 怎样在不使用Spark应用程序的情况下使Spark Core运行
怎样在不使用Spark应用程序的情况下使Spark Core运行

步骤1:先决条件
Spark Core
这可能看起来很明显,但是假设使一个问题成为现实。该包装中包含USB微型连接器电缆,因此请确保也能触及该电缆。
通过WiFi连接到互联网的计算机
Core不能仅期望与本地WiFi交互。
串行通信软件
Windows :腻子
Mac和Linux :屏幕
USB串行驱动程序
这是Windows特定的问题。如果您已经在同一Windows机器上安装了Teensy甚至是Arduino,那么在通过USB连接Core时,您不需要做任何特别的事情。
请确保通过USB连接到笔记本电脑时,Core闪烁中速蓝色
Core中间的大RGB LED两侧各有两个按钮。如果USB微型插头面向12点钟,则“模式”按钮位于9点钟(即左侧),而“重置”按钮位于3点钟(右侧)。
如果Core呈绿色常亮,则它可能具有较旧的WiFi凭据。按住“模式”按钮10秒钟,它将清除其现有的WiFi凭据,然后重新启动。
步骤2:收集基于Web的激活的详细信息
请注意,大多数说明可从Spark网站获得。但是有一些跳跃的地方,因此将所有内容按执行顺序并显示在一个屏幕上要方便得多:
A)使用以下方法在https://www.spark.io/signup上创建一个帐户电子邮件地址。
注意事项:输入电子邮件地址时,请三重检查。如果拼写错误,Spark团队将没有自动解决系统。他们只能通过电子邮件解决问题,虽然他们非常有礼貌并且对此有所了解,但仍会花费一些时间;
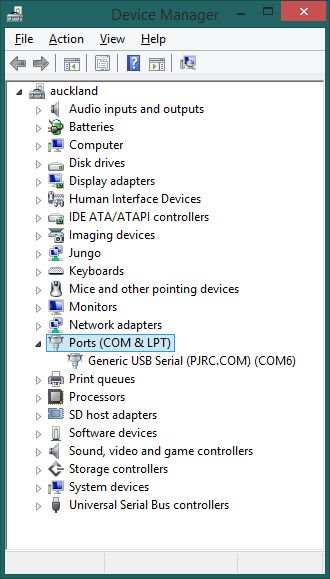
B)将Core插入笔记本电脑的USB端口并发现其端口-
Windows:
打开设备管理器(devmgmt.msc);
转到“端口(COM和LPT)”,然后将其扭曲打开(如果尚未打开)。查找Spark或“通用USB串行”条目并记下COM号。
Mac:
上拉终端(打开一个Finder并搜索“/Applications/Utilities/Terminal”);
运行以下命令:ls -ltr /dev/cu.*
时间戳最近的项目将是列表中的最后一项。它的文件名应以“ cu.usbmodem”开头,然后包含几位数字。
Linux:
打开一个终端,然后运行:ls -l /dev/ttyACM*
C)使用发现的端口-
Windows:
打开腻子;
选择“ Serial”作为连接类型,将“ COM#”作为地址,将COM端口号指定为“#”,将9600作为速度。
Mac和Linux:
键入以下内容以确认通信程序在您的路径中-which screen
类型screen /dev/[cu.usbmodem*|ttyACM*] 9600
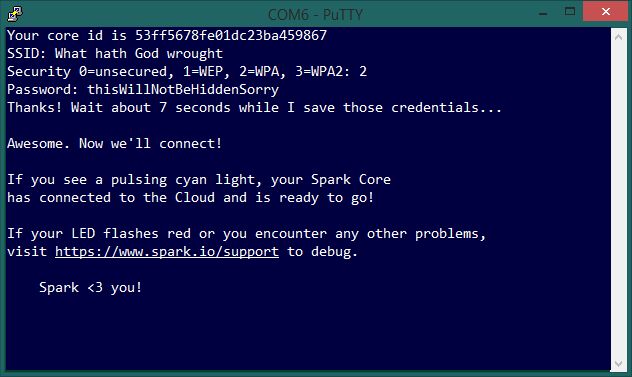
D)获取核心的标识符(序列号)并将其链接到WiFi-
在通信会话中输入“ i”;
它将以24个字符的十六进制唯一ID答复,最有可能以53或54开头,例如Your core id is 53ff6c06fe01dc23ba459867
将ID号复制为文本。在腻子中,只需单击并拖动ID即可将其复制。 将其粘贴到文本文件中以确保安全;
返回到通信会话,然后键入“ w”。核心将切换为稳定的蓝灯,而通信会话将提示输入SSID(区分大小写),安全性和密码;
成功的尝试应类似于此页面上的最后一个屏幕截图。
步骤3:使用网站激活:将序列号链接到Spark帐户
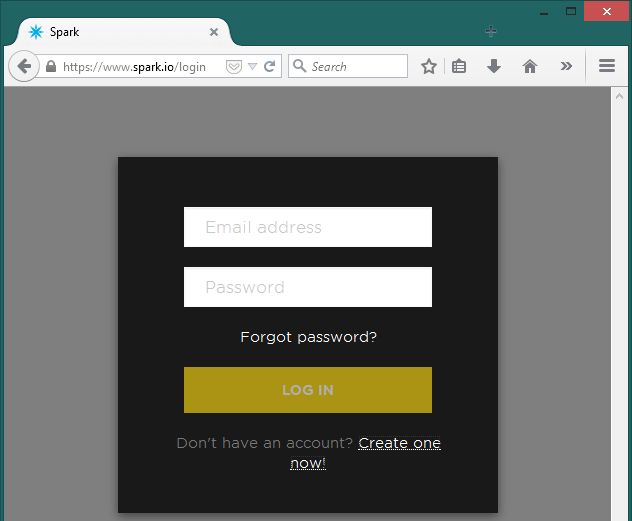
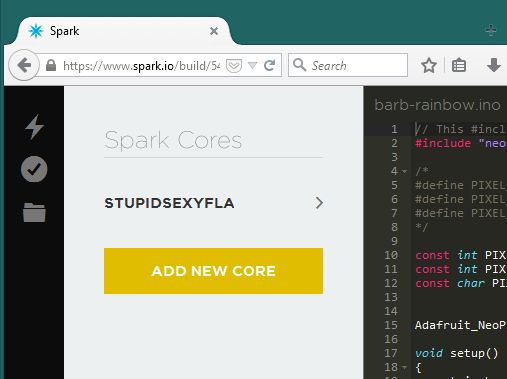
登录回到Spark IDE网站:https://www.spark.io/login;
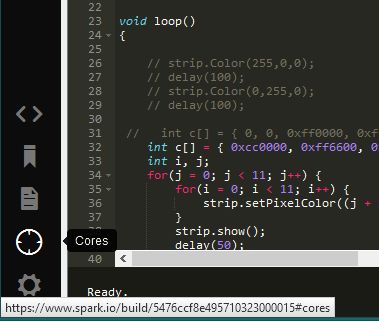
在IDE的左窗格中,从底部查找第二个图标(它将看起来像一个目标)。将鼠标悬停在其上将显示“ Cores”一词。单击此按钮;
单击黄色的“添加新核心”按钮。这将启动一个弹出窗口;
从通信会话中粘贴ID号,然后单击“声明!”。按钮;
最后一步将提供一个半随机名称。接受默认值或对其进行更改,然后单击以命名。
步骤4:回到Web IDE并开始编码
在Mac和Linux中,WiFi步骤成功后,屏幕会话应自动关闭;如果不是,请使用 control-a 然后使用 control-k 从其中取消屏幕会话。在Windows中,关闭Putty会话是安全的。
现在是时候编写代码并使Spark Core投入工作了:
https://www.spark.io/login
已经熟悉IDE的人应该很自在。同样的人可能还会想知道为什么仍然连接到USB端口的设备的所有代码都需要从附近的Web服务器发送给它的代码。
一个答案是Spark Core是只寻找USB电源。只要Core仍与笔记本电脑连接到同一WiFi路由器,就可以在范围内的任何位置对其进行重新编程。
另一个答案是安装Spark CLI工具和Spark Dev IDE,或者甚至设置了单独的Spark Source环境。这些将需要等待将来的Instructable。
责任编辑:wv
-
Core
+关注
关注
0文章
175浏览量
44470
发布评论请先 登录
如何在不影响 Core1 的情况下在LS1021A中单独重置 Core0?
基于Arm架构的NVIDIA DGX Spark平台构建离线语音助手系统

首届中国NVIDIA DGX Spark黑客松大赛开启报名
NVIDIA DGX Spark助力高等教育领域重大项目
NVIDIA DGX Spark桌面级AI超级计算机助力开发者构建AI模型
如何在DGX Spark上运行NVIDIA Omniverse

耐能携手Spark迪维科推动AI技术在垂直产业的应用发展
NVIDIA DGX Spark系统恢复过程与步骤

NVIDIA DGX Spark助力构建自己的AI模型

在NVIDIA DGX Spark平台上对NVIDIA ConnectX-7 200G网卡配置教程
NVIDIA DGX Spark快速入门指南

NVIDIA DGX Spark新一代AI超级计算机正式交付
NVIDIA DGX Spark桌面AI计算机开启预订

使用NVIDIA GPU加速Apache Spark中Parquet数据扫描



评论