 英创信息技术在WEC7主板上启动VFP硬件浮点处理器
英创信息技术在WEC7主板上启动VFP硬件浮点处理器
关于ARM指令
英创公司开发的基于WEC7的工控主板目前包括3种型号:
| 主板型号 | CPU架构 | 其他重要技术指标 |
| ESM6802 | Cortex-A9双核 | ESMARC主板架构体系,主推产品型号 |
| ESM3354 / ESM3352 | Cortex-A8 | ESMARC主板架构体系,主推产品型号 |
| EM335x / EM3352 | Cortex-A8 | 成熟产品型号 |
在使用英创的WEC7主板时,用户需要使用Visual Studio 2008(简称VS2008)来开发其应用程序。尽管Cortex-A8和Cortex-A9处理器均支持性能更高的ARMv7指令集,但微软在VS2008中所仍然使用ARMv4i指令集的通用arm编译器(编译器版本号为:15.00.20720)。而A8、A9处理器所带的矢量浮点处理器(Vector Float-Point Processor)都需要在ARMv7指令下才能正常启动运行。换句话说,在ARMv4i指令集下,对浮点的处理仍然是采用软件仿真包来实现,而没有用到高端ARM处理器自带的硬件浮点处理器。这对涉及大量浮点处理应用的客户来说是很遗憾的事。
本文将以ESM3354为测试平台,介绍在现有VS2008基础上实现硬件浮点处理的方法。
编译器及SDK的准备
我们为需要浮点处理的客户准备了ARMv7编译工具以及基于ARMv7工具的SDK,具体如下表所示:
| ARMv7编译工具包 | ms-armv7-compiler.tar 编译器版本 15.01.50304.03 |
| ESM335x SDK | ESM335XARMV7SDK.msi |
| ESM6802 SDK | ESM6802ARMV7SDK.msi |
客户需要首先安装新的AMRv7的SDK,ARMv7的SDK与原来的ARMv4i的SDK是独立并行的,并不需要卸载原来的SDK。安装完成后,再把ARMv7编译器工具包解压到本地硬盘上,例如D:\ms-armv7-compiler。
建立测试程序1
打开VS2008,建立测试程序3354_armv7_t1,平台(platform)选择ESM335XARMV7SDK,用户可以看到其指令集显示为armv7:
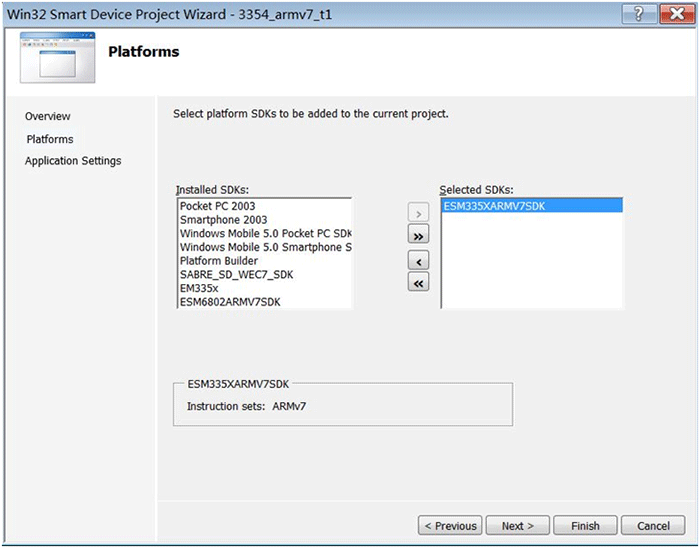
点击,选择Console Application,
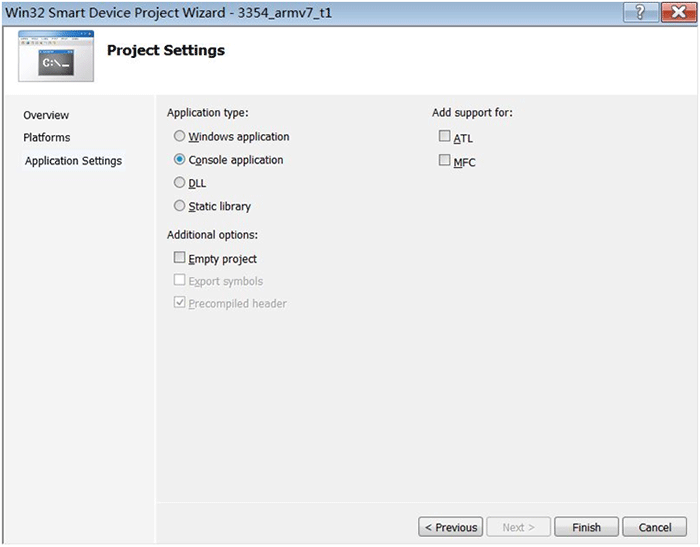
最后点击,进入代码窗口。以下是测试的完整代码,客户可拷贝粘贴到所生成的代码窗口区域中。
// 3354_armv7_t1.cpp : Defines the entry point for the console application.
//
#include"stdafx.h"
int_tmain(intargc, _TCHAR* argv[])
{
doublef1 = 2.200002;
doublef2 = 2.200001;
doubleans = 1.0;
longiterations = 5 * 1000 * 1000;
