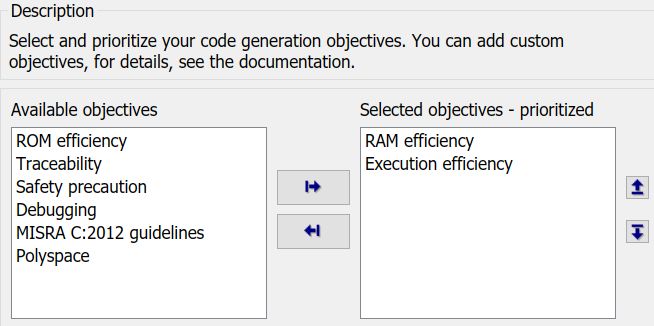
对应不同的目标,会有很多相关的优化选项需要设置。幸运的是,代码生成工具提供了上图的功能,用户只需设置目标,工具会根据你设定的目标给出相应的建议。
五. 组件模型代码生成问题
到底在单元模型级别还是集成模型级别(包括组件级集成和系统级集成)上做代码生成这样的问题,我一直认为要慎重,基础软件对于应用软件的调度应该是我们要考虑的。对于简单的调度,不同任务之间不存在抢占,不存在中断,在集成模型上做代码生成会更加方便,而如果任务之间可能存在抢占或者中断,那么就要仔细评估了,因为,Simulink目前并不能仿真抢占或者中断行为。
六. 被控对象模型的精度问题
这个问题会出现在MIL和HIL测试中,通过被控对象模型实现模型级闭环测试。理论上讲,精度越高越好,但实践上,我们可能很难有高精度并且非常完善的模型。这不影响我们利用MIL和HIL测试给我们带来的便利。如果有理想中的高精度模型,我们完全可以在模型阶段把标定做完,而事实上,我们没有那样的模型,我们也不期望这个阶段完成标定工作。我们希望可以通过这些模型实现验证算法,这已经给我们带来很大便利了。
当然,也有办法让被控对象模型变得精度更高,比如可以通过台架测试数据或者实车数据去优化模型参数,还可以通过基于模型的标定(Model-BasedCalibration)技术实现部分参数的标定工作。
-
处理器
+关注
关注
68文章
19461浏览量
231421 -
代码
+关注
关注
30文章
4841浏览量
69200
发布评论请先 登录
相关推荐
嵌入式软件开发符合ISO 26262 功能安全标准
ISO 26262,太重要了

华阳通用通过ISO 26262 ASIL D认证
鉴源实验室·ISO 26262中测试用例的得出方法-等价类的生成和分析

什么是汽车ISO 26262功能安全标准?
芯来NA系列产品再获ISO 26262 ASIL-D产品认证证书

【直播预告】基于ISO 26262实现高质量的MBD过程

威灵汽车获得ISO 26262 ASIL-D汽车功能安全流程认证证书

美行科技通过ISO26262:2018汽车功能安全ASIL D流程认证

天合智控获DEKRA德凯ISO 26262汽车功能安全体系认证证书

技术分享 | ISO 26262中的安全分析之FMEA

芯驿电子获得ISO 26262汽车功能安全最高等级ASIL D认证

星宸科技获ISO 26262功能安全管理体系ASIL D等级认证,进军车规级市场
孚能科技获DEKRA德凯ISO 26262汽车功能安全产品认证证书






 工商网监
工商网监
评论