 关于科大讯飞对新一代语音识别系统技术原理的分析和介绍
关于科大讯飞对新一代语音识别系统技术原理的分析和介绍

作为国内智能语音与人工智能产业领导者,科大讯飞在北京国家会议中心召开了以“AI复始,万物更新”为主题的2015年年度发布会。在发布会上,科大讯飞介绍了讯飞超脑计划的最新进展,并发布了数款让人印象深刻的创新型产品。特别值得一提的是,在发布会现场,科大讯飞全球首次将演讲人的演讲,同步转写成文字在大屏幕显示,敢于接受现场数千参会者和数千万观看视频直播观众的检验,系统的转写效果之好让大家直呼惊艳。此次发布会转写系统就是依托于讯飞全球领先的中文语音识别系统。今天,我们就为大家从技术上揭秘科大讯飞的新一代语音识别系统。
刘庆峰董事长现场演讲内容同步转写成文字显示在屏幕上
众所周知,自2011年微软研究院首次利用深度神经网络(Deep Neural Network, DNN)在大规模语音识别任务上获得显著效果提升以来,DNN在语音识别领域受到越来越多的关注,目前已经成为主流语音识别系统的标配。然而,更深入的研究成果表明,DNN结构虽然具有很强的分类能力,但是其针对上下文时序信息的捕捉能力是较弱的,因此并不适合处理具有长时相关性的时序信号。而语音是一种各帧之间具有很强相关性的复杂时变信号,这种相关性主要体现在说话时的协同发音现象上,往往前后好几个字对我们正要说的字都有影响,也就是语音的各帧之间具有长时相关性。
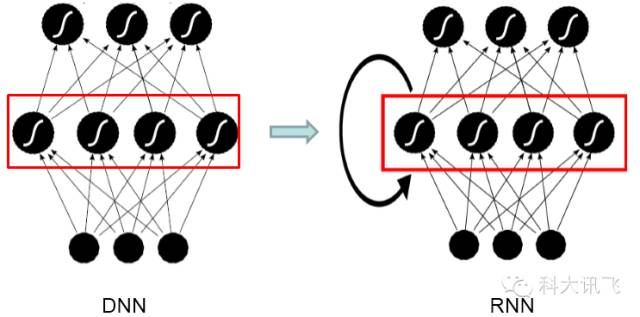
图1:DNN和RNN示意图
相比前馈型神经网络DNN,循环神经网络(Recurrent Neural Network, RNN)在隐层上增加了一个反馈连接,也就是说,RNN隐层当前时刻的输入有一部分是前一时刻的隐层输出,这使得RNN可以通过循环反馈连接看到前面所有时刻的信息,这赋予了RNN记忆功能,如图1所示。这些特点使得RNN非常适合用于对时序信号的建模,在语音识别领域,RNN是一个近年来替换DNN的新的深度学习框架,而长短时记忆模块(Long-Short Term Memory, LSTM)的引入解决了传统简单RNN梯度消失等问题,使得RNN框架可以在语音识别领域实用化并获得了超越DNN的效果,目前已经在业界一些比较先进的语音系统中使用。
除此之外,研究人员还在RNN的基础上做了进一步改进工作,图2是当前语音识别中的主流RNN声学模型框架,主要还包含两部分:深层双向LSTM RNN和CTC(Connectionist Temporal Classification)输出层。其中双向RNN对当前语音帧进行判断时,不仅可以利用历史的语音信息,还可以利用未来的语音信息,可以进行更加准确的决策;CTC使得训练过程无需帧级别的标注,实现有效的“端对端”训练。
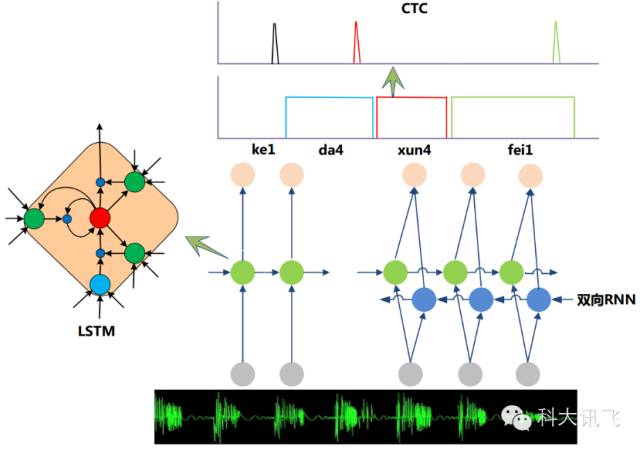
图2:基于LSTM RNN的主流声学模型框架
目前,国际国内已经有不少学术或工业机构掌握了RNN模型,并在上述某个或多个技术点进行研究。然而,上述各个技术点单独研究时一般可以获得较好的结果,但是如果想将这些技术点融合在一起的时候,则会碰到一些问题。例如,多个技术结合在一起的提升幅度会比各个技术点幅度的叠加要小。又例如,传统的双向RNN方案,理论上需要看到语音的结束(即所有的未来信息),才能成功的应用未来信息来获得提升,因此只适合处理离线任务,而对于要求即时响应的在线任务(例如语音输入法)则往往会带来3-5s的硬延迟,这对于在线任务是不可接受的。再者,RNN对上下文相关性的拟合较强,相对于DNN更容易陷入过拟合的问题,容易因为训练数据的局部不鲁棒现象而带来额外的异常识别错误。最后,由于RNN具有比DNN更加复杂的结构,给海量数据下的RNN模型训练带来了更大的挑战。