DWORDdwStartTick, dwEndTick;
_tprintf(TEXT("Microsoft compiler version: %d\r\n"),_MSC_FULL_VER);
_tprintf(TEXT("ARM instruction set: %d\r\n"),_M_ARM);
if(argc > 1)
{
f1 = _wtof(argv[1]);
}
if(argc > 2)
{
f2 = _wtof(argv[2]);
}
if(argc > 3)
{
iterations = _wtoi(argv[3]) * 1000 * 1000;
}
dwStartTick = GetTickCount();
wprintf(L"f1=%f f2=%f loop=%d starting...%d\r\n", f1, f2, iterations, dwStartTick);
for(inti=0; i
{
ans *= f1;
ans /= f2;
}
dwEndTick = GetTickCount();
wprintf(L"ans = %f %d loop/msec end...%d\r\n", ans, (int)(iterations/(dwEndTick - dwStartTick)), dwEndTick);
return0;
}
设置编译器路径
准备好测试程序后,首先需要把ARMv7编译器加入到VS2008中,具体设置方法是在菜单栏中选择 Tools -> Options -> Projects and Solutions -> VC++ Directories,然后选择页面的Platform栏目中选择ESM335XARMV7SDK(ARMv7),最后在路径栏目中添加新路径如下:
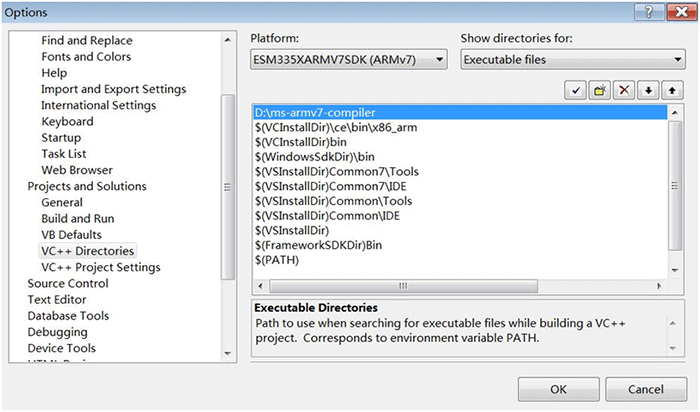
编译器路径设置,对一个平台只需要设置一次。也就是对本机说,当创建其他基于ESM335XARMV7SDK的应用程序时,都不需要再重复设置编译器路径了。
设置应用程序编译链接选项
从工具栏点击Project -> Properties -> C/C++ -> Command Lines,添加ARMv7指令选项以及浮点处理选项:“/QRarch7 /QRfpe- /arch:VFPv3-D32”如下:
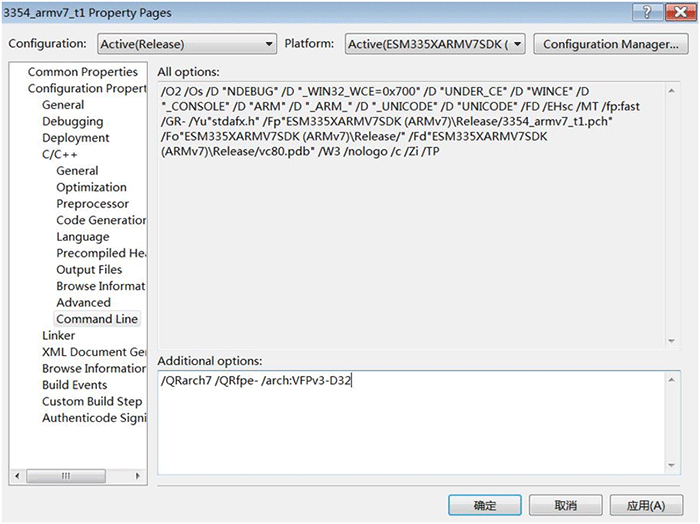
各个选项的功能微软的大致解释如下:
●/QRarch7// -> ARMv7 Architecture
●/QRfpe-// -> Enable Hardware Floating-Point Targeting (Compact 7)
●/arch:VFPv3-D32// -> 使用VFP内部的32个64位寄存器
由于ARMv7编译器并不知道VS2008的基本环境库路径,也需要通过菜单添加:Project -> Properties -> Linker -> General,在Additional Library Directories栏加入:
“C:\Program Files (x86)\Microsoft Visual Studio 9.0\VC\ce\lib\armv4i”
设置的界面为:

设置完成后,就可Build测试程序,并下载至目标板上运行。该测试程序在ESM335x和EM335x两个系列的主板上均可正常运行:

这里“19455 loop/msec”表示每ms的循环次数,是反应计算能力的主要参数。
测试结果比较
按构造上述测试程序的方法,可方便地构造一个使用VS2008缺省编译器(ARMv4i)的t1程序,以进行比较。进一步地,我们在t1主循环中增加一行超越函数计算,构成测试程序t2:
for(inti=0; i
{
ans *= f1;
ans /= f2;
ans = cos(ans); //t2新加代码
}
为了更全面比较测试结果,我们还在Linux版本上运行相同测试程序,进行编译器的横向对比。
整个测试的综合结果如下表所示:
| t1 | t2 | |
| CL-15.00.20720 (armv4i) | 6858 loop/ms | 644 loop/ms |
| CL-15.01.50304.03 (armv7) | 19455 loop/ms | 687 loop/ms |
| Improvement | 2.83 (+183%) | 1.07(+7%) |
| Gcc-4.4.1+soft (armv7-a) | 1921 loop/ms | 470 loop/ms |
| Gcc-4.4.1+vfp (armv7-a) | 13857 loop/ms | 587 loop/ms |
| improvement | 7.2 (+620%) | 1.25 (+25%) |
上表的改进栏目中是ARMv7运行速度相对ARMv4i速度的倍数,括号内为提高的百分比。测试程序t1评估的是常规的浮点计算,使能VFP后,是有明显改进的;而且Linux版本的相对改进更大。但加入超越函数后,VFP的硬件优势就几乎全部丧失了。我们理解ARM的VFP与传统x86的协处理器(Co-processor)在对超越函数的处理上还是差别很大的,基本上还是采用多项式级数来合成的,本来设置VFP的主要目的也是面向数字滤波、图形处理这类以乘加为主要特色的浮点处理,对数学超越函数的处理确实不在行。
小结
对需要大量使用乘加类型浮点处理的应用,采用本文的方法启动ARMv7指令及VFP浮点处理器,是能够大大改善应用程序的性能的。对超越函数的处理,需要转换成表格方式处理,而规避直接的计算,以保持程序总的处理性能。
微软在VS2008配置的ARMv4i编译器,其性能明显优于Linux平台中使用的开源GCC编译器,估计这也是微软保留这款编译器的原因之一。关于ARMv7指令相对ARMV4i指令的性能比较,第三方公司已做详细测试,感兴趣的客户可向英创索取相关文档。
有需求客户可向英创索取ARMv7编译器以及相应的SDK,英创公司的技术支持邮箱为:support@emtronix.com。
点此阅读第三方测试报告:Building WEC7 application with ARMv7 compiler - TI Benchmark。
-
Linux
+关注
关注
87文章
11296浏览量
209364 -
嵌入式主板
+关注
关注
7文章
6085浏览量
35303
发布评论请先 登录
相关推荐
迅为3A6000_7A2000开发板龙芯全国产处理器与龙芯 3A5000完全兼容
中科创达荣获2024年软件和信息技术服务优秀企业
迅为3A6000_7A2000核心主板龙芯全国产处理器LoongArch架构

盛显科技:在拼接处理器上配置混合矩阵的步骤是什么?
信创国产化背景下的工控主板发展现状
龙芯ITX主板GM7-3601搭载龙芯3A5000处理器的工控主板

处理器的定义和种类









 工商网监
工商网监
评论