 NVIDIA GPU再创壮举,距真正会话AI又进一步!
NVIDIA GPU再创壮举,距真正会话AI又进一步!
会话 AI 服务已经存在多年,但不论是聊天机器人,还是智能个人助理或搜索引擎,其理解能力很难达到与人类相当的水平。主要瓶颈则在于超大型AI模型的实施部署无法实现。正因如此,不论是Google、Microsoft、Facebook,还是阿里巴巴、百度等,都在模型的部署方面孜孜以求。
NVIDIA于太平洋时间8月13日宣布重大突破:BERT训练时间实现创纪录的53分钟,推理时间缩短至2毫秒,并构建了迄今为止同类型中最大的语言模型,使得实时会话 AI与用户进行互动时更为自然。
超大模型面前,GPU再证强大可扩展性
BERT(Bidirectional Encoder Representations from Transformers)是世界上最先进的AI语言模型之一,Google于去年发布不久就刷爆AI业界。作为一种新型的语言模型,它只需一个额外的输出层对预训练BERT进行微调就可以满足各种任务,而无需再对模型进行修改,实现了在11项NLP任务上取得突破进展。在对BERT模型进行训练时,NVIDIA使用搭载了92台 NVIDIA DGX-2H系统的 NVIDIA DGX SuperPOD运行该模型的大型版本,凭借1472个NVIDIA V100 GPU的强大性能,NVIDIA将BERT-Large的典型训练时间从几天缩短至仅仅 53 分钟。
此外,NVIDIA还在单独一台NVIDIA DGX-2系统上执行了BERT-Large 模型的训练任务,用时也仅为 2.8天,充分体现了GPU在会话 AI 方面的可扩展性。
推理方面,借助于运行了NVIDIA TensorRT的NVIDIA T4 GPU,NVIDIA 执行 BERT-Base SQuAD数据集的推理任务,用时仅为2.2毫秒,远低于许多实时应用程序所需的10毫秒处理阈值;与使用高度优化的CPU代码时所测得的40多毫秒相比,有着显著改进。
对此,NVIDIA 深度学习应用研究副总裁 Bryan Catanzaro 表示,“对于适用于自然语言的AI而言,大型语言模型正在为其带来革新。NVIDIA 所取得的突破性工作成果加速了这些模型的创建,它们能够帮助解决那些最为棘手的语言问题,让我们距离实现真正的会话 AI 更进了一步。
NVIDIA BERT推理解决方案Faster Transformer宣布开源
开发者们对于更大模型的需求正在日益增长,NVIDIA 研究团队基于Transformer构建并训练了世界上最大的语言模型。Transformer是BERT的技术构件,正被越来越多的其他自然语言AI模型所使用。NVIDIA定制的模型包含83亿个参数,是BERT-Large的24 倍。2017年12月Google在论文“Attention is All You Need”中首次提出了Transformer,将其作为一种通用高效的特征抽取器。至今,Transformer已经被多种NLP模型采用,比如BERT以及上月发布重刷其记录的XLNet,这些模型在多项NLP任务中都有突出表现。在NLP之外,TTS、ASR等领域也在逐步采用Transformer。可以预见,Transformer这个简洁有效的网络结构会像CNN和RNN一样被广泛采用。
