 摩尔定律正在放缓 大型芯片公司方向或发生重大转变
摩尔定律正在放缓 大型芯片公司方向或发生重大转变
为什么Intel,AMD,Arm和IBM专注于架构,微体系结构和功能变化。
大型芯片制造商正在转向芯片组等架构改进,片上和片外更快的吞吐量,以及每个操作或周期集中更多工作,以提高处理速度和效率。
总的来说,这代表了主要芯片公司方向的重大转变。他们所有人都在努力应对处理需求的大幅增加以及传统方法无法提供足够的改进能力,性能和面积。自28nm以来,缩放的好处一直在减少,在某些情况下还要好。与此同时,从新设备,新应用程序和各地传感器的大量增加中收集的数据越来越多,需要使用相同或更低的功率更快地处理。
对于芯片制造商来说,这相当于一场完美的风暴,过去他们利用投机执行等方法来增加扩展的好处。但是,投机性执行已被证明会产生安全漏洞,只是缩小的功能不再能使功率和性能提高30%到50%。今天的数字接近20%,甚至需要新的材料和结构。
与此同时,大型芯片制造商看到谷歌,亚马逊和Facebook等公司纷纷跨界其主要市场——巨型数据中心。此外,它们正在人工智能 / 机器学习市场中受到挑战,并且在一些初创公司开发专门的加速器方面受到挑战,这些加速器通过架构变化有望实现数量级的改进。
最大的芯片制造商开始接受它,而不是试图对抗这种趋势。例如,AMD推出了Zen 2架构,它依赖于由它们和其他人制造的芯片组合——高速芯片到芯片互连和可以调整的优先级方案,以便数据可以更快地移动到一个方向或其他。
AMD首席架构师Dan Bouvier在半导体芯片大会上表示,小型芯片可以提高产量。但他指出,通过使用通用互连并将所有这些组件放在基板上,小芯片也可用于将芯片尺寸增加到1000平方毫米,这大于光罩尺寸。该互连还可用于连接在不同工艺节点上开发的芯片,具体取决于对特定功能最有意义的内容。
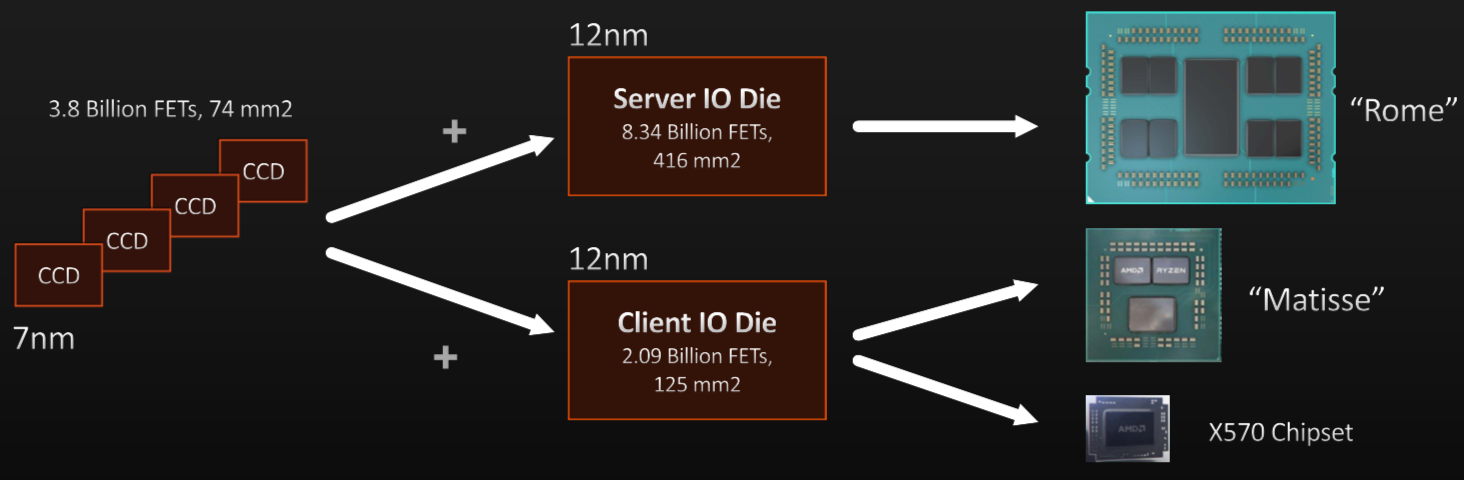
图1:AMD的芯片架构。资料来源:AMD
英特尔的战略也很大程度上依赖于芯片,它通过各种方法连接,包括内部开发的芯片到芯片桥(嵌入式多芯片互连桥或EMIB)。但该公司也一直在研究内存访问和存储问题。该解决方案的一部分涉及持久存储器,这有助于弥合DRAM和固态驱动器之间的差距。
