 AI新兴应用通过带可配置加速的片上系统器件来满足严格性能、效率需求
AI新兴应用通过带可配置加速的片上系统器件来满足严格性能、效率需求
随着智能安全、机器人或无人驾驶汽车等应用越来越依靠嵌入式人工智能技术来提高性能,交付全新的用户体验,传统计算平台上的推断引擎很难在有限的功耗、时延和物理尺寸限制下满足实际要求。推断引擎必须满足严格定义的推断精度,还受限于总线宽度,而且存储器难以为最佳速度、效率和芯片面积进行调整优化。我们需要灵活应变的计算平台来满足运行一流卷积神经网络 (CNN) 的嵌入式 AI 的要求。
放眼未来,适应于更多前沿神经网络的灵活性是我们的主要关注点。今天广受欢迎的 CNN 正加速被新型的先进架构所取代。然而,传统的 SoC 设计要使用当前的神经网络架构知识,从开发开始到未来部署通常需要大约三年时间。RNN 或 Capsule Network 等新型神经网络可能会让传统 SoC 变得低效,也难以提供保持竞争力所需的性能。
嵌入式 AI 要满足最终用户期望,特别是要跟上可预见的未来不断提升的需求,就必须采用更加灵活的自适应计算平台。我们可利用用户可配置的多核片上系统 (MPSoC) 器件,整合主应用处理器和可扩展的可编程逻辑结构,包含可配置的存储器架构和满足可变精度推断所需的信号处理技术,从而满足上述要求。
推断精度
在传统的 SoC 中,决定性能的特性如存储器架构和计算精确度等是固定的。最小值通常为 8 位,由核心 CPU 定义,不过就给定的算法而言最佳精度可能更低。MPSoC 支持可编程逻辑优化至晶体管层面,这就能根据需要让推断精度降低到 1 位。此外,这类器件还包含成千上万可配置的 DSP slice,能高效处理乘积累加 (MAC) 计算。
能自由优化推断精度,根据平方律提供刚好满足需求的计算效率,也就是说单位的运算用 1 位核心执行,相对于用 8 位核心完成相同计算而言,所需的逻辑仅为 1/64。此外,MPSoC 能让推断精度针对神经网络的每层做出不同优化,从而以最大的效率提供所需的性能。
存储器架构