不过,虽然Transformer在多种场景下都有优秀表现,但是在推理部署阶段,其计算性能却受到了巨大的挑战:以BERT为原型的多层Transformer模型,其性能常常难以满足在线业务对于低延迟(保证服务质量)和高吞吐(考虑成本)的要求。以BERT-BASE为例,超过90%的计算时间消耗在12层Transformer的前向计算上。因此,一个高效的Transformer 前向计算方案,既可以为在线业务带来降本增效的作用,也有利于以Transformer结构为核心的各类网络在更多实际工业场景中落地。
NVIDIA GPU计算专家团队针对Transformer推理提出的性能优化方案Faster Transformer宣布开源,其底层基于CUDA和cuBLAS,是一个BERT Transformer 单层前向计算的高效实现,其代码简洁明了,后续可以通过简单修改支持多种Transformer结构。目前优化集中在编码器(encoder)的前向计算(解码器decoder开发在后续特性规划中),能够助力于多种BERT的应用场景。Faster Transformer对外提供C++ API,TensorFlow OP 接口,以及TensorRT插件,并提供了相应的示例,用以支持用户将其集成到不同的线上应用代码中。
2021年15%的客服互动将通过AI完成
预计未来几年,基于自然语言理解的 AI 服务将呈指数级增长。根据Juniper Research 的研究表明,在未来4年中,仅数字语音助手的数量就将有望从25 亿攀升到 80 亿。此外,据Gartner预计,到 2021 年,15%的客服互动都将通过AI完成,相比2017年将增长4倍。当前,全球数以百计的开发者都使用 NVIDIA 的 AI 平台,来推进他们自己的语言理解研究并创建新的服务。
Microsoft Bing正在通过先进的 AI 模型和计算平台,为客户提供更好的搜索体验。通过与 NVIDIA 密切合作,Bing 使用 NVIDIA GPU(Azure AI 基础设施的一部分)进一步优化了热门自然语言模型 BERT 的推理功能,从而大幅提升了 Bing 于去年部署的排名搜索的搜索质量。与基于 CPU 的平台相比,使用 Azure NVIDIA GPU 进行推理,延迟降低了一半,吞吐量提升了5倍。
多家初创公司(例如Clinc、Passage AI 和Recordsure等)正在使用 NVIDIA的AI平台为银行、汽车制造商、零售商、医疗服务提供商、旅行社和酒店等客户构建先进的会话 AI 服务。据悉,中国市场也有相应的合作伙伴,日后将进一步公开。
会话AI才是真正意义上的人工智能的基本特征,不论是语言模型还是训练、推理,底层技术的逐步强大,才是实现这一切的基础。距离我们所期望的人工智能虽然还很遥远,但技术上的每一次突破都值得记载。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
NVIDIA
+关注
关注
14文章
5104浏览量
104420 -
gpu
+关注
关注
28文章
4828浏览量
129763
发布评论请先 登录
相关推荐
三星携Galaxy AI和以软件为中心的网络技术亮相MWC 2025,进一步强化移动AI领先优势
3月3日-6日,世界移动通信大会(MWC2025)在巴塞罗那 Fira Gran Via展馆举行。本次大会上,三星电子进一步创新移动AI体验,三星移动业务和网络业务部门在现场展示了旗下包括下一


NVIDIA推出多个生成式AI模型和蓝图
NVIDIA 宣布推出多个生成式 AI 模型和蓝图,将 NVIDIA Omniverse 一体化进一步扩展至物理
GPU服务器AI网络架构设计
众所周知,在大型模型训练中,通常采用每台服务器配备多个GPU的集群架构。在上一篇文章《高性能GPU服务器AI网络架构(上篇)》中,我们对GPU

英特尔将进一步分离芯片制造和设计业务
面对公司成立50年来最为严峻的挑战,英特尔宣布了一项重大战略调整,旨在通过进一步分离芯片制造与设计业务,重塑竞争力。这一决策标志着英特尔在应对行业变革中的坚定步伐。

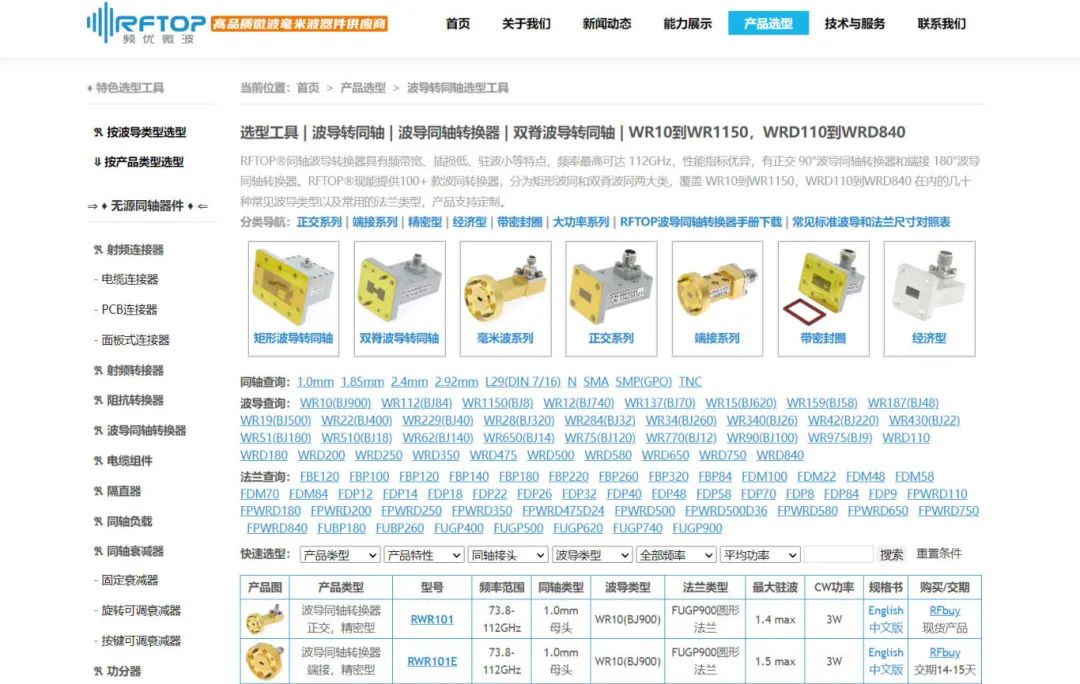
RFTOP进一步扩充波导同轴转换器产品线
近日高品质微波毫米波器件供应商RFTOP(频优微波)进一步扩充波导同轴转换器产品线,新增了同轴公头全系列新品,覆盖1.0mm、1.85mm、2.4mm、2.92mm、SMA、SMP等同轴公头,涵盖
iPhone 15在美国市场需求进一步减弱
7月19日,国际媒体披露了市场研究机构CIRP的最新报告,揭示了iPhone 15系列在美国市场的受欢迎程度相较于前代iPhone 14系列有所下滑。这一趋势在CIRP最新发布的第二季度数据中得到了进一步印证,显示iPhone 15系列的市场需求正经历持续放缓。
西门子与微软进一步扩展战略合作关系
近日,西门子数字化工业软件与微软宣布进一步扩展双方的战略合作关系。通过微软Azure云服务,西门子正式推出Xcelerator as a Service工业软件解决方案,为客户提供更灵活、高效的服务体验。
进一步解读英伟达 Blackwell 架构、NVlink及GB200 超级芯片
NVIDIA NVLink Switch系统和铜电缆盒密集连接GPU,优化并行模型效率,液冷设计进一步降低能耗。全新的第五代NVLink在单个域中可连接多达576个GPU,带宽超过1P
发表于 05-13 17:16
卓驭科技与高通合作宣布进一步推动汽车行业智能驾驶技术的发展
今日,深圳市卓驭科技有限公司(以下简称:卓驭科技)与高通技术公司宣布扩展双方的技术合作,利用基于Snapdragon Ride平台的全新智能驾驶产品,进一步推动汽车行业智能驾驶技术的发展。

安霸发布5nm制程的CV75S系列芯片,进一步拓宽AI SoC产品路线图
防展(ISC West)期间发布 5nm 制程的 CV75S 系列芯片,进一步拓宽其 AI SoC 产品路线图。
TDK进一步扩充Micronas嵌入式电机控制器系列HVC 5x
TDK 株式会社(TSE:6762)进一步扩充 Micronas 嵌入式电机控制器系列 HVC 5x,完全集成电机控制器与 HVC-5222D 和 HVC-5422D,以驱动小型有刷(BDC)、无刷(BLDC)或步进电机。
Arbe在中国上海设立分公司,进一步增强企业影响力
摘要:中国团队将进一步促进Arbe与中国市场重要企业之间的紧密合作。 新一代4D成像雷达解决方案的头部企业Arbe Robotics(纳斯达克股票代码:ARBE;以下称Arbe)近日宣布已在上海设立





 工商网监
工商网监
评论