 facebook AI研究院又发布了一个大规模的词汇实例分割数据集
facebook AI研究院又发布了一个大规模的词汇实例分割数据集
聚焦于关键科学问题的数据不断促进着目标检测领域的技术进步,使得目标检测的性能从简单的图像扩展到了复杂的场景,从边框标注拓展到了语义分割掩膜。
近日来自facebook AI研究院的研究人员们又发布了一个大规模的词汇实例分割数据集(Large Vocabulary Instance Segmentation,LVIS ),包含了164k图像,并针对超过1000类物体进行了约200万个高质量的实例分割标注。由于数据集中包含自然图像中的物体分布天然具有长尾属性,LVIS数据集将促进深度学习在图像分割领域的进一步发展。
目标检测是计算机视觉领域的重要任务,适用性强、用途广泛、发展迅速,近年来在数据集、基准算法和检测能力上都得到了大幅度提升,并衍生出一系列新的能力,包括图像分割、三维表示和三维目标检测等内容。
目前针对目标检测算法的严格测评只在少量的分类上进行(例如20类/80类),那么在真实环境中有大规模类别的物体或者出现了罕见的物体时该如何处理?这就为科学家们提出了新的问题。
图像中目标类别的长尾效应是不可避免的,标注更多的数据集虽然可以有效地发现先前未见或罕见的类别,但有效地从小样本中学习至今还是机器学习与计算机视觉领域一个重要的开放问题,也使得这一领域成为科学界与工业界研究最为活跃的领域。但要深入的对这一领域进行研究,一个高质量的数据集和基准必不可少!
FAIR的研究人员针对这一研究方向设计并收集了称为LVIS的针对于大规模词汇实例分割的数据集,这一数据集包含了164k图像,超过1000类数据,约两百万个标注。
值得一提的是,这个数据集的收集流程没有预先确定的类别(没有类别先验),首先收集图像然后根据图像中目标的自然分布来进行标注。大量的人工标注代替了机器的自动化标注使得图像中自然存在的长尾分布可以被有效识别。
COCO和ADE20K数据集
研究人员设计了一个有效的众包标注流程,可以在高质量标注的前提下获取大规模的数据集。对于目标检测和实例分割来说,标注的质量对于算法十分重要。类似COCO这样相对较粗的标注限制了算法对于mask预测质量的提升。与COCO和ADE20K相比,LVIS数据的标注mask具有更大的重叠面积和更好的边缘连续性。
在构建数据集的过程中,研究人员采用了评价优先的设计原则。这意味着研究人员首先确定了对算法性能进行评价的方法,并基于这一方法来进行数据集的收集和构建,以满足评测方法的需求。研究人员提出的测评基准使用了类似coco风格的的实例分割和AP计算方法。
但针对自然图像中较为长尾的数据集,需要解决两个不可避免的问题:
1)在类别庞大的情况下,如果某个目标拥有多个标签,该如何公平的评测检测器的性能?
2)针对164k图像超过一千个类别的标注任务,如何设计合适的标注流程来减少工作量?
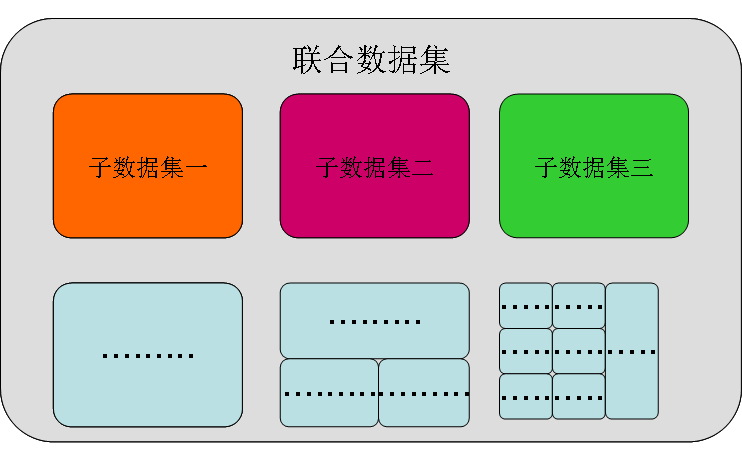
解决这些问题的关键在于构建联合数据集:通过多个小数据集联合构建大规模的完整数据集,而每一个子数据集则类似于只聚焦于某个单一类别的传统数据集。在标注过程中,每一个小数据集将集中标注某一个特定的类别,将图中某个特定类别的所有目标穷尽(exhaustive )标注。
对于完整的大数据集来说,构成的子数据集间可能会有重叠,单一目标可能会有多个标签。此外由于在每个小数据集中进行了针对一类物体的穷尽标注,在完整的联合数据集中就无需对所有的类别进行穷尽标注,这样的方法极大地减小了标注的工作量。
更为关键的是,在测试评价时算法并不知道每张图片组成的标记类别,它将对所有的标记类别一视同仁地进行处理,这将对联合数据集内的各个数据集提供公平的测评。
LVIS数据集针对的是实例分割任务,这一任务的主要目标是在给定分类已知固定类别的情况下,算法可以针对一张事先未见过的图像进行处理,并输出图像中出现的每一个实例及其对应的分类和置信度分数。通过算法生成的一系列输出,可以计算出掩膜的平均精度mAP。
