 除了史上最大芯片之外,Hot Chips还有哪些值得关注的内容?
除了史上最大芯片之外,Hot Chips还有哪些值得关注的内容?
今年的Hot Chips,Cerebras搞了个大新闻,各种媒体刷屏。那么,除了史上最大芯片之外,Hot Chips还有哪些值得关注的内容?一起来看芯片专家唐杉的解读。
首先,Cerebras这次确实做了非常好的宣传,各种介绍和分析也很多,我就不多说了。不管大家怎么评价,我个人还是很钦佩他们的工作的,所以拼了一张AI芯片的图,算是致敬一下给我们带来“美感”的工程师们。
这几天介绍Hot Chips的文章也很多,我就全凭个人兴趣挑几个点和大家一起看一下。今年我自己没有参会,所以主要是根据演讲的材料以及Anandtech上的Live Blog做一些分析。如果大家感兴趣,也可以看看我去年写的文章(Hot Chips 30,黄金时代的缩影,Hot Chips 30 - 机器学习,Hot Chips 30 - 巨头们亮“肌肉”),有些内容可以作为参考。
摩尔定律怎么“续命”
从某种意义上说,我们整个半导体产业都是在为摩尔定律的延续而努力,即我们希望能给18个月之后的应用需求提供成倍增长的“性能”支撑,只不过现在这个承诺不再是单单靠工艺节点的演进和晶体管数目来支撑了。
这次Hop Chips上的两个主旨演讲,可以说就是从不同角度讨论了这个问题。一个是处理器巨头AMD的Dr. Lisa Su分享的“Delivering the Future of High-Performance Computing”;另一个是TSMC的Dr. Philip Wong分享的“What Will the Next Node Offer Us?”。先看看Lisa Su的总结,为了给未来十年提供高性能计算能力,我们可做和要做的事情还是很多的。
source:Hot Chips 2019[1]
从Foundry的角度,Dr. Philip Wong讲的就更直接,“MOORE’S LAW IS WELL AND ALIVE”,不过他的说法也不是单独针对晶体管的性能,而是各种技术综合发展的结果。
source:Hot Chips 2019[2]
从架构“黄金时代”(黄金时代)的说法来看,工艺演进速度放缓并不一定是坏事情,大家为了延续摩尔定律会在更多的方向上努力。比如,在这次会议上,Nvidia展示的工作[3]就是一个覆盖了很多领域和设计环节的实验。它包括Multi-chip架构,NoC(Network-on-Chip)和NoP(Network-on-Package)构成的层次化通信,高带宽的inter-chip互联,甚至是敏捷开发方法,挺有意思。而Facebook的讲演[4]也介绍了大型系统协同设计的非常好的实践。而在其它很多讲演中,比如Intel,Nvidia,AMD,华为等等,我们也可以大量看到新型封装和集成技术的应用和快速进展。
NN加速器架构的下一步
这次也有几家展示了NN加速器的架构,比较详细的包括华为和Tesla。我们先看看Tesla。
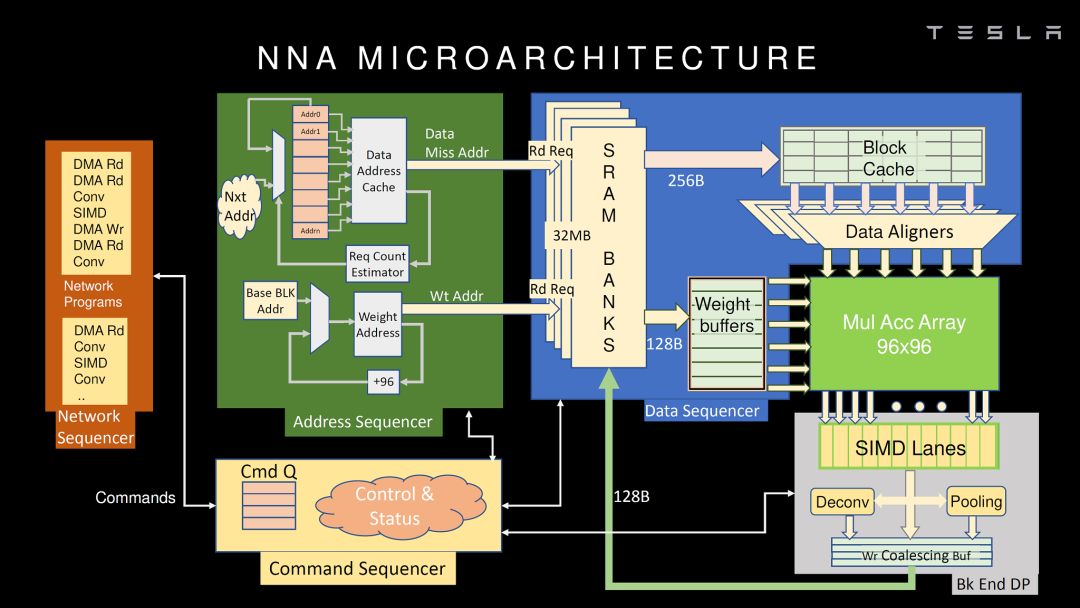
source:Hot Chips 2019 [3]
应该说,Tesla的NNA不管从指令集还是微架构都和Google TPU(公开的第一代)非常类似,MAC矩阵实现卷积和矩阵乘,SIMD实现其它运算,再加一些特殊运算的硬件加速。这种架构应该是目前看到最多的设计,简单直接,硬件实现比较容易,挑战是MAC矩阵的使用效率。当然,在很多细节上,Tesla的NNA还是做了不少优化。如我之前的文章的分析,Tesla的芯片完全是自用的,合适就好,没有太多可比性(多角度解析Tesla FSD自动驾驶芯片)。
相比之下,华为的DaVinci Core应该是结合了这几年的AI芯片经验和深入的思考。其特点是在一个Core里面同时支持3D(Cube),2D(Vector)和1D(Scalar)的运算,以适应不同网络和不同层的运算分布的变化。当然,把各种运算架构放在一个Core里面并不是特别困难的事情,更难的是设计参数的选择,运算和存储的比例,软件mapping工具等等。这些问题在华为的talk里也给出了一些分析。
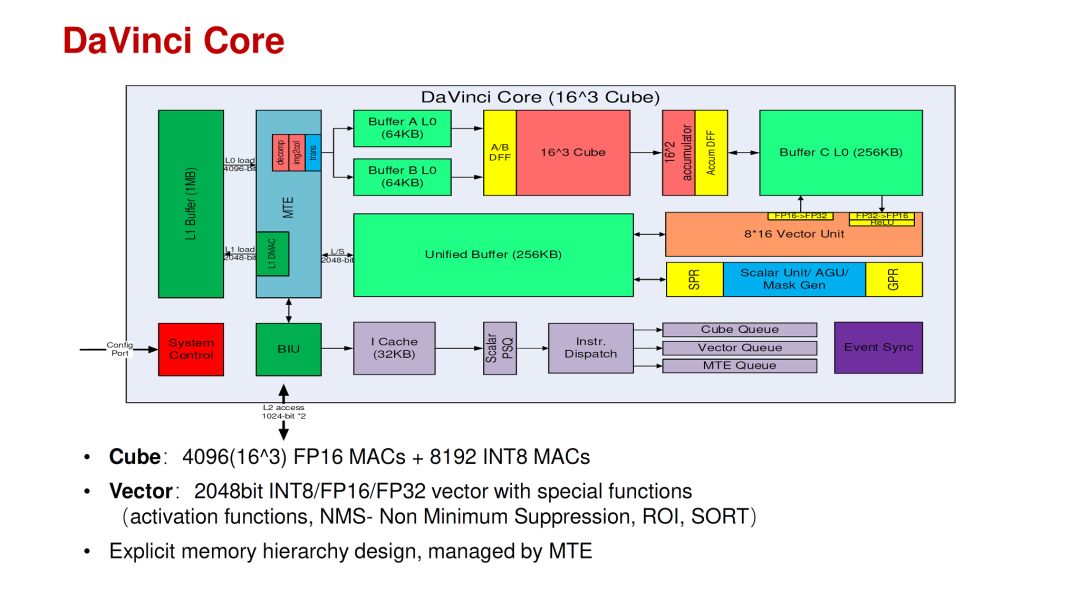
source:Hot Chips 2019 [4]
另外,Intel和Xilinx也展示了他们的AI加速Core的设计。如下:
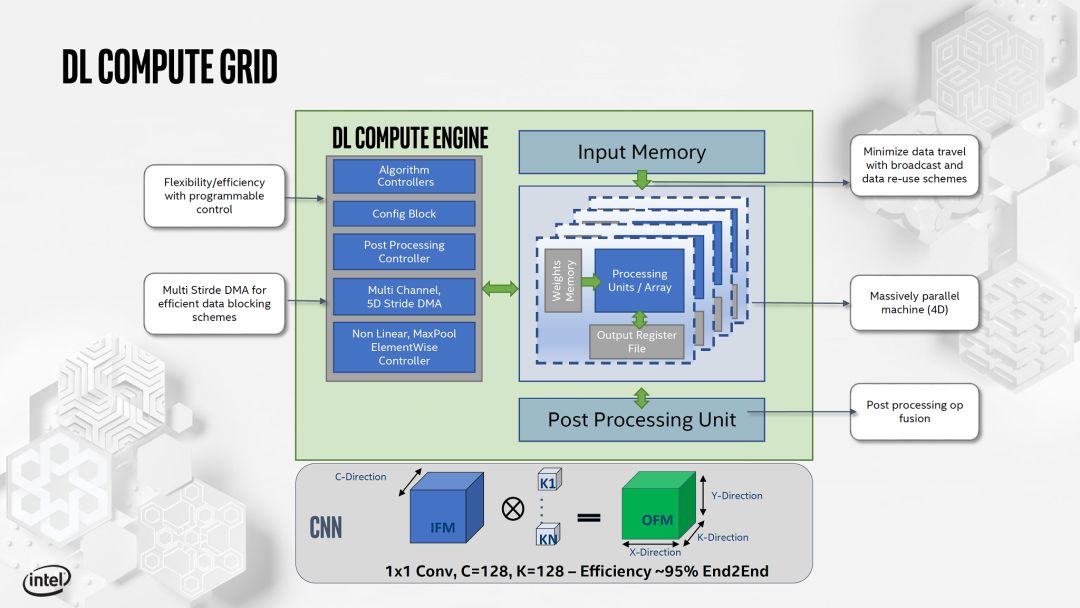
source:Hot Chips 2019 [5]
source:Hot Chips 2019 [6]
从指标来看,目前比较容易对比的主要是云端inference芯片,Nvidia的T4,Habana的Goya,Intel的NNP-I,都有ResNet-50的IPS(Image Per Second)和IPSW(IPS/W)数据。
data source:厂商
如果考虑到T4并不是单纯的inference功能,以及NNP-I的工艺优势,那么大家的Inference IPSW指标的差异并没有太大。当然,可能得等大家都提交了MLPerf的结果,我们才可能进行更完整和公平的对比。对于指标的分析,大家也可以看看我之前的文章,“数据中心AI Inference芯片今年能达到什么样的性能?”,看起来我之前的预测没太大问题。
我们再看Trainning芯片,不论是Nvidia,Google,Habana还是Intel这次发布NNP-T,更重要的已经不是NN加速器core的架构,而是存储容量,访存带宽,和可扩展能力。
所以,不管是从大家公布的架构,还是从指标来看,从TPU,Eyeriss,NVDLA到今天的Tesla FSD芯片和华为的DaVinci Core,如果不考虑基于新型存储和器件的特殊设计,可以说NN加速器基本的硬件架构已经定型,主要工作是设计参数的优化或者针对不同应用的 trade off。换句话说,新架构(专用处理器相对CPU和GPGPU)的红利已经充分兑现了。那么,对于架构设计者来说,下一步的机会是什么呢?个人感觉可能有下面一些方向。也欢迎大家留言讨论。
第一,更专用NNA的设计。一般来说我们即使是做Domain-Specific设计,也希望芯片能够面向一类而非一个应用。但如果一个应用(比如只跑一个典型网络)有足够大的市场和更严格的PPA要求(一般芯片满足不了),做一个更专用的设计也未尝不可,甚至可能是很好的机会。这种情况在我们说的IoT应用里比较多,芯片不大,但对PPA很敏感,适合算法硬件协同能力强,并且可以快速迭代的团队。当然,这种模式成立有个大前提,即AI使能更多新的应用,并越来越快的落地。
第二,从单纯NN加速设计到“NN+非NN”加速设计。在NN可以实现真正的end-to-end之前,即使是所谓的AI应用,NN算法和非NN算法也会在一起共存很长时间。一个好的架构应该是加速完整的应用而不仅仅是NN部分(其实用户根本不在乎你的架构),这个需求在Edge/Device这个应用领域更为明显。解决这个问题有两种思路,一个是异构架构的优化,特别是NN和非NN算法在不同硬件架构上的mapping和协同。另一个思路是以比较传统的Vector DSP(即可以做NN加速,也可以做很多传统算法,包括CV和语音,有可能会有优势)为基础,以特殊指令或紧耦合的加速器的形式集成小规模的Tensor Core,来找到更好的平衡点。
第三,软硬件协同设计还是有很大空间。在DaVinci的例子里,即使硬件支持不同粒度的运算,在实际网络怎么用好这些硬件也还是非常困难的课题。最近我讨论这个话题也比较多(AI芯片“软硬件协同设计”的理想与实践)。其实这次Hot Chips上Google的tutorial就是“Cloud TPU: Codesigning Architecture and Infrastructure”。这里并没有太多的介绍TPU架构,而是把重心放在了协同设计上,其的内容也远远超出了NN加速本身。从这里也可以看出,未来的协同设计不仅仅是NN加速器这一个点,而在“高手过招”当中,必须要完整考虑整个系统的优化。
source:Hot Chips 2019 [7]
一个有趣的插曲是,当我在朋友圈分享这个内容的时候。一个评论是“每次这种会上,都会觉得“哇好有道理”,然后一想好像又啥都没说”。其实协同设计的现状也类似,就是看起来很美,做起来不易。
另外,这次会议还有一个来自Stanford AHA Agile Hardware Center的名为“Creating An Agile Hardware Flow”的演讲,也是在讲如何快速进行软硬件协同设计。他们的一个思考是,协同设计最大的挑战在于设计空间太大,为了缩小探索的空间,我们可以使用CGRA可重构硬件架构作为硬件基础(只需探索CGRA的配置);以HalideDSL作为稳定的软硬件接口,实现优化的解耦。所以,从软硬件协同设计这个角度来看,CGRA架构也是非常值得关注的。这个话题我后面会找时间详细讨论。
存内计算和“近存储”计算
去年的Hot Chips上,基于Flash Cell做存内计算的初创公司Mythic很受关注,我也做过比较详细的分析(Hot Chips 30 - 机器学习)。这一年以来,基于各种memory cell,包括SRAM,DRAM,FLASH和新型存储器件,MRAM,RRAM等等的存内计算初创公司大量涌现,非常热闹。其实除了存内计算,还有另一类“近存储”计算。借杜克大学燕博南同学的一张图说明一下。
其中In-Memory的意思是直接使用存储单元阵列来做计算,一般是模拟方式,通过AD/DA和数字逻辑部分交互。而Near-Memory则是尽量把运算逻辑(处理器或者加速器)放在离存储单元比较近的地方。
在这次的会议上,一个初创公司upmem,虽然自称是PIM,但实际走的是近存储计算的路线。upmem的产品看起来和传统的DRAM颗粒和DIMM没有什么区别,但在每个4Gb DRAM颗粒里嵌入了8个处理器核。
source:Hot Chips 2019 [10]
这是近存储计算的一个很好的例子,在DRAM里的处理器可以分担CPU的工作,减少不必要的数据搬移,当然有很多好处。但是要真正把计算逻辑和DRAM放在一起并不是那么容易的,其中最大的挑战就是如何使用DRAM工艺来支持处理器设计,下图列举了主要的困难。
source:Hot Chips 2019 [10]
所以,这个讲演的大量内容是如何克服DRAM工艺的这些困难设计处理器,包括:
1. 在DRAM工艺上建立数字逻辑的flow,比如Logic cell library,SRAM IP和Logic Design & Validation flow,这些是处理器设计和实现的基础;
2. 使用比较“慢”的晶体管设计实现“快”的处理器的方法,14级流水实现500MHz,Interleaved pipeline,24个硬件线程(这个是保证深流水线效率的主要方式)。
3. 不使用Cache,而是Explicit memory hierarchy,这个也和多线程有关系。
4. 优化的指令集,专门强调了没有使用ARM和RISC-V。这里也解释了,由于不需要运行OS,所以没有必要考虑兼容性问题,只要实现CLANG/LLVM的支持。
此外,在DRAM中加了这么多处理器核,怎么使用(编程模型)是个问题。在upmem的讲演中也分析了这方面的内容。(此处图配错了,抱歉)
source:Hot Chips 2019 [10]
如果我们考虑近存储计算,其实还有一个大量存储数据的地方,就是硬盘。因此,现在也有很多的SSD控制器芯片加入的更多的计算功能。比如前一段时间我们看到初创公司InnoGrit就在SSD控制器芯片中加入了NDLA专门加速AI运算。当然除了直接在芯片中增强算力,还有一种模式就是在SSD控制器外增加FPGA,比如三星的Smart SSD方案(下图)。在这次Hot Chips的Poster里面,就有一个来自Bigstream的工作是基于Smart SSD构建的应用框架。
source:samsungatfirst.com/smartssd/
总的来说,相对存内计算,不依赖工艺进展的近存储计算可能更容易在短期内落地。但和存内计算一样,近存储计算也需要有完整的软硬件解决方案,否则简单增加的算力可能仅仅是鸡肋。
-
芯片
+关注
关注
454文章
50488浏览量
422234 -
半导体
+关注
关注
334文章
27088浏览量
216765 -
AI芯片
+关注
关注
17文章
1862浏览量
34932
原文标题:史上最大芯片长得像iPad?那你还没看懂Hot Chips
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
请问同一款芯片,SOIC和SOP除了封装不同外,还有其他区别吗?
史上最大屏幕Apple Watch亮相 屏幕面积增加了30%
电流反馈运放的反相输入端和同相输入端除了输入阻抗不同之外还有什么区别吗?
NVIDIA 在 Hot Chips 大会展示提升数据中心性能和能效的创新技术

数据分析除了spss还有什么


滑动变阻器除了保护电路,还有什么作用?
电源模块除了转换电压还有哪些功能
2023年十大儿童电子设备盘点:除了儿童手表还有啥?

芯片之外,还有哪些替代?






 工商网监
工商网监
评论