一段时间以来,英特尔一直在发布一种称为3D XPoint的持久存储器类型。基于相变存储器技术,英特尔在其自己的SSD和DIMM中集成了3D XPoint设备,从而加速了这些系统中的操作。
英特尔高级首席工程师Lily Looi说:“最大的挑战之一就是你已经获得了所有需要处理的数据,但你的空间有限。” “在过去的几年里,数据爆炸式增长,有两件事情发生了变化。首先,纳秒很重要,因此您需要更多容量。第二件事是您需要一个持久性功能,以便在关闭电源时数据仍然存在。但是您不必保存所有数据。您可能只需要保存一个块甚至几千字节的数据,这样效率会更高。”
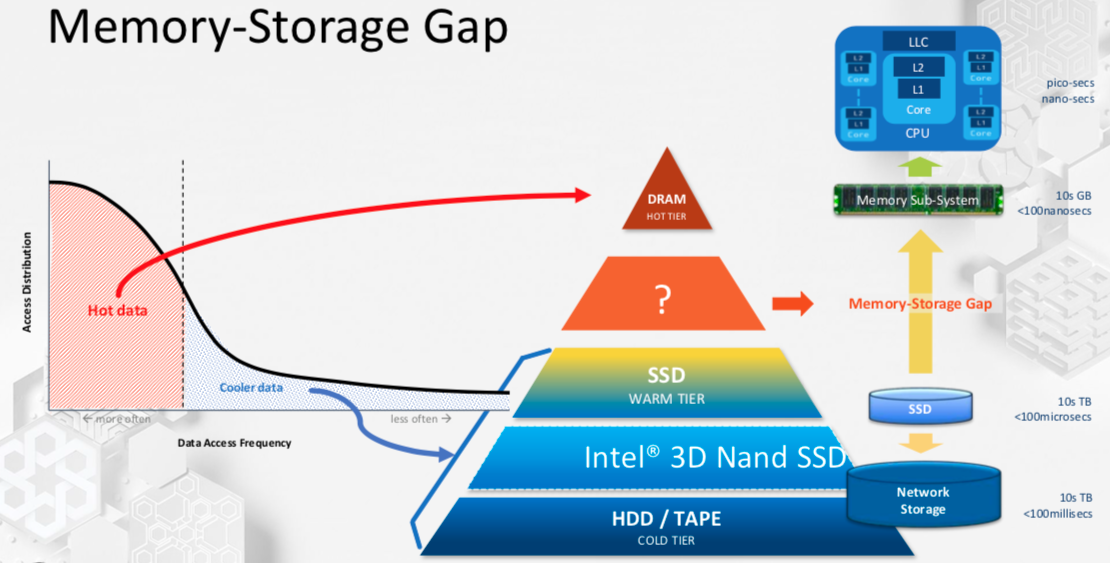
图2:存储指数级数据的位置。资料来源:Intel
更智能的权衡
更大的芯片和更快的互连并不是实现更好性能的唯一途径。
例如,Arm推出了它的Neoverse N1架构,它显着提高了分支预测的准确性——基本上相当于搜索中的预取。Arm还继续推动以更低的功耗做更多事情,通过连贯的网状网络将IP磁贴连接在一起,允许根据特定应用的需要调整处理器的大小。
Arm的战略关键是更大的2级缓存和上下文切换,Arm的高级首席工程师Andrea Pellegrini 说,它比以前的方法快2.5倍。“我们也看到分支误差预测减少了7倍,”他说。Arm还专注于通过降低缓存未命中率来减少其指令占用率,Pellegrini表示已降低1.4倍。与此同时,L2访问量下降了2.25倍。
这是查看处理器效率和每瓦性能的另一种方式。虽然大多数处理器公司从在相同功率预算下做得更多的角度来处理它,但其他公司正在考虑用更少的功率做更多的事情,这在带电池的设备中很重要。这包括智能手机,但它也包括为电动汽车和机器人开发的芯片。
Arm还将使用其网状网络方法添加为特定数据类型定制的第三方加速器。
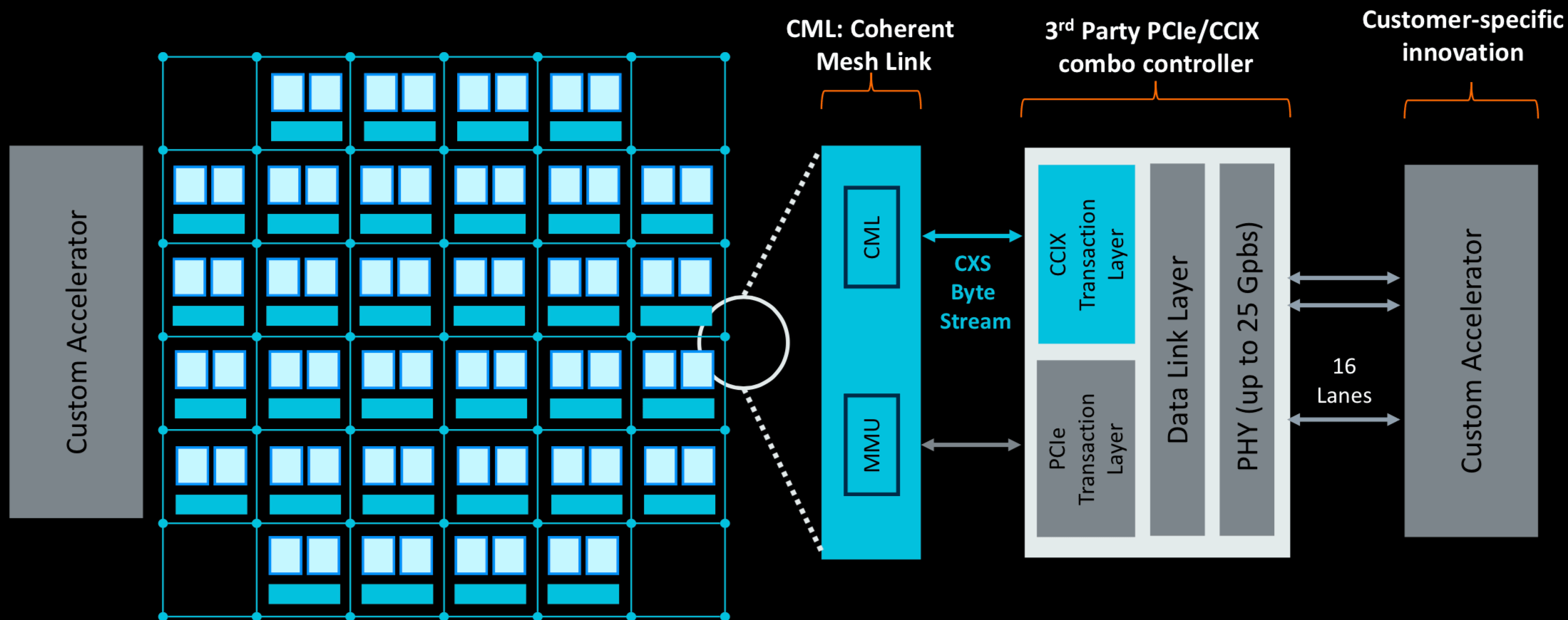
图3:Arm的可定制Neoverse架构。资料来源:Arm
与此同时,IBM推出了一种既简单又非常不同的架构。IBM的目标之一是假设数据包何时到达,这实质上将预取概念提升到更高的抽象级别。它理解如何使这些假设变得如此困难,因为它有效地将使用模型应用于架构中。
IBM的方法是使用最可能的芯片配置,预先进行权衡并设置限制。根据IBM的 Power系统硬件架构师Jeff Stuecheli的说法,这可以巩固物理层的数量,通过PCIe Gen 4运行一些数据,其余的通过25G SerDes运行。“这更具功率和面积效率,”Stuecheli说。该公司还做了一些事情,如走向不对称的架构,这意味着一个加速器的状态不会影响另一个加速器的运行。“我们希望隐藏加速器的状态表。”

图4:IBM强调数据吞吐量。资料来源:IBM
连接各个部分
从所有这些角度来看,所有主要的芯片制造商都在解决目标市场中的类似问题。它们通过通用处理器和自定义加速器的组合提高了每瓦性能,并且在许多情况下,它们使得从一个市场到下一个市场更容易,更快地替换模块成为可能,并且随着算法的更新。它们还提高了片上数据,片外到存储器的吞吐量,并优先考虑不同类型数据的移动。
其中许多方法并非新思路,但过去并不存在使这一切成为现实的一些技术。
“创建通用PHY以启用加速器是发生的关键事情之一,” Cadence的高级设计工程架构师Stuart Fiske说。“你还看到的是,处理器并没有变得更简单。很多这些公司都在尝试为加速器创建接口。这并不能解决复杂性问题。它仍然是一个几年的设计周期,并没有办法解决这个问题。但是你可以让加速器适应最新的神经网络。”
关键是平衡所有这些组件的集成,并具有足够的灵活性来进行更改。实际上,所有这些芯片制造商都在设计多芯片平台,可针对特定市场和用例进行定制,同时优化每瓦性能并提高数据吞吐量。
Silexica产品和技术营销负责人Loren Hobbs说:“时钟速度方面的设计正在崭露头角。” “前进的方向是使每个时钟周期尽可能高效。随着多核异构多处理器的增加,这加速了这些芯片的复杂性。您可以将所有这些小芯片组合在一起以提高处理能力,但您需要使用工具来帮助分发和分析它们。您必须映射代码库,这是无限复杂的。它需要静态,动态和上下文分析。”
这里的共同点是不断增长的数据量,无论是在边缘还是在云端。处理数据的位置以及移动的速度是架构的关键部分。
