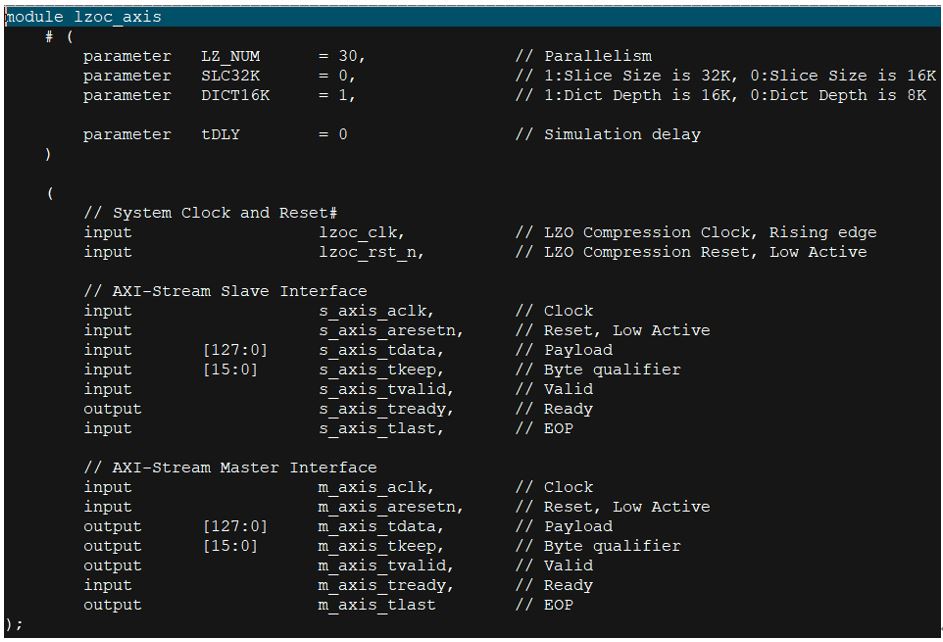
 关于WEBM视频解压缩硬件IP的介绍和分析
关于WEBM视频解压缩硬件IP的介绍和分析
WebM 项目 (www.webmproject.org) 定义了一种开放文件格式,用于在 Web 上分发压缩媒体内容。Google是 WebM 项目的主要贡献者,最近着手设计和开发了第一个用于 WebM 的硬件解码器 IP,也称为 VP9 G2解码器。利用这种免版税的硬件 IP,开发多媒体片上系统 (SoC) 设计的公司能够实现下一代性能和功率效率,在智能电视、平板电脑、移动电话以及传统个人计算机和笔记本电脑等消费电子设备上实现高达4K (2160p 60FPS) 分辨率的播放效果。VP9 G2 IP 采用全新硬件架构实现,主要是用标准 C++ 编码和验证,并利用 Catapult High-Level Synthesis (HLS) 综合为寄存器传输级 (RTL) 逻辑,以支持不同的目标技术和性能点。
本文介绍用于开发 VP9 G2 硬件解码器的 HLS 方法,并说明它如何支持实现 WebM 项目的目标和战略。本文解释了为什么HLS 方法令设计实现和验证比传统RTL 设计流程快 50%,以及它如何让不同最终产品的设计团队能够协作并为同一 IP做出贡献。

图1. VP9 G2 解码器硬件
本文还会介绍WebM 团队在成功实现 G2 VP9 的过程中如何实际使用 Catapult HLS,并分享一些结果和感想。图 1 显示了该硬件,包括 HLS 生成的 RTL 模块和手写 RTL 模块。顺便提一下,该硬件大约有 200 万门电路,采用 65 纳米 TSMC 技术,支持 4K (2160p) @ 60fps。
WEBM 项目与 G2 VP9
Google WebM 项目的主要目的是改善最终用户的网络视频体验。用户收到的视频质量在很大程度上取决于所使用的压缩格式,但遗憾的是,与消费者对在线视频的期望相比,压缩格式的发展慢如龟速。例如,高效视频编码标准(HEVC,也称为 H.265)花了 10 年时间才从 H.264 发展出来。然后,IP 设计人员又花了 1 年时间编写和验证 RTL,总共耗费 11 年时间才推出一代可用硬件。
WebM 项目的目标是大幅缩短编解码器设计周期,并计划每隔几年更新一次开放格式视频编解码器。WebM 项目的主要好处是促进硬件 IP 协作,加速创新,并加快部署新的和更好的视频压缩标准。在 WebM模型中,Google 为其半导体合作伙伴提供全功能基础 IP,鼓励他们增强 IP 并与 Google 共享这些改进,使IP 迅速发展。