鉴于上述问题,科大讯飞发明了一种名为前馈型序列记忆网络FSMN(Feed-forward Sequential Memory Network)的新框架。在这个框架中,可以把上述几点很好的融合,同时各个技术点对效果的提升可以获得叠加。值得一提的是,我们在这个系统中创造性提出的FSMN结构,采用非循环的前馈结构,在只需要180ms延迟下,就达到了和双向LSTM RNN相当的效果。下面让我们来具体看下它的构成。
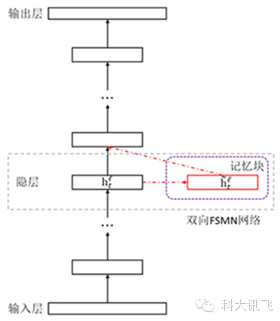
图3:FSMN结构示意图
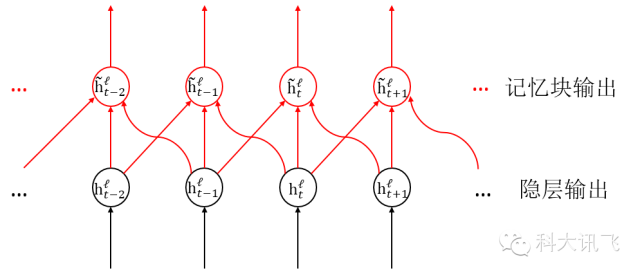
图4:FSMN中隐层记忆块的时序展开示意图(左右各看一帧)
图3即为FSMN的结构示意图,相比传统的DNN,我们在隐层旁增加了一个称为“记忆块”的模块,用于存储对判断当前语音帧有用的历史信息和未来信息。图4画出了双向FSMN中记忆块左右各记忆一帧语音信息(在实际任务中,可根据任务需要,人工调整所需记忆的历史和未来信息长度)的时序展开结构。
从图中我们可以看出,不同于传统的基于循环反馈的RNN,FSMN记忆块的记忆功能是使用前馈结构实现的。这种前馈结构有两大好处:首先,双向FSMN对未来信息进行记忆时,没有传统双向RNN必须等待语音输入结束才能对当前语音帧进行判断的限制,它只需要等待有限长度的未来语音帧即可,正如前文所说的,我们的双向FSMN在将延迟控制在180ms的情况下就可获得媲美双向RNN的效果;其次,如前所述,传统的简单RNN因为训练过程中的梯度是按时间逐次往前传播的,因此会出现指数衰减的梯度消失现象,这导致理论上具有无限长记忆的RNN实际上能记住的信息很有限,然而FSMN这种基于前馈时序展开结构的记忆网络,在训练过程中梯度沿着图4中记忆块与隐层的连接权重往回传给各个时刻即可,这些连接权重决定了不同时刻输入对判断当前语音帧的影响,而且这种梯度传播在任何时刻的衰减都是常数的,也是可训练的,因此FSMN用一种更为简单的方式解决了RNN中的梯度消失问题,使得其具有类似LSTM的长时记忆能力。
另外,在模型训练效率和稳定性方面,由于FSMN完全基于前馈神经网络,所以不存在RNN训练中因mini-batch中句子长短不一需要补零而导致浪费运算的情况,前馈结构也使得它的并行度更高,可最大化利用GPU计算能力。从最终训练收敛的双向FSMN模型记忆块中各时刻的加权系数分布我们观察到,权重值基本上在当前时刻最大,往左右两边逐渐衰减,这也符合预期。进一步,FSMN可和CTC准则结合,实现语音识别中的“端到端”建模。
最后,和其他多个技术点结合后,讯飞基于FSMN的语音识别框架可获得相比业界最好的语音识别系统40%的性能提升,同时结合我们的多GPU并行加速技术,训练效率可达到一万小时训练数据一天可训练收敛。后续基于FSMN框架,我们还将展开更多相关的研究工作,例如:DNN和记忆块更深层次的组合方式,增加记忆块部分复杂度强化记忆功能,FSMN结构和CNN等其他结构的更深度融合等。在这些核心技术持续进步的基础上,科大讯飞的语音识别系统将不断挑战新的高峰!
-
语音识别
+关注
关注
39文章
1825浏览量
116240 -
深度学习
+关注
关注
73文章
5608浏览量
124637
发布评论请先 登录
科大讯飞设立子公司:加码AI与集成电路业务布局
2025科大讯飞全球1024开发者节精彩回顾
香港立法会与科大讯飞联合打造智慧誊录系统“智识听”
铁路车号识别系统的基本原理与应用

无人机AI视觉行为识别系统

回顾科大讯飞26周年庆精彩瞬间





评论