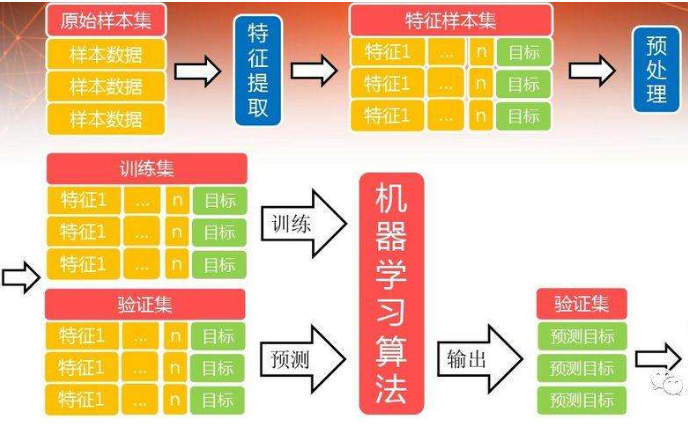
 简述大数据的半监督声学模型训练操作方法
简述大数据的半监督声学模型训练操作方法
以下研究成果来自“云知声—上海师范大学自然人机交互联合实验室”。
目前,深度学习已经在机器学习应用的各个领域取得了非常出色的表现,其成功在很大程度上取决于大数据和与之匹配的计算能力。深度学习的特性决定了它需要很多的数据进行学习,从而得出模型来完成特定任务,比如,大词汇量连续语音识别上的成功就取决于海量的用于声学模型(acoustic model, AM) 训练的带标注的语料库,借助GPU集群,使得深度学习算法和数据得到高效完美的结合,从而带来了语音识别性能的显著提升,也推动了语音识别技术的实际产品落地。
通常,我们把需要在大量带标注的语料库上进行的声学模型训练称为“有监督的AM训练”。然而,众所周知,用人工来标注大量的数据来训练语音识别系统的代价非常大,需要耗费大量的人力和财力,同时还伴随着高昂的时间成本,繁琐的校验流程。因此,无监督或半监督AM训练成为当前语音识别的研究前沿和热点。下面借用顶级语音专家、腾讯AI Lab杰出科学家俞栋老师的话(顶级语音专家、MSR首席研究员俞栋:语音识别的四大前沿研究)简单科普一下有监督,半监督和无监督学习的区别。
“有监督学习是比较 well-defined,有比较明确的任务。目前来讲,深度学习对这一类问题效果比较好。无监督学习的目的是要寻找数据中的潜在规律。很多情况下,它试图寻找某种特征变换和相对应的生成模型来表达原始数据。但无监督学习不仅本身困难,对无监督学习系统的评价也很难。原因是通过无监督学习找到的规律不一定对你将来的任务有帮助,或者它对某一任务有帮助,换一个任务就没有帮助了。半监督学习介于两者中间。因为你已经有一部分标注信息了,所以你的任务是明确的,不存在不知如何评估的问题。”
目前,在语音识别的声学模型无监督学习方面,工业界和学术界的想法都不少,但尚未有成功的案列。我们知道,在有大量标注数据集的前提下,最新的有监督模型总是表现得比无监督训练模型更好。但鉴于有监督模型训练所需的高昂成本,因此,如何充分利用少量的带标注数据来挖掘大量无标注数据中的有用信息的半监督AM学习受到研究者的关注。
下面是我们在借鉴传统语音识别半监督AM训练算法的基础上,提出的半监督AM学习方案:

图1. Unisound半监督AM学习架构图
传统的半监督AM学习大多是基于GMM-HMM的self-training的学习方式, 即用来对无标注数据进行解码的种子模型与目标模型相同。自深度学习成功引入到语音识别中以来,虽然也出现了其他算法,但目前仍然以self-training思想为主流。然而,我们知道,通过self-training方式获得的可用无标注数据容易存在与训练种子模型(seed model) 的人工标注数据“同质”的问题,最终通过这种半监督方式训练的AM获得的收益远远低于我们的预期。另外,由于训练数据量的大大增加,使得AM训练时所需的计算资源也相应增加。
因此,如图1所示,我们提出采用多种子模型并行解码的策略,这种策略可充分挖据海量无监督数据中的有用信息,在很大程度上避免self-training方法带来的数据同质问题。由于各种子模型采用不同的声学模型结构,且所用种子模型的结构与最后半监督的AM结构也不同,这些种子模型能从多个不同角度学习到海量无标注数据的特性,从而使得从无标注数据中挑选出来的可用数据与人工标注数据之间存在很强的互补特性,最终体现在半监督AM模型性能上。