 深度学习从社交媒体中为你发掘最美穿搭
深度学习从社交媒体中为你发掘最美穿搭
穿衣搭配不仅反映个人的审美同时也与出席的场合、文化传统息息相关。在一个时尚场景中,通常会包含三个要素:场合、个体和衣着。这些时尚信息和知识对于衣着推荐搭配等应用十分重要。而当今高度发展的社交媒体为时尚知识提供了丰富的资源,从朋友圈到微博从推特到Ins,人们在不同场合的穿搭图像、文字和多媒体信息构成了庞大的信息资源。
来自新加坡国立大学的研究人员们利用深度学习集成多种方法来从社交媒体中抽取时尚三要素,以实现时尚知识的自动化抽取和学习,同时还构建了以用户为中心时尚知识抽取数据集FashionKE。
时尚时尚最时尚
随着生活水平的不断提高,人们的时尚需求不断增加,对于不同场合的衣着搭配也有着更为精细化的需求。面对这个万亿级的时尚市场,如何将机器学习与深度学习更有效的应用于时尚知识的学习、穿搭推荐甚至是知识级别的构建是科技巨头和研究人员们的研究热点。
目前对于时尚知识级别的研究工作还比较有限,如何有效的穿衣搭配涉及到场景、主体和衣着三个关键因素。在日常生活有很多固定的经验和模式帮助人们进行有效的穿搭,但研究人员希望将这些模式总结成更为凝练的知识以指导不同的人在对应的场合进行最适宜的穿搭。在这一过程中,需要面对的第一个问题就是,从哪里去获取这些知识呢?如何获取这些知识呢?新加坡国立大学的研究人员给出了自己的答案。
他们将目光放到了各大社交媒体平台,从中进行以用户为中心的自动化时尚知识抽取,来帮助实现这一目标。为什么呢?社交媒体的庞大用户规模保证了多模态数据的丰富和质量,不仅包含了世界各地、各个场景中用户的照片,同时也包含了包括性别在内的个人属性,而且还紧跟时尚潮流更新迅速。但有些利用这些数据还面临着一系列挑战。
首先时尚知识的抽取很大程度上决定于时尚概念和属性抽取器的表现,包括对于场景、衣着和饰品的识别检测。虽然现在在学术界有很多研究成果,但大多集中于简单干净的背景上,而现实中面对的却是丰富多样的自然场景,使得属性检测变得十分困难。第一个需要解决的挑战就是需要实现自然场景和背景的时尚概念和属性检测。
其次社交媒体虽然丰富,但基本上缺乏时尚概念的标注,但这对时尚知识的构建十分重要。时尚知识自动获取的质量极大地依赖于语义级的时尚概念学习。手工标记如此庞大的数据是不现实的,而现存的电子商务数据主要集中于衣着属性,缺乏人物和场景属性的标注。 如何解决这两个问题成为了实现知识抽取的关键。
时尚知识自动化抽取
为了解决这两个问题,研究人员提出了一种基于弱标记数据的时尚概念联合检测方法。这种基于上下文的时尚概念学习模块可以有效捕捉不同时尚概念间的联系和相关性,通过场景、衣着分类和属性来辅助时尚知识抽取。其中弱标记数据则有效应对了缺乏标记数据的困扰,在标记迁移矩阵帮助下,通过机器标记数据和干净数据的结合可有效控制学习过程中的噪声。
这一研究的目标在于从社交媒体中抽取用户为中心的时尚知识数据,得到场景对应穿着的结构化数据为下游任务提供应用基础。