但在算法的测评中,研究人员将面临着一系列问题。随着分类数目的增加,实例的标签不可避免的将会出现重叠和混淆:部分视觉概念的重合、父子分类关系的的界定和同义词的识别等等。如果没有有效的方法处理这些问题,测评的方法将会产生很大的不公平性。
例如很多玩具都不是鹿,大多数鹿都是不是玩具,但是一只玩具鹿同时是玩具也是一只鹿,这时目标检测算法很有可能得到错误的标记。再比如,一辆车的标记是交通工具vehicle,算法如果输入了car那么就会被判定为错误。
这些问题的发生主要来源于GT标注缺失了一个或者多个描述目标的标签。如果算法预测到了某个标签但是没有在GT中标注过就会得到错误的惩罚。但对于这个新的数据集来说,每一个物体的标签都被穷尽且正确的标注,上面的问题就可以迎刃而解。
数据集标注流程
数据集的标注流程分为了六个主要的步骤包括目标定点、穷尽标记、实例分割和验证、穷尽标注验证、负例标签等。
目标定点中标注者被要求将图像中输入不同类别的实例进行标记,这个阶段将迭代进行,使得标注者可以不断从图像中发掘出自然场景下目标的长尾信息。随后再针对第一阶段标记的每一个类别,将进行彻底的实例标记,找出每一类别包含的所有实例。在图中可以看到标记者又标记出了更多的书。
在第三和第四阶段,分别对前面标记的实例进行实例分割标注和验真,重复进行直到准确率超过99%通过验证。第五阶段将进行穷尽标注验证检测,检查是否所有的实例都被分割和标注类别,如果有就将缺失标注实例的类别筛选出来进行补充标注。最后一步的负例标签将用来验证类别子类的标签没有出现在图像中。更详细的标注细节请参看论文的第三部分。
探索数据集
下面让我们来探索一下数据集,下图中可以看到每张图像里对于某一类图像都进行了完善地标注,小的、被遮掩的难以辨认的,目标实例都被标注了出来。比如第一行最后一列的车牌标注和第三行最后一列的相机标注,尽管很小但也别明确地画出掩膜。这些目标对于图像的抽象和理解十分重要。
下图中各类实例也别分别标注出来了:
子数据集中,每个实例都被穷尽标注。例如对于飞机这个分类,下图展示了每张图片中所有的飞机,无论是飞机的一部分还是完整的飞机都被标注了出来。
还有这些诱人的水果,都被一个个挑了出来。就拿菠萝来说吧,无论是商店里的完整菠萝还是沙拉里的菠萝,就连披萨里的菠萝丁也被标记出来了。
还有更多好玩的的数据集和详细的分类信息,请参看数据集网站:
-
图像
+关注
关注
2文章
1086浏览量
40496 -
Facebook
+关注
关注
3文章
1429浏览量
54805 -
计算机视觉
+关注
关注
8文章
1698浏览量
46030 -
数据集
+关注
关注
4文章
1208浏览量
24730
原文标题:FAIR提出大规模细粒度词汇级标记数据集LVIS,有效识别长尾分布
文章出处:【微信号:thejiangmen,微信公众号:将门创投】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
安谋科技与智源研究院达成战略合作,共建开源AI“芯”生态

蓝思科技将新增昆山创新研究院,重点服务苹果
AI大模型的训练数据来源分析
Zettabyte与纬创携手打造台湾首个超大规模AI数据中心
易华录无锡数据湖与清华大学苏州汽车研究院(吴江)合作挖掘智能驾驶数据新价值
山东大学智能创新研究院加入甲辰计划,为RISC-V生态繁荣聚势赋能

开芯院发布全球首个开源大规模片上互联网络IP“温榆河”

香港应科院—国芯科技新型AI芯片联合研究实验室正式成立

长沙北斗研究院总部基地正式奠基
北京开源芯片研究院正式加入甲辰计划!
航天宏图与天仪研究院合作共同推动遥感卫星数据应用创新

本源入榜胡润研究院2024全球独角兽榜单!

依托广立微建设的浙江省集成电路EDA技术重点企业研究院正式挂牌

名单公布!【书籍评测活动NO.30】大规模语言模型:从理论到实践
Harvard FairSeg:第一个用于医学分割的公平性数据集






 工商网监
工商网监
评论