除了通过改变推断精度来提高计算效率之外,配置可编程片上存储器的带宽和结构能进一步提高嵌入式 AI 的性能和效率。定制 MPSoC 相对于运行相同推断引擎的传统计算平台而言,片上存储器可能达到 4 倍多,存储器—接口带宽可能达到 6 倍。存储器的可配置性使得用户能减少瓶颈,并优化芯片资源的利用率。此外,典型的子系统只有有限的片上集成高速缓存,必须与片外存储设备频繁交互,这就会增加时延和功耗。在 MPSoC 中,大多数存储器交换都在片上进行,这就会大幅提高速度,而且相对于片外存储器交互而言功耗降低超过 99%。
芯片面积
解决方案的尺寸也越来越重要,特别就采用移动 AI 的无人机、机器人或无人/自动驾驶汽车而言尤其如此。MPSoC 的 FPGA 结构上实现的推断引擎可能仅占用传统 SoC 八分之一的芯片面积,这就能让开发人员在更小的器件中构建功能更强大的引擎。
此外,MPSoC 器件系列为设计人员提供了实现推断引擎的丰富选择,能支持最节能、成本效率最高、面积占用最小的方案,从而满足系统性能要求。一些通过汽车应用认证的部件具备硬件功能安全特性,达到业界标准的 ISO 26262 ASIL-C 安全规范,这对自动驾驶应用而言至关重要。比如赛灵思的 Automotive XA Zynq UltraScale+ 系列采用 64 位四核 ARM Cortex-A53 和双核 ARM Cortex-R5 处理系统以及可扩展的可编程逻辑结构,这就能在单个芯片上整合控制处理、机器学习算法和安全电路,同时提供故障容错功能。
今天,嵌入式推断引擎可用单个 MPSoC 器件实现,功耗低至 2 瓦,这对移动机器人或自动驾驶汽车而言都是比较合适的功耗水平。传统计算平台即便现在也无法用这么低的功耗运行实时 CNN 应用,未来也不太可能在更严格的功耗限制条件下满足更快响应和更复杂功能的日益严格的要求。基于可编程 MPSoC 的平台能够提供更高的计算性能,更高的效率,也能在 15瓦以上的功率水平下减小面积和减轻重量。
如果开发人员不能在自己的项目中轻松地实现这些优势,那么这种可配置型多平行计算架构的优势就仅限于学术领域。成功需要适当的工具来帮助开发人员优化目标推断引擎的实现。为了满足有关需求,赛灵思不断扩展开发工具生态系统和机器学习软件堆栈,并与专业合作伙伴合作,一起简化和加速计算机视觉和视频监控等应用的实现。
面向未来的灵活性
利用 SoC 的可配置性为手头应用创建最佳平台,也使得 AI 开发人员能够灵活地跟上神经网络架构快速发展演进的要求。业界可能迁移到新型神经网络的可能性,对于平台开发人员来说是一个巨大的风险。可重配置的 MPSoC 通过重配置并用当前最先进的策略来构建最高效的处理引擎,能够让开发人员灵活地响应神经网络架构方式的变化。
AI 越来越多地嵌入到各种设备中,包括工业控制、医疗设备、安全系统、机器人和自动驾驶汽车等。利用可编程逻辑结构的 MPSoC 器件的灵活应变加速技术,是提供保持竞争力所需的快速响应和高级功能的关键。
-
赛灵思
+关注
关注
32文章
1794浏览量
131144 -
AI
+关注
关注
87文章
29928浏览量
268242
原文标题:灵活应变的加速是将人工智能从云端带到边缘的关键
文章出处:【微信号:FPGA-EETrend,微信公众号:FPGA开发圈】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
严格的性能测试确保连接器可满足复杂环境的应用需求
risc-v多核芯片在AI方面的应用
什么是可编程片上系统?PSOC和FPGA的区别
可编程片上系统是什么
片上系统的组成
片上系统是什么意思
Hitek Systems开发基于PCIe的高性能加速器以满足行业需求

TPS650864可配置多轨PMU适用于多核处理器、FPGA和系统的TPS650861可配置多轨PMU数据表

台积电大幅上调SoIC产能规划,以满足未来AI、HPC的强劲需求
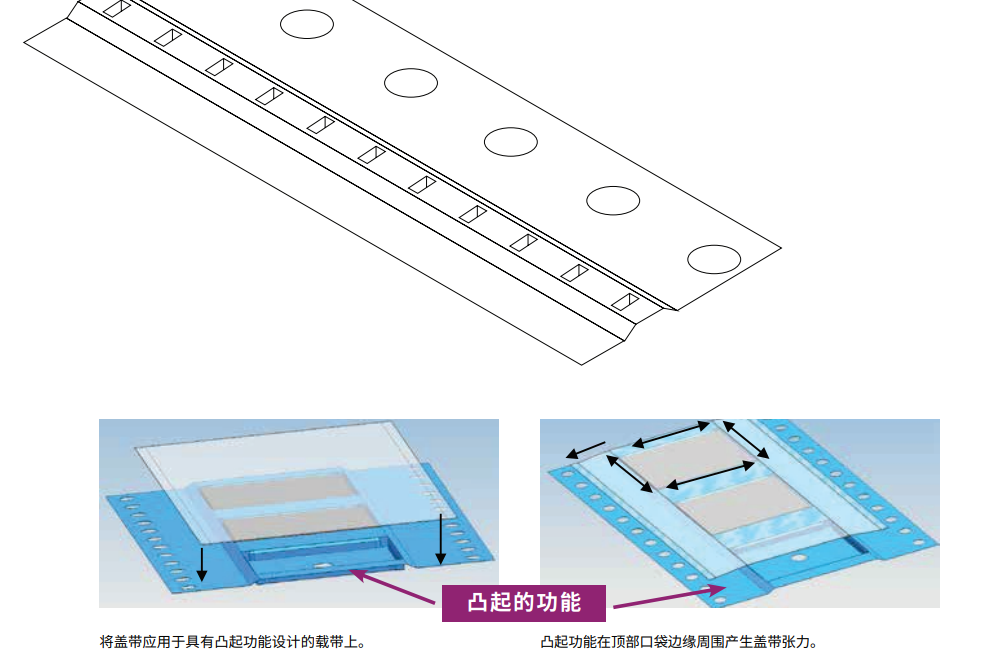
满足特殊要求的定制化载带设计
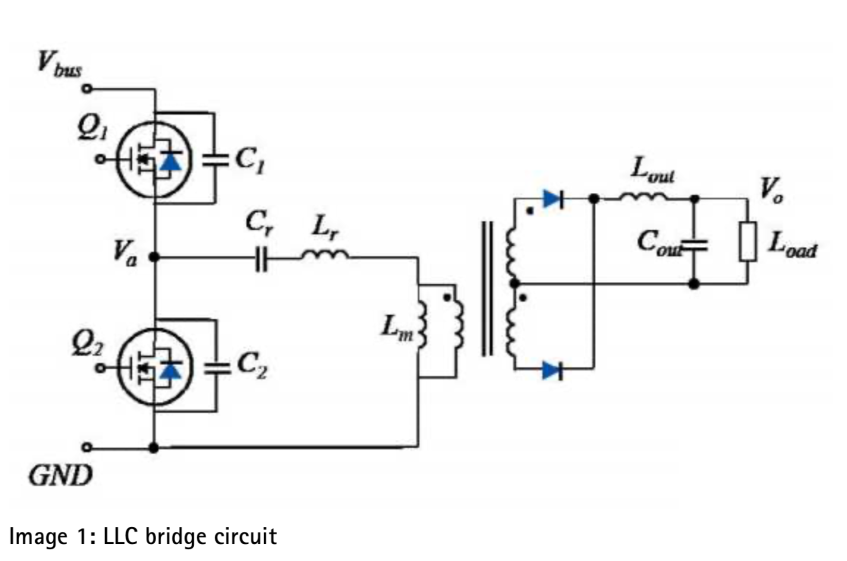
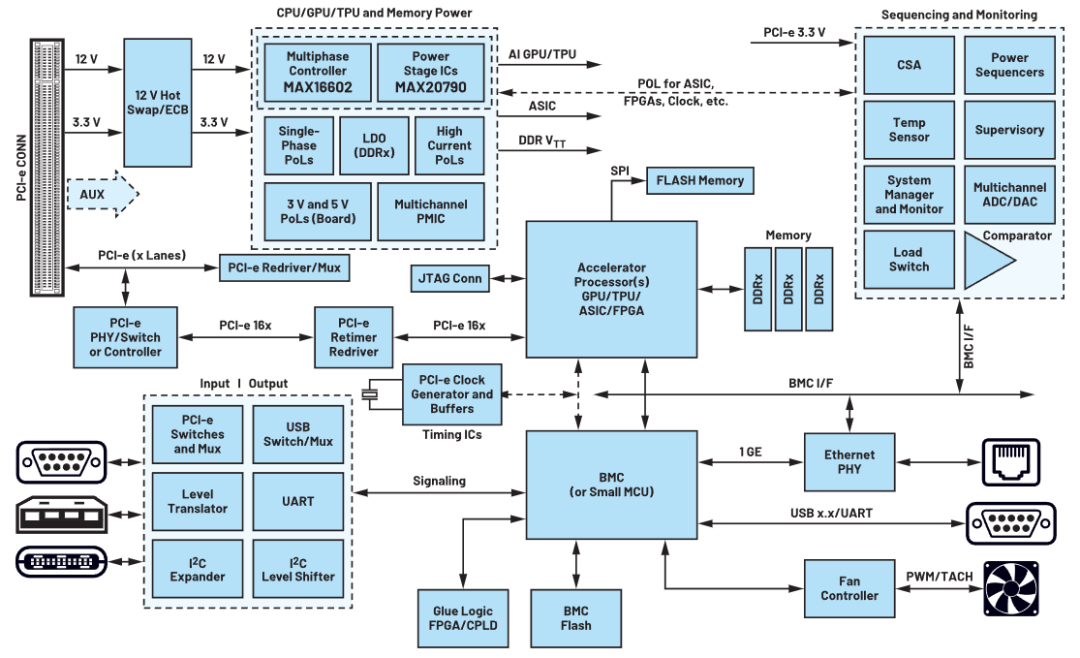
瞬变对AI加速卡供电的影响





 工商网监
工商网监
评论