研究人员将时尚知识定义为个体、衣着和场合三元组合K={P,C,O},其中个体包括了人的属性:性别、年龄、身材;服装则包括了衣着的属性和分类,用于定义特定类型的服饰,例如:一条深蓝色的露肩长裙;场景则包含了各种主体出席的场合、包括舞会、约会、会议、聚会等等及其相关的时间地点元数据。
研究人员的任务就是要从某个po出的社交媒体信息{V(图像),T(文字),M(元数据)}中抽取出上面的信息构成时尚知识{P,C.Q}。这一任务自然包含了三个子任务:人体属性检测、衣着分类和属性检测、场景检测。
人体检测框架目前很成熟,所以研究人员致力于后两个子任务的开发,从社交媒体数据中联合检测出主体所处的场景和服装分类属性。
为了有效检测场景及其主体的衣着分类属性,研究人员设计了一套统一的框架来获取其属性及相关性。这套基于上下文时尚概念的学习模型包含了两个双边回归神经网络来捕捉场景、衣着间的联系。
对于某篇包含图像V和文字T社交媒体来说,这一模型首先将衣着检测模型检测图像中一系列的服饰区域。随后针对图像预测出对应的场景标签,针对每个服装区域预测出对应的服装类别和属性标签。为了有效的预测出这三者之间的相关性,研究人员利用基于上下文的方式来从中得到不同属性间的关系以便抽取知识。为了有效抽取知识,需要对服装分类、场景和服装属性的表示进行学习。
分类表达。模型的第一步是学习服装区域的上下文表示用于分类预测和整幅图像的场景预测。研究人员首先利用与训练的CNN来抽取全图和每个服装区域的特征表示,随后利用双边LSTM来编码所有服装区域间的相关性,并最终得到服装区域的分类表达。
场景表达。为了更好的表达整幅图像,研究人员将第一步中整幅图像的CNN特征、上一步Bi-LSTM的最后隐含状态及TextCNN抽取文字描述特征结合为新的特征,来实现场景表达学习;
属性表达。最后,由于每种服装有包括颜色、长短、外形等多个不同特征,所以需要属性预测模块来预测属性。研究人员利用多分支的结构来对不同种类的服饰进行属性预测,每个分支输出层的神经元数量代表了对应的属性数目。
随后为了捕捉不同服饰属性和服饰分类间的依赖关系,研究人员使用了第二个双边LSTM来编码属性和分类间的依赖关系,并最终通过全连接转换为属性表达。最终通过标准的分类器将得到场景、服装分类和属性的预测分数。
为了对这一模型进行训练,研究人员构建自己的数据集FashionKE,其中包含了80629张图像,可以容易辨认出时尚知识的三要素。同时对每张图片进行了场景标注(十种主要场景);而针对服装属性和分类标注,由于社交媒体数据过于庞大,对于每一个图像和文字数据进行多种属性的手工标注是不现实的。只有30%的数据进行了人工核对,其他数据都利用时尚标签工具进行机器标注。
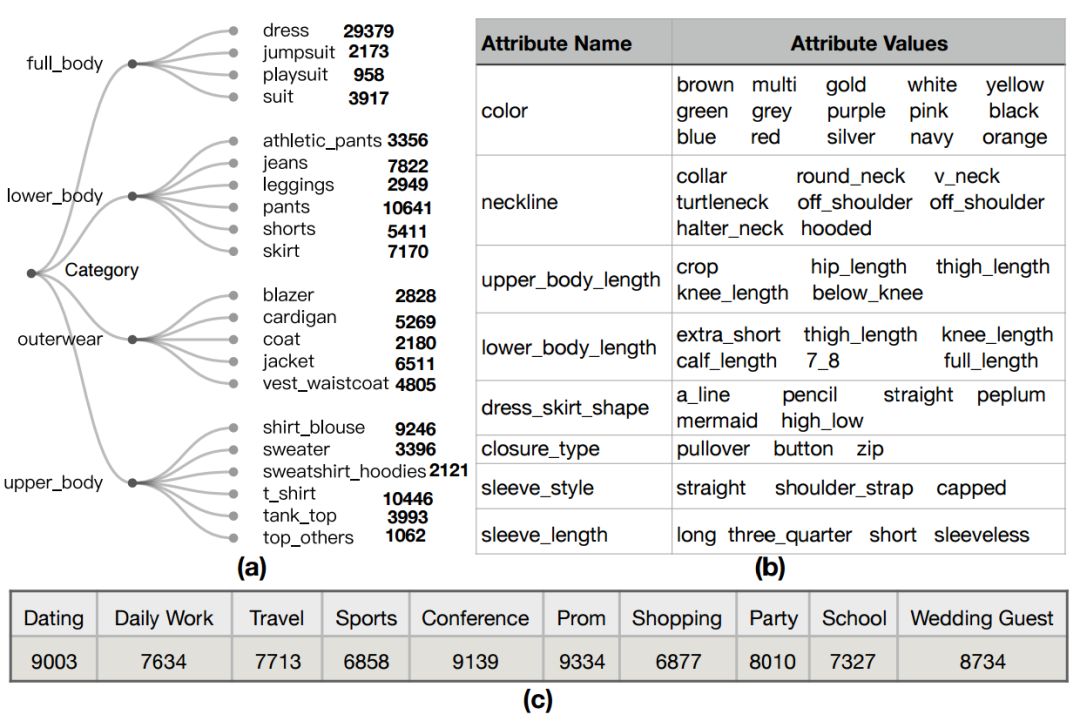
机器标注的数据很廉价,但是却包含很多的噪声,使得模型的训练容易出现过拟合。为了充分利用机器标注的数据和少量人类标记数据,研究人员引入了弱标记建模的方法来处理机器标记数据中的噪声。其基本思想是在模型中添加一个标签校正层,在预测层后利用估计出的标签转换矩阵来实现,使得预测与弱标记的数据分布相匹配。这一转换矩阵将通过与主干任务协同训练的线性层来得到。
实验和结果
