 NVDIA提出一种面向场景图解析任务的图对比损失函数
NVDIA提出一种面向场景图解析任务的图对比损失函数
关系识别(Relationship Detection)是继物体识别(Object Detection)之后的一个重要方向。使用视觉关系构建的场景图(Scene Graph)可以为很多下游任务提供更丰富的语义信息。这篇文章我们讨论目前常规模型遇到的两个普遍问题,并提出三种loss解决,同时我们也设计了一个高效的end-to-end网络搭配我们的loss来构建场景图。我们的模型在三个数据集(OpenImage, Visual Genome, VRD)上都达到了目前最优结果。
张骥,罗格斯大学在读博士生,曾在Facebook AI Research (FAIR),Nvidia Research实习参与计算机视觉领域研究项目,在CVPR,AAAI,ACCV等会议均有论文发表,并在2018年Kaggle上举办的Google OpenImage Visual Relationship Detection Challenge比赛上获得第一名。这篇文章是参赛模型的一个改进版本。
论文链接:https://arxiv.org/abs/1903.02728
代码链接:https://github.com/NVIDIA/ContrastiveLosses4VRD
近两年来,场景图解析任务(Scene Graph Parsing,也称Scene Graph Generation)开始获得越来越多的关注。这个任务的定义是针对输入图片构建一个描述该图片的图(graph),该图中的节点是物体,边是物体之间的关系。下图是一个例子:
图片来源:J. Zhang, et al., AAAI2019[1]
众所周知,物体识别是一个相对成熟的领域,目前很多state-of-the-art方法在非常challenging的数据集上(MSCOCO, OpenImages)也能得到不错的结果。这意味着,在构建场景图的过程中,把节点(也就是物体)探测出来不是一个难点,真正的难点在于构建图中的边,也就是物体之间的视觉关系(visual relationship)。
自2016年ECCV第一篇视觉关系识别的文章[2]出现以来,已经有很多工作关注于如何通过给物体两两配对并且融合物体特征来得到它们之间关系的特征,进而准确探测出关系的类别[3, 4, 5, 6, 7, 8, 9]。但这些工作的一个共同问题在于,场景图中每一条边的处理都是独立的,也就是说,模型在预测一对物体有什么关系的时候不会考虑另一对物体,但实际情况是,如果有两条边共享同一个物体,那么这两条边常常会有某种客观存在的联系,这种联系会显著影响预测的结果,因而在预测两条边中任何一条的时候应该同时考虑两条边。
这篇文章正是观察到了边之间存在两种重要的联系,进而针对性地提出三种损失函数来协同地预测视觉关系。更具体地说,这篇文章观察到了两个客观存在的常见问题,这两个问题在前人的工作中并没有被显式地解决:
问题一:客体实例混淆
客体实例混淆的定义是,一个物体只和相邻的很多同类别的物体中的一个存在关系时,模型不能正确识别出它和这些同类别物体中的哪一个有关系。换言之,很多视觉关系是有排它性的。一个人如果在骑马,那么即便他周围有一百匹马,他也只可能在骑其中一匹。下图是一个文章中给出的例子。图中的人面前有若干酒杯,该人只拿着其中一只杯子,但传统模型由于缺乏显式的区分机制,它错误地认为桌上那个酒杯在被人拿着。
问题2:邻近关系模糊这个现象是说,当两对物体靠的很近,同时它们之间的关系类别一样的时候,模型很难作出正确的匹配。下图是这个现象的一个例子。图中有两个“man play guitar”,和一个“man play drum”。由于三个人靠的很近且都在演奏乐器,视觉上很容易把人和他对应的乐器混淆,在这张图片中,传统的scene graph parsing模型就把右边人错误地认为是在打中间的鼓。
这两个问题的根本原因都在于,决定物体之间关系的视觉特征往往非常微妙,而且当需要判别出物体之间有无关联时,观察者往往需要将注意力集中到邻近的多个物体并进行对比,这样才能避免混淆,准确区分出谁和谁是相关的。这正是本文提出的解决方案的动机。 解决方案
针对这两个问题,本文提出三种损失函数来解决。总的来说这三种损失函数的思想是,训练过程中对于每个节点(即物体),筛选出当前模型认为与之匹配,但置信度最小的那个正样本,同时选出当前模型认为与之不匹配但置信度也最小的那个负样本,再计算这两个样本的置信度的差异,然后把这个差异作为额外的损失值反馈给模型。根据这种思想,本文进一步设计了三种类型的损失函数形式:
1. 类别无关损失(Class AgnosticLoss)
该函数的计算分成两步,第一步计算正负样本的置信度差异:
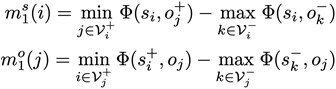
其中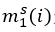 是当物体i作为主语(subject)的时候它所有可能对应的宾语中正负样本置信度差异的最小值。这里“正负”的含义是某物体作为宾语与这个主语
是当物体i作为主语(subject)的时候它所有可能对应的宾语中正负样本置信度差异的最小值。这里“正负”的含义是某物体作为宾语与这个主语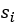 是否存在视觉关系。这里
是否存在视觉关系。这里 代表物体i当前被作为主语考虑,j和k分别用来索引与主语存在关系的正样本宾语
代表物体i当前被作为主语考虑,j和k分别用来索引与主语存在关系的正样本宾语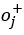 和不存在关系的负样本宾语
和不存在关系的负样本宾语 。
。 和
和 分别代表与主语
分别代表与主语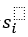 存在关系的所有宾语(即正样本)的集合,和与主语
存在关系的所有宾语(即正样本)的集合,和与主语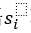 不存在关系的所有宾语(即负样本)的集合。与之相似地,
不存在关系的所有宾语(即负样本)的集合。与之相似地,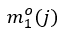 的定义是物体作为宾语时它所有可能对应的主语中正负样本置信度差异的最小值。
的定义是物体作为宾语时它所有可能对应的主语中正负样本置信度差异的最小值。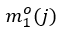 公式中符号的含义与之类似,这里不再赘述。
公式中符号的含义与之类似,这里不再赘述。
第二步是利用第一步的两个差异值来计算一个基于边界的损失:
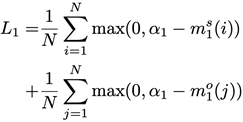
其中 是预先设定的边界值,N是当前的batch size。这个损失的作用是使得上述第一步中的差异值大于预定的
是预先设定的边界值,N是当前的batch size。这个损失的作用是使得上述第一步中的差异值大于预定的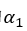 ,只有满足这个条件的时候
,只有满足这个条件的时候 才为0,也就是说我们希望差异值至少是。 熟悉contrastiveloss和triplet loss的朋友应该发现,这个loss的形式和它们很类似。的确,这里的对比形式参考了triplet loss,但不同点在于这个loss受限于图模型的结构,即每一个节点的正负样本都只来自于和当前主语或宾语可能存在关系的节点,而不是像一般triplet loss那样直接在所有节点中搜索正负样本。
才为0,也就是说我们希望差异值至少是。 熟悉contrastiveloss和triplet loss的朋友应该发现,这个loss的形式和它们很类似。的确,这里的对比形式参考了triplet loss,但不同点在于这个loss受限于图模型的结构,即每一个节点的正负样本都只来自于和当前主语或宾语可能存在关系的节点,而不是像一般triplet loss那样直接在所有节点中搜索正负样本。
另一个不同点是triplet loss一般的应用场景是用于训练节点的嵌入(embedding),因此它的输入通常是正负样本的嵌入向量,但这个loss的输入就是原始模型的输出,即每一个视觉关系的置信度,它的目的是通过对比正负样本的置信度把当前视觉关系的最重要的上下文环境反馈给原始模型,从而让原始模型去学习那些能够区分混淆因素的视觉特征。
2. 物体类别相关损失(Entity Class Aware Loss)
该函数与类别无关损失形式类似,唯一的不同在于这个loss在选择正负样本时,样本中物体的类别必须一样:
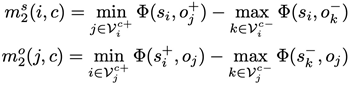
这一步与上一个loss的第一步的唯一区别就是加入了一个额外输入c,它的作用是规定在计算正负样本差异时,所有考虑到的物体必须同属于类别c。这个额外限制迫使模型去注意那些同一个类别的不同物体实例,比如上图中的多个酒杯,并在学习过程中逐渐区分存在视觉关系和不存在视觉关系的实例的特征,因此这个loss是专门设计用来解决上文提出的第一个问题的,即客体实例混淆。
3. 谓语类别相关损失(Predicate Class Aware Loss)
该函数与类别无关损失形式也类似,唯一的不同在于这个loss在选择正负样本时,样本中谓语的类别必须一样:

这里加入了一个额外输入e,它代表的是目前考虑的谓语类别。它的作用是规定在计算正负样本差异时,所有考虑到的样本的视觉关系必须都以谓语连接。这个额外限制迫使模型去注意那些具有同样视觉关系的物体对,比如上图中同样在“play”乐器的三个人,然后在训练过程中学会识别正确的主客体匹配。很显然这个loss是专门用来解决上述的第二个问题,即邻近关系模糊。
关系检测网络(RelDN)
本文同时也提出了一个高效的关系识别网络,结构图如下:

该网络首先用事先训练好的物体识别器识别出所有物体,然后对每一对物体,从图片中提取它们的视觉特征,空间特征以及语义特征。其中空间特征是bounding box的相对坐标,语义特征是两个物体的类别。这三个特征分别被输入进三个独立的分支,并给出三个预测值,最后网络把三个预测值加总并用softmax归一化得到谓语的分布。
值得注意的是,中间这个Semantic Module在前人的工作中也叫Frequency Bias或者Language Bias,它意味着当我们知道主客体的类别时,我们即便不看图片也能“猜”出它们之间的谓语是什么。这个现象其实是符合客观规律的。试想有一张图片里有一个人和一匹马,现在我们不看图片去猜这个人和这匹马有什么关系,我们一般最容易想到“骑”,其次是“拍”或者“牵着”之类的动作,但几乎不可能是“站在”或者“躺在”,因为这与客观常识不符。
如果要构建符合真实世界分布的场景图,那么符合客观规律的常识就不能忽略,因此这个Language Bias不可或缺。
实验结果
1. 成分分析
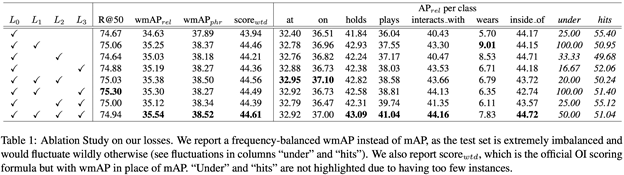
这张表是ablation study,以一步步添加子模块的方式证明三个损失函数都是有效的是传统方法通用的multi-class cross entropy loss,简言之就是softmax层后面接的分类loss,分别是类别无关损失(Class Agnostic Loss),物体类别相关损失(Entity Class Aware Loss)和谓语类别相关损失(Predicate ClassAware Loss)。

这张表对应的实验是,人工随机地挑选出100张图片,这些图片里面广泛地存在着本文开头提到的两个问题,然后分别用不带本文提出的losses的模型和带这些losses的模型去跑这100张图片然后对比结果。很明显,带losses的模型几乎在所有类别上优于不带losses。这个实验直接证明了添加本文提出的losses能够很大程度上解决客体实例混淆和邻近关系模糊这两个问题,从而显著提高模型整体精确度。 除了使用Table2量化地证明losses的有效性,本文同时对模型学到的中间层特征进行了可视化,示例如下:
上图是从验证集(validation set)里挑选的两张图,每张图分别用不带losses和带losses的模型跑一下,然后把最后一个CNN层的特征提出来并画成上图所示的heatmap。可以发现,在左边这张图中不带losses的模型并没有把正确的酒杯凸显出来,而带losses的模型很清晰地突出了被人握着的那个酒杯;在右边这张图中,不带losses的模型突出的位置所对应的物体(鼓)并没有和任何人存在关系,而被人握在手里的话筒却并没有被突出出来。相比之下,带losses的模型则学到了正确的特征。
2. 与最新方法的比较
本文在三个数据集上都做到了state-of-the-art,三个数据集是OpenImages (OI), VisualGenome (VG), Visual Relation Detection (VRD):
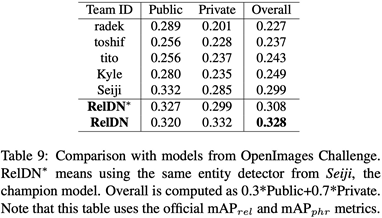
OpenImages(OI)由于数据集较新,之前没有论文做过,所以本文直接和Google在2018年举办的OpenImages Visual Relationship Detection Challenge的前8名进行了比较,结果比冠军高出两个百分点。

在VisualGenome(VG)上,使用和前人相同的settings,本文提出的模型也显著地超过了前人的最好成绩。值得注意的是,这里加和不加losses的区别没有OpenImages上那么大,很大程度上是因为Visual Genome的标注不够完整,也就是说图片中很多存在的视觉关系并没有被标出来,这样导致模型误认为没有标注的物体之间不存在视觉关系,进而把它们认定为负样本。
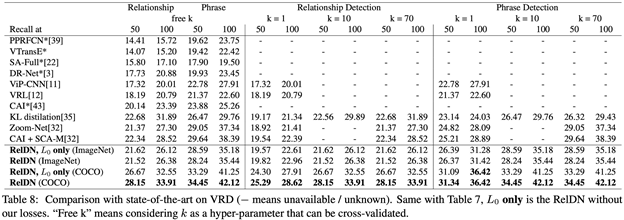
在VRD数据集上我们看到带losses和不带losses的差别相比VG明显了很多,这是因为VRD的标注相对较完整,整体标注质量也相对较好。
作者有话说。。.
最后是我在这个领域做了两年多之后的一些关于视觉关系识别场景图构建的经验和思考,和本文无直接关联,但希望能和大家分享。
1. 前文提到的Language Bias是符合客观世界分布的。如果你希望在你的任务中使用场景图来提取更丰富的信息,而且你的数据集是从真实世界中无偏差地采样出来的自然图片,那么Language Bias应该是有帮助的,但如果你的数据集有偏差,或者是合成数据集(比如CLEVR),那么Language Bias可能不起作用,或者会起到反作用。
2. 在实际应用中,一个可能更好的构建场景图的方式是把所有谓语分成若干大类,然后每个大类分别用一个模型去学,比如可以把谓语分成空间谓语(例如“to the left of, to the right of”),互动谓语(例如“ride,kick, sit on”)和其它谓语(例如“part of”)。
这么做的原因在于不同类型的谓语表达的语义是非常不同的,它们对应的视觉特征的分布也很不同,因此使用独立的若干模型分别去学习这些语义一般会比用一个模型去学习所有语义要好。
3. 在上述的不同类型的关系当中,空间关系是最难识别的一类,因为相比而言,同一个空间关系所对应的视觉分布要复杂很多。
比如,“人骑马”的图片可能看上去都十分相似,但“人在马的右边”的图片却有很多种可能的布局。如果人和马都是背对镜头,那么人会在整个图片的右侧,而如果人和马是面对镜头,那么人会在左侧,而如果人和马是侧对镜头,那么人在图片中会在马的前方或者后方。归根结底,这种空间分布的多元性是由于
1)用2D图片平面去描述3D世界的真实布局具有局限性;
2)Language Bias在空间关系中作用相对小很多,因为空间布局的多样性相对很广,在不看图片的情况下更难“猜”出空间关系是什么。
总而言之,目前空间关系是关系识别和场景图构建的短板,我认为后面工作可以在这个子问题上多加关注。
-
函数
+关注
关注
3文章
4332浏览量
62661 -
计算机视觉
+关注
关注
8文章
1698浏览量
46005 -
数据集
+关注
关注
4文章
1208浏览量
24712
原文标题:将门好声音 | NVDIA提出一种面向场景图解析任务的图对比损失函数
文章出处:【微信号:thejiangmen,微信公众号:将门创投】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
一种面向飞行试验的数据融合框架

RNN的损失函数与优化算法解析
SUMIF函数对比VLOOKUP的优势
YOLOv8中的损失函数解析

SUMIF函数的应用场景分析

利用DX-BST原理图智能工具实现原理图对比的技术方法

C语言函数指针六大应用场景详解
如何利用DX-BST原理图智能工具实现原理图的对比呢?
鸿蒙原生应用开发-ArkTS语言基础类库多线程TaskPool和Worker的对比(一)
verilog function函数的用法
对象检测边界框损失函数–从IOU到ProbIOU介绍





 工商网监
工商网监
评论