如最终AM结构为CNN+LSTM+DNN (convolutional, long short-term memory, deep neural network) 的级联结构,那么种子模型可选用TDNN (time delay neural network), E2E (end-to-end system), DNN-HMM (deep neural network, hidden Markov model), RNN-BLSTM (recurrent neural network with bidirectional long short-term memory) 的声学模型结构。
通过种子模型对无标注数据解码获得标注后,如何从这些海量数据中挑选出有用的数据一直是半监督AM学习中的一个难题。我们除了在语音帧层面采用多种子模型解码结果投票策略之外,还在多种子模型解码lattice层面进行了confidence calibration,以在自动标注质量(ASR decoding结果) 和数据的有用性(informative)方面取得好的平衡为目标函数进行自动数据挑选(data filtering)。
另外,我们在大量实验中发现,海量的无标注语音数据中,不同来源的数据都有其自身的音频属性,比如带口音,低信噪比,合成语音等等,不同属性的音频添加到AM模型训练数据集中会严重影响最终AM特性,从而影响其在不同测试集合上的泛化能力。因此,我们提出通过在无标注数据集上设计合适开发集(development data),结合多种子模型并行解码的策略来自动获取无监督音频数据的属性(unlabeled data properties), 然后将这些音频属性作为“正则化项”加入到最终声学模型训练的目标函数中,有效指导最终AM的训练。
采用如图1的半监督AM学习架构,我们在大词汇量中英文混合连续语音识别任务上,当人工标注语音数据量为1000小时,通过我们的半监督学习方法从无标注语音中挑选出1000小时加入到人工标注训练数据集合中,实验结果表明,在测试集合上能获得15% 的字/词错误率(word error rate, WER)的相对降低。当人工标注语音数据量增加到数万小时时,加入我们半监督AM学习方法挑出的大量语音后,WER仍然有约5% 的相对降低。
特别值得一提的是,我们针对各种训练集合和测试集合做过大量实验,发现若通过半监督学习获取的大量无标注数据的音频属性与测试集合接近,那么最终训练出的AM在该测试集合上就能取得非常大的收益,相比整体测试集上 5% 的相对 WER 降低,在车载导航和音乐相关的测试集合上能够获取12% 左右的相对WER降低。这间接说明了无标注数据音频属性的重要性,同时也说明,在无标注数据属性指导下的半监督学习方法能通过灵活调整其目标函数的正则化项来达到我们的预期目标,使得训练出来的AM能灵活适应于各种不同的应用场合。
-
语音识别
+关注
关注
38文章
1768浏览量
113456 -
人工智能
+关注
关注
1801文章
48218浏览量
243095 -
大数据
+关注
关注
64文章
8929浏览量
138599
发布评论请先 登录
相关推荐
【大语言模型:原理与工程实践】大语言模型的预训练
简述二氧化硫试验机的操作方法
Pytorch模型训练实用PDF教程【中文】
如何约束半监督分类方法的详细资料概述
半监督学习最基础的3个概念
基于主动学习的半监督图神经网络模型来对分子性质进行预测方法
基于特征组分层和半监督学习的鼠标轨迹识别方法
基础模型自监督预训练的数据之谜:大量数据究竟是福还是祸?






 工商网监
工商网监
评论