 英创信息技术精简ISA总线Linux编程 – Part2简介
英创信息技术精简ISA总线Linux编程 – Part2简介
精简ISA总线接口是一种8-bit宽度的双向并行扩展总线,其特点是地址数据分时复用8位总线,加上4条总线控制信号,即可实现对外部数据的快速读写。若再使能一条总线时钟信号(共13条信号),就可实现高达10MB/s以上的数据传输。精简ISA总线作为英创主板的特色功能之一,在ESM6802、ESM7000、ESM7100、ESM335x等多款型号中均有配置。
关于对精简ISA总线接口的应用编程的基本方法,请参考《精简ISA总线编程 – Part 1》。本文介绍由应用程序启动基于DMA的数据块读写,即MemCpy方式的DMA。采用DMA进行ISA总线数据传送的目的,是为了降低高速传送大量数据时的CPU开销。MemCpy方式的DMA是指软件线程启动DMA,然后该线程挂起等待DMA操作完成。在多线程环境中,其他线程即可在DMA执行过程中得以并行运行。
ISA总线信号定义如下:
| 信号及说明 | PIN# | 信号及说明 | |
| RESET_B,硬件复位 | 1 | 2 | ISA_ADVn,地址锁存控制信号 |
| ISA_AD0,地址数据总线,LSB | 3 | 4 | ISA_AD4,地址数据总线 |
| ISA_AD1,地址数据总线 | 5 | 6 | ISA_AD5,地址数据总线 |
| ISA_AD2,地址数据总线 | 7 | 8 | ISA_AD6,地址数据总线 |
| ISA_AD3,地址数据总线 | 9 | 10 | ISA_AD7,地址数据总线,MSB |
| MSLn,支持多模块挂接总线 | 11 | 12 | ISA_WEn,数据写控制信号 |
| GPIO9,可选作为IRQ | 13 | 14 | ISA_RDn,数据读控制信号 |
| GPIO8,可选作为IRQ | 15 | 16 | ISA_CSn,片选控制信号 |
| GPIO25,可选作为IRQ | 17 | 18 | VDD_5V0,+5V供电 |
| GPIO24 / ISA_BCLK,同步时钟ISA_BCLK | 19 | 20 | GND,电源信号地 |
本文以下部分,将以ESM7000 Linux平台为例,介绍具体的编程方法。
DMA总线访问API
应用启动DMA数据传输,需要使用数据结构struct isa_transfer的传递参数和数据,structisa_transfer的结构定义如下:
|