目前有十亿多端点提供 VP9 解码支持,包括 Chrome 浏览器、Android、FFmpeg 和 Firefox。通过WebM 网站可索取使用 Catapult C 开发的 VP9 硬件编码器和解码器。该网站包含有关编码器和解码器性能的详细信息。
快速硬件创新的挑战
在 VP9 G2 硬件项目即将开始时,WebM 团队意识到需要一种新的硬件设计方法来支持快速创新。理想情况下,初始硬件和软件将与技术规范在同一天交付,这意味着设计人员必须能够随着规范发展而轻松调整和更新代码。
与前一代硬件相比,VP9 G2 视频硬件的复杂度增加了一倍。这意味着仿真运行时间会过于漫长,全部验证工作预计要花费数月时间。另外,在这个特定领域中,测试向量的数量相当巨大。复杂度的增加不仅会影响总验证时间,还会影响在合理时间范围内可以测试的内容。采用 RTL 仿真时,若不大幅增加测试资源,团队将无法达到所需的测试水平。
以不同产品或应用为目标的多个设计团队和公司会提出不同的 RTL 变更,合并这些变更也是不切合实际的。以 RTL 代码编写的 IP 包含一定程度的与实现相关的细节,这会显著降低 IP 的可复用性。如果设计人员想要针对不同的 ASIC 技术复用该代码,或者以更高时钟速度运行,或者改变吞吐量,他们要么必须大幅重写 RTL,要么就得接受次优的功耗、性能或面积。
WebM 团队评估了若干较高抽象层次的工具流程,发现 Catapult C 最符合其需求。
使用 C++ 相比使用 RTL 的优势
C++ 支持 Google
实现快速创新目标
Innovation
基于 C 语言的 HLS 流程大大减轻了整体 RTL 验证工作,因为它让工程团队可以更迅速地测试源代码的每项更改,并在不同的硬件和软件团队之间共享代码。源代码中的低层实现细节越少,仿真、调试和修改的速度越快。更高的仿真性能意味着可以运行更多测试以更充分地演练源代码;利用行业标准工具来监视和检查测试集提供的功能覆盖率。设计人员可以快速高效地修改并重新验证 C++ 模型来对备选算法和架构执行一系列假设评估,从而能够基于实际功耗、性能和面积(而非理论估计)来选择最佳实现。
(向上滑动查看细节)
C++ 是大多数微电子工程师熟悉的语言,常用于硬件和软件工程设计。C++ 描述代表了一种比 RTL 更抽象的编码风格,其给出的是算法和架构的描述,而不是精确到每个周期的信号和寄存器行为。与 VHDL 和Verilog 的情况非常相似,C++ 有一个可综合子集可用于建模和硬件设计。标准 C++ 结构体和方法的绝大部分都是可以使用的,只有少数例外,其依赖于底层软件处理器架构来执行(例如 “malloc”),这在硬件实现中是没有意义的。与 RTL 相比,可综合 C++ 表示的代码行数平均减少 80%,冗长细节的缩减使其对人类更有意义,调试也更容易、更快捷。类似的功能用C++ 仿真的速度要比用 RTL 快 50-1000 倍;当设计和调试复杂硬件时,使用 C++ 的硬件开发人员只需大约一半的时间。
C++ 模型常常被开发为黄金参考模型,硬件设计对照该模型进行验证。这些参考模型用作硬件实现的起点。如果 C++ 模型本身是可综合的,则可以避免手动重写入 RTL,软件或算法工程师与硬件团队之间将能实现平滑交接。这会减少因为规范模糊和误读而出错的机率。在硬件设计过程中,系统架构师和硬件设计工程师均可使用相同的共享代码库。以这种方式共享可执行代码意味着概念易于传达,构思不会有被误解的风险,并且从概念到实现,所有人都可以共享并明确无误地使用统一的规范。
在很多不同小组之间共享代码还需要一个标准化环境。对用 C++ 建模的设计进行功能验证时,可以使用众多行业标准编译器和调试工具中的任何一个,例如 gcc 或 MSVisual C++。还有许多其他工具可用于分析源代码,对源代码数据库版本加以控制,以及合并来自多个开发人员的 C++ 更改。
对于 WebM 团队的硬件 IP 开发,可在该 IP 仍处于开发阶段时,将 C++ 代码和标准化开发环境与其 IP 合作
伙伴共享。反过来,合作伙伴在此过程中也能分享见解并纠正错误,使得生产硬件几乎可以在标准最终确定并发布的同时交付。
用 C++ 能够准确描述硬件的一个重要方面是使用比特精确数据类型,运用 C++ 类库可以在任何标准 C++环境中执行。其他硬件设计特性,如时钟频率、并行性、寄存器和组件共享以及许多其他微架构细节,均未写入 C++ 代码中。C++ 模型中仅描述了算法和功能行为。这意味着只需修改用于驱动综合工具的命令和约束,同一 C++ 表示便可轻松适用于不同的微架构或性能点以及不同的实现技术(ASIC 和 FPGA)。
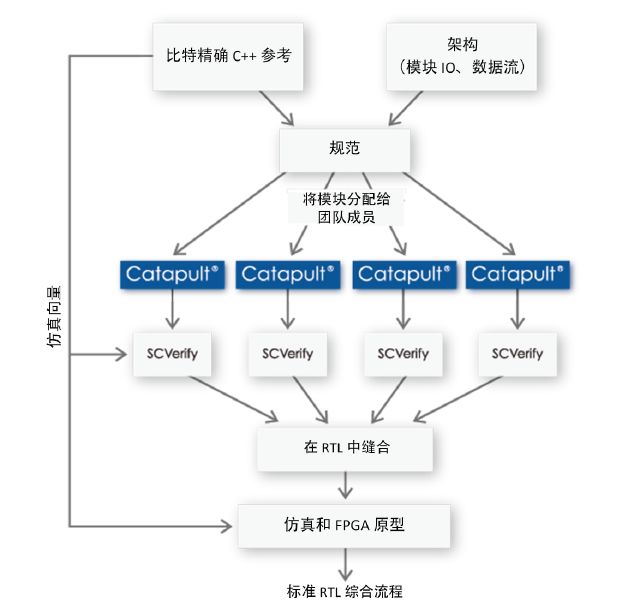
图 2. G2 VP9 设计和验证流程
为了管理其第一个 HLS 项目的风险,WebM 团队决定将视频解码器的每个模块作为一个单独的项目来实现。该流程允许多个模块由不同工程师并行优化,而顶层互连模型则是手动编写。它还支持将 Catapult 用在能够产生最大益处的地方,对算法模块进行一些必要的探索以确定最优架构。其他包含 SoC 集成关键部件(例如时钟门控、SRAM 容器)的模块则是用 RTL 实现。其结果便是图 1 所示的硬件划分,相应的设计和验证流程如图 2 所示。
WebM 工程师需要接受培训才能使用 HLS,但他们很快意识到,用 C++ 编写与用 VHDL 或 Verilog 编写具有相同的“体验”。就像用 RTL 一样,设计人员首先需要可视化其想要构建的硬件,然后以该硬件为目标来编写代码。要学习的主要内容是编写什么样的 C++ 代码。
通过转向使用 C++ 的 HLS 流程来开发 VP9 G2 硬件,团队获得了以下好处:
1. 一个包含 14 个模块设计的总代码行数约为 69,000。硬件设计团队估计,要描述相同的模块,基于 RTL的方法将需要大约 300,000 行代码。
2. C++ 仿真运行比 RTL 快 50 多倍。这大大减少了验证工作的跟踪需求,开发人员可以整天编写代码,晚上离开后开始进行回归处理,第二天早上获得套件中每项测试的结果。
3. 使用 C++ 实现了 IP 协作,允许多个贡献者共享对同一文件的改进,并支持标准工具和流程来合并更改。
4. HLS 可以在大约一个小时内处理完每个模块。因此,通过修改 C 代码或改变工具的约束,可以快速完成对模块不同架构的探索。设计和验证硬件的总工作量大约为六个月,而用 RTL 手动编写代码预计需要一年。
使用 CATAPULT HLS 流程
实现 G2 VP9 解码器 IP 的示例
帧间预测模块是 VP9 硬件中最复杂的部分之一。如图 1 显示,它是帧间/帧内预测模块的一部分。该模块负责计算连续视频帧之间的像素预测值。
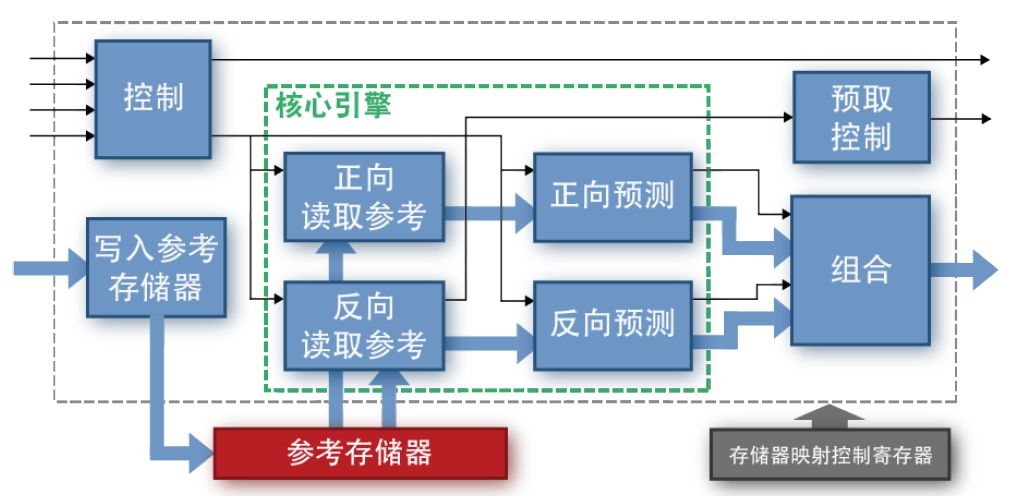
图 3. 帧间预测模块的高层次框图
如图 3 所示,帧间预测模块中有八个进程。该模块以三种方式进行控制。首先,使用存储器映射寄存器配置该模块。其次,将命令流发送到控制进程,然后控制进程向帧内预测模块中的核心引擎发出命令。
还有一个单独的预取控制进程会监视设计中参考存储器的状态,并预取新数据。最后,使用流控制握手功能将数据流送到“写入参考存储器”(Write Ref Mem) 进程。
一旦参考存储器中有足够的存储器可用,该架构便允许帧间预测模块预取数据。然后在正向和反向预测数据合并为一个输出流之前,控制核心 Ref 和 Pred 引擎尽可能快地处理数据。帧间预测模块随后将数据和命令转发到子系统中的下一模块,即去块滤波器。
在硬件中,各模块必须并行运行,速率常常不同。但是,源代码是顺序 C++,因此使用算法 C (AC) ac_channel数据类型来模拟模块之间的并行性和不同速率。以下代码是帧间预测模块的顶层源代码的简化版本。


帧间预测模块大约有 8000 行 C++ 代码,包括所有相关的头文件。设计的结构使用 ac_channel 和函数调用来描述,然后将每个函数映射到进程或其他级别的层次结构。ac_channel 的方向取决于 C 代码中如何使用它,Catapult 检查每个通道只有一个进程写入。
在 C++ 仿真中,ac_channel 是一个无限深度的 FIFO,支持简单的分层子系统仿真,就好像函数并行运行一样。然后在用 C++ 编写的完整子系统内部仿真源代码,以确认硬件和软件都正常工作。为了测试该模块,每个函数调用都包含一个循环,其迭代到所有输入数据都消耗完毕为止。
接下来,pred_inter 函数被综合为 RTL。在综合期间,函数转换为模块之间具有固定深度 FIFO 的并行进程。Catapult 为 RTL 生成 SystemC 封装器,以便可以使用原始测试环境来确认 RTL 是否正常运行。
然后,pred_inter 的 RTL 需要与其他生成的 RTL 模块集成,如图 2 所示。对于 VP9,这种集成是在 Verilog中手动完成。图 1 显示了此子系统中的模块以及用来连接它们的手工编码 FIFO。然后运行该子系统,使用的仿真向量与测试原始可综合 C++ 子系统所用的向量相同。
最后将 RTL 用于 FPGA 进行原型开发,或用于 ASIC 以完成最终实现。对于这两个目标,C++ 代码相同,因此 FPGA 原型开发可以轻松完成而不会牺牲最终 ASIC 实现的质量。
与 VP9 子系统的其余部分一样,该模块最初仅针对 VP9 开发,然后做了改进以支持 H.265。根据编译时转换,可以将整个子系统重新配置和重新优化为仅支持 VP9 或同时支持 VP9 与 H.265。
总结和结语
Catapult
与许多前沿硬件设计团队一样,WebM 硬件团队需要找到更好的办法来构建硬件。验证预计要占开发工作量的相当大一部分,而且硬件难以复用。最重要的是,这意味着团队没有足够的时间去构建最小、最快、功率效率最高的硬件。
现在,Google 工程师已完成第一个项目,他们学会了在编写可综合 C++ 的同时“看见硬件”。他们还学会了为特定类型的硬件编写什么样的代码。
-
模块
+关注
关注
7文章
2692浏览量
47422 -
编译
+关注
关注
0文章
656浏览量
32847 -
C代码
+关注
关注
1文章
89浏览量
14297
发布评论请先 登录
相关推荐
慧视高效压缩技术 解决多路视频传输难点

在米尔电子MPSOC实现12G SDI视频采集H.265压缩SGMII万兆以太网推流
在米尔电子MPSOC实现12G SDI视频采集H.265压缩SGMII万兆以太网推流
如何使用gzip压缩和解压缩技术
【米尔NXP i.MX 93开发板试用评测】2、异构通信环境搭建和源码编译
组态王播放视频注意事项
【RTC程序设计:实时音视频权威指南】音视频的编解码压缩技术
【米尔-瑞米派兼容树莓派扩展模块-试用体验】安装libmodbus
Python压缩和解压缩实现代码分享
vps服务器的linux怎么查看zip压缩包里的内容?
基于太空级Virtex FPGA建立高灵活性的可扩展架构
高性能无损数据解压缩FPGA IP,LZO无损数据解压缩IP
高性能无损数据压缩FPGA IP,LZO无损数据压缩IP
博途用户自定义库的使用-库的编辑及管理





 工商网监
工商网监
评论