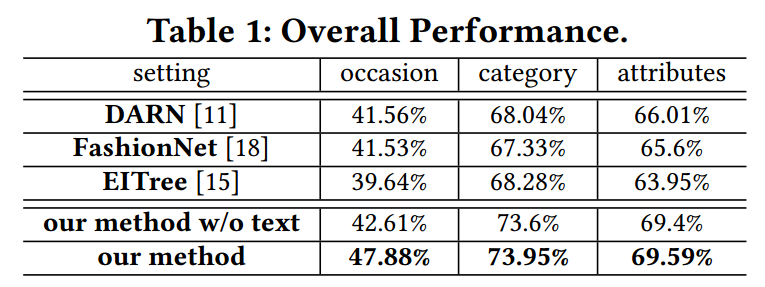
研究人员在实验中发现新提出的框架和策略有效的实现了时尚概念的预测。通过与DARN、FashionNet和EITree的比较本文的方法在多个指标上都超过了先前的方法。
一方面,由于本方法充分使用了机器标注的模型并通过弱标记建模模块抑制了标注噪声的影响,从而得到了额外的增益。这一模型将场景、服装分类和属性间的依赖性和相关性进行了考量,为时尚概念的识别提供了额外辨别能力。这些依赖性和相关性表明时尚知识的存在以及对于相关应用的积极作用。
另一方面,这一方法还通过文字信息进一步提升了性能,特别是在场景分类中很多社交媒体的问题信息包含了丰富的场景信息,有助于时尚信息的抽取。
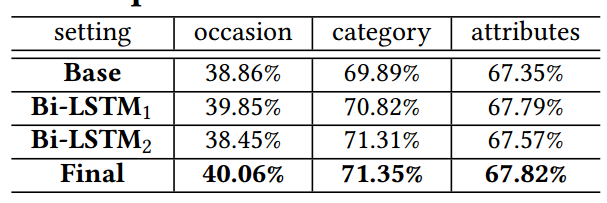
此外通过消融性分析,研究人员发现第一个Bi-LSTM通过学习出不同服装区域间的相关性来提升了分类性能,并通过将隐含层的加入来替身了场景预测性能;第二个Bi-LSTM则通过不同属性表达和分类表达间的依赖性建模来提升性能;同时两个LSTM间的协同作用也将显著加强模型知识抽取能力。
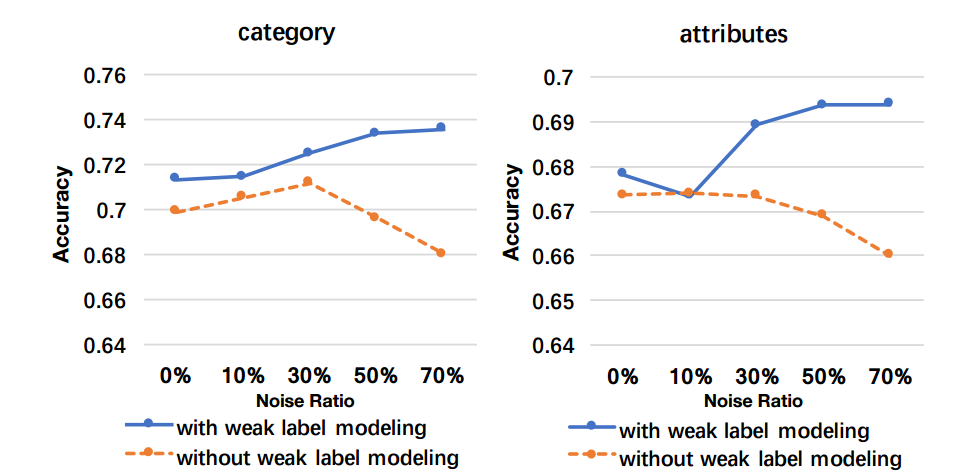
最后通过不同比例的噪声数据对模型训练也显示出弱标记建模对于知识抽取能力的提升。
最后研究人员们还展示了基于这一模型在不同领域的应用。
从时尚概念抽取时尚知识,图中展示了一部分结构化的时尚知识
不同场景下人们的穿着服饰分析,包括国家、场合和季节都有着明显的区分。
时尚知识分析,包含了不同季节和不同地区不同场合的穿着。
下图还显示了不同场合中最流行的服饰,包括了其中纵轴是男性女性对应的十种场景、横轴是对应的流行穿着。可以看到会议中男性倾向于穿着夹克外套、舞会中女性则喜爱各种连衣裙。
同时研究人员们还分析了不同属性和分类间的相关性,图中的节点大小代表了服饰的数量,边的宽度代表了相关性的强弱。可以看到牛仔裤和衬衫T恤都是大家的最爱搭配。而不同属性间的相关性中可以看到长款衣服还是主流,长袖长裤是主流搭配。
在未来研究人员们还将探索包括时尚穿搭推荐的不同领域的应用,并对更加细粒度的知识进行抽取,同时加入不同的视觉概念来实现包括交叉模态检索和人体检索等更多的检索任务。
-
模块
+关注
关注
7文章
2718浏览量
47560 -
神经网络
+关注
关注
42文章
4773浏览量
100890 -
深度学习
+关注
关注
73文章
5507浏览量
121272
原文标题:对面的女孩看过来,深度学习从社交媒体中为你发掘最美穿搭
文章出处:【微信号:thejiangmen,微信公众号:将门创投】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
GPU在深度学习中的应用 GPUs在图形设计中的作用
NPU在深度学习中的应用

FPGA做深度学习能走多远?
深度学习中反卷积的原理和应用
深度学习中的时间序列分类方法
深度学习中的模型权重
深度学习与传统机器学习的对比
深度解析深度学习下的语义SLAM







 工商网监
工商网监
评论