“每个人都在与CCIX抗争,” Arteris IP总裁兼首席执行官K. Charles Janac说。“如果你有一个加速器和两个连贯的模具,那么有太多的情况可以让它轻松工作。但现在您可以使用3D互连将平面CPU和平面I / O连接在一起。因此,这看起来像是软件的一个系统,并且您在芯片上的网络和不同的芯片之间存在芯片间链接。这样,您可以支持跨两个芯片的非连贯和一致的读/写。它使互连更有价值,但也使它变得更加复杂。”
实际上,这就是为什么这些架构已经在工作一段时间的原因之一。让所有部分一起工作已经证明比任何人最初想象的要困难得多。
“内存控制器和NoC将必须更紧密地集成,”Janac说。“问题在于,没有人理解整个芯片的QoS,也没有任何独立的内存控制器公司。但是内存流量必须更好地集成才能实现这一目标。”
为了让小型车市场真正起飞,还需要有开放标准。
“没有标准用于连接芯片,” Achronix营销副总裁Steve Mensor说。“问题是你必须能够与他们交谈。所以你应该能够为套接字开发一个芯片,并有一个链接和一个协议栈来支持它。有AMD和英特尔的专有解决方案。还有正在开发的标准解决方案。如果我构建ASIC并购买小芯片,我需要一个标准的解决方案,以便我可以独立构建该芯片。这是这个模型的基本要求。”
尽管如此,它确实为构建在不同ISA上的加速器打开了大门,例如RISC-V。
“这是小型轻量级硬件加速器的新机遇,” Codasip营销副总裁Chris Jones说。“初创公司构建芯片的开放接口可能会为半导体提供另一个繁荣周期,而这种情况将一直发生在全封装上。关于这一点仍然存在一些问题,例如谁最终负责测试整个界面,以及如何在签署界面时使用它。我们还需要看看它们的芯片接口是什么样的,它们是标准化还是保持专有。但它肯定为更多验证IP,仿真和模拟增添了新的机会。”
更换组件
目前尚不清楚的是这些架构还有哪些变化。目前推出的大多数是平面的,但也可以选择将其中一些设计推入Z轴。
例如,SerDes增加了设计的延迟,但使用先进的封装技术可以实现同样的延迟。台积电的CoWoS(基板上芯片上芯片)和InFO MS(基板上带有存储器的集成扇出)是两种选择。eSilicon的业务和企业发展副总裁Patrick Soheili表示,该公司刚刚使用联华电子的插入器开发了一种CoWoS类型的方法。
“你可以将它拆开并将其带到不同的抽象层次,”Soheili说。“如果你看一下这些架构中的一些,如果你有大量的数据流,那么拥有大量的小型SRAM是很低效的,当你做大量的内存时效率很高。这可能听起来违反直觉,但我们发现更大的内存更有效,特别是对于AI类型的应用程序。”
如何迈出下一步?
所有这些方法的市场才刚刚开始。现在的关键是找出在这些不同架构中构建可重复性和可靠性的方法,以便它们可以用于汽车或工业等安全关键应用,以及当今各种各样的终端市场。
这些新架构如此引人注目的原因在于能够针对特定应用程序对其进行自定义,并利用架构作为此类自定义的基础。所有处理器供应商都采用这些类型的架构,从FPGA供应商到像Nvidia这样的公司,后者在创纪录的六个月内推出了新的芯片架构。但很明显,未来,随着设备的修改和更新,行业将需要更多的工具,更多的数据分析以及对潜在交互的更好理解。
这只是一个转变的开始,最终将涉及整个半导体供应链。虽然扩展将继续,但在处理器领域,它只是一个额外的开关,可以在一个长列表中转换,现在包括架构,封装,材料和工作负载优化。设计师现在是变革的驱动力,他们中的大多数人预计随着摩尔定律的减速,设计的变化将会加速。
新闻源:semiengineering
-
芯片
+关注
关注
456文章
50967浏览量
424885 -
半导体
+关注
关注
334文章
27527浏览量
219943 -
加速器
+关注
关注
2文章
802浏览量
37942
发布评论请先 登录
相关推荐
击碎摩尔定律!英伟达和AMD将一年一款新品,均提及HBM和先进封装

石墨烯互连技术:延续摩尔定律的新希望
摩尔定律是什么 影响了我们哪些方面

Chiplet或改变半导体设计和制造

后摩尔定律时代,提升集成芯片系统化能力的有效途径有哪些?
观点评论 | 芯片行业,神奇的一年

高算力AI芯片主张“超越摩尔”,Chiplet与先进封装技术迎百家争鸣时代

谷歌Tensor G5芯片代工转向台积电,强化AI智能手机竞争力
“自我实现的预言”摩尔定律,如何继续引领创新
封装技术会成为摩尔定律的未来吗?

功能密度定律是否能替代摩尔定律?摩尔定律和功能密度定律比较
摩尔定律的终结:芯片产业的下一个胜者法则是什么?






 工商网监
工商网监
评论