structisa_transfer { void *rx_buf; /* != NULL: buffer for bus read */ void *tx_buf; /* != NULL: buffer for bus write */ unsigned len; /* buffer length in byte */ unsigned offset; /* offset,port address on isa bus */ unsigned inc; /* = 0: fixed offset, = 1: offset+1 after r/w */ }; |
每一个总线周期的操作只能是读或写,因此在isa_transfer结构中只能有一个buffer指针不为NULL。以下是执行32字节数据块写的代码,写入地址为0x4040。顺序的数据可方便时序的观察。
|
unsignedchargbuf[64 * 1024]; unsignedint i, value; structisa_transfer t; unsignedchar *pBuf8; // write data block memset(&t, 0, sizeof(structisa_transfer)); t.offset = 0x4040; t.len = 32; // max len<= 16KB = 16 * 1024 t.tx_buf = gbuf; // fill data value = 0x55; // initialvalue pBuf8 = (unsignedchar*)t.tx_buf; for(i = 0; i *pBuf8 = (unsignedchar)(value + i); pBuf8++; } isa_write_buf(fd, &t); |
注意offset必须是0x4000 – 0x40FF,驱动程序才会启动MemCpy方式的DMA传输。若从0x4040读入32字节数据,实现代码则为:
|
unsignedchargbuf[64 * 1024]; structisa_transfer t; // read data block memset(&t, 0, sizeof(structisa_transfer)); t.offset = 0x4040; t.len = 32; // max len<= 16KB = 16 * 1024 t.rx_buf = gbuf; isa_read_buf(fd, &t); |
DMA传输总线时序说明
图1、图2分别为MemCpy方式DMA读总线时序概要、写总线时序概要。
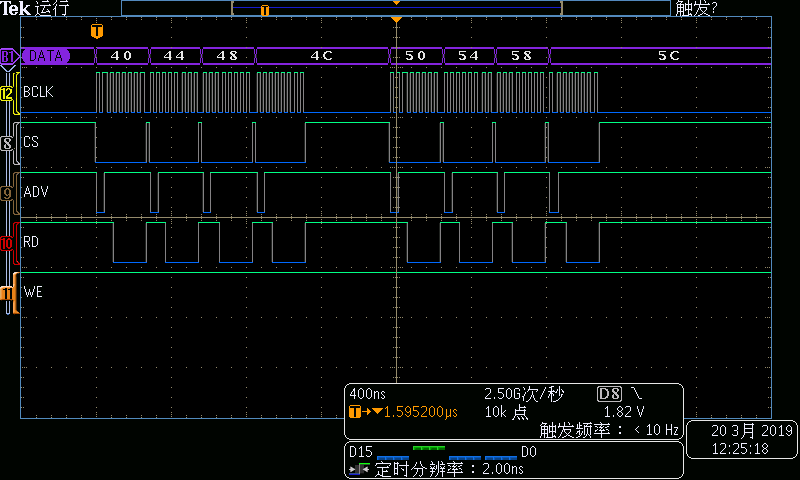
图1DMA读总线时序
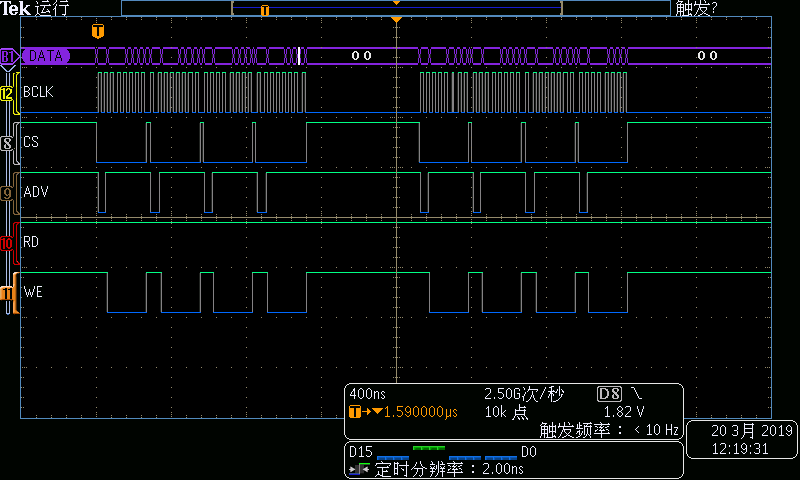
图2DMA写总线时序
从上面的时序可见,DMA也是16字节一组,连续4个总线周期组成,每组之间有一定间隔。DMA读操作的总线速率大约为11.8MB/s,DMA写操作的总线速率大约为11.2MB/s。
展开DMA写的总线时序可看到:
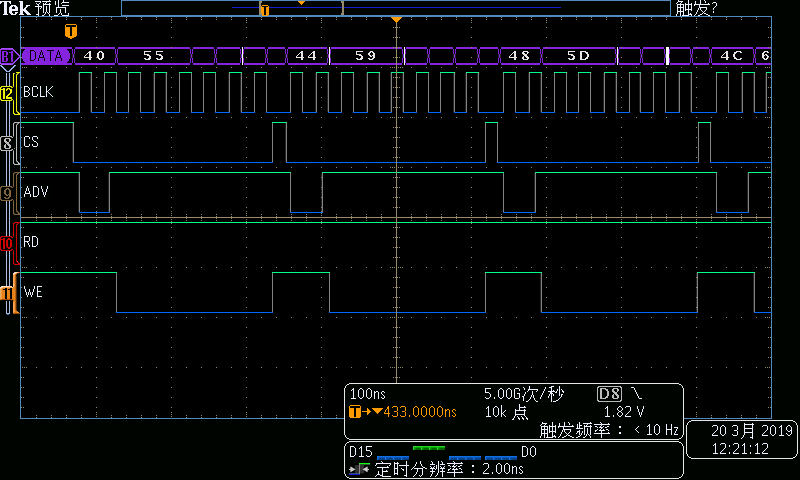
图3DMA写总线时序—第1组起始部分
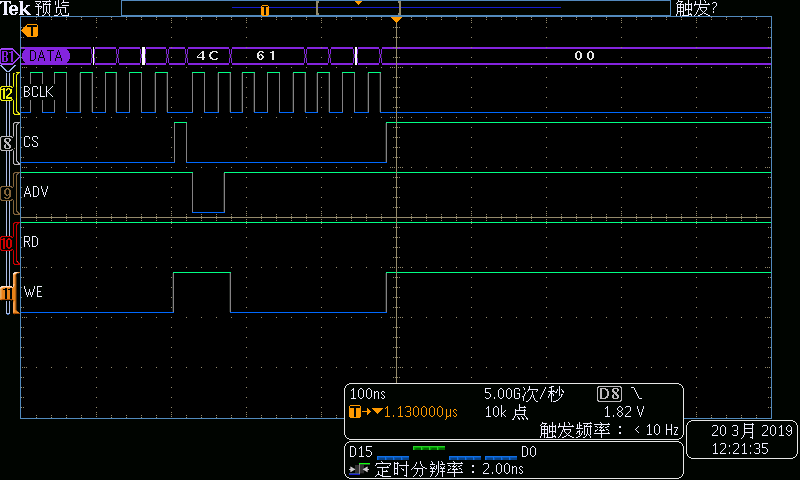
图4DMA写总线时序—第1组结束部分
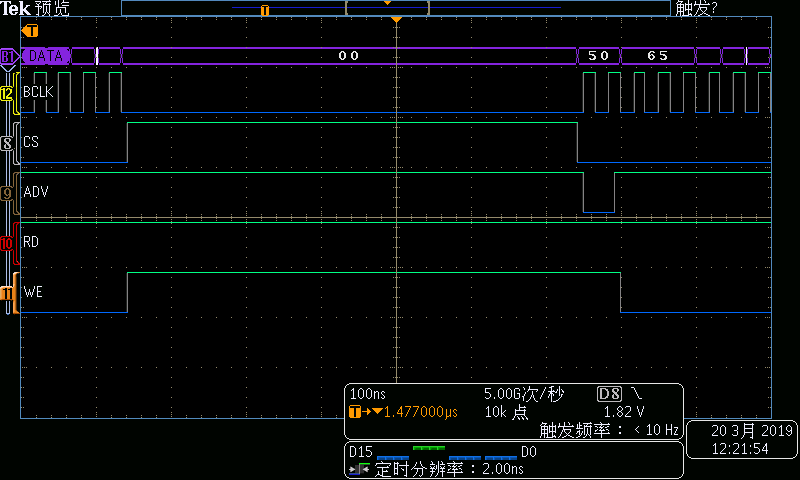
图5DMA写总线时序—第2组起始部分
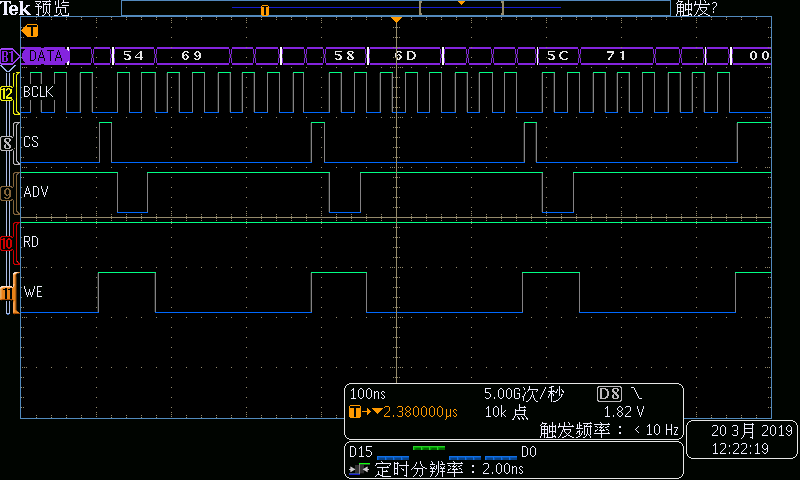
图6DMA写总线时序—第2组结束部分
在每个总线周期中,地址递增4。这样当传输长度超过256字节时,ISA地址及会循环。这意味着当采用MemCpy方式DMA进行数据传输时,数据端口译码不能采用普通的组合电路地址译码方式,而必须采用BCLK+ ADV#的同步电路译码方式。具体方式就是每个周期的第一个BCLK下降沿锁存到有效ADV#,标志同步周期的开始,之后经过连续7个BCLK下降沿后同步周期结束。
DMA传输时的CPU负载率
与纯软件的同步总线周期传输相比,DMA传输最大的优点是有效降低了总线传输的CPU开销,使应用程序的其它线程能同步运行。基本的测试代码如下:
|
#define MAX_DMA_LEN (16*1024) unsignedchar gbuf[64 * 1024]; unsignedint i, count = 1; struct isa_transfer t; unsignedchar *pBuf8; longdouble a[4], b[4], loadavg; //for CPU utilization calculation FILE *fp; constchar *bus_type_name[] = {"async-cpu","async-dma-mem","async-dma-ext","sync-cpu","sync-dma-mem","sync-dma-ext"}; // fill data pBuf8 = (unsignedchar*)gbuf; for(i = 0; i < MAX_DMA_LEN; i++){ *pBuf8 = (unsignedchar)(value + i); pBuf8++; } memset(&t, 0, sizeof(struct isa_transfer)); // get initial values for calculating CPU usage in % fp = fopen("/proc/stat","r"); fscanf(fp,"%*s %Lf %Lf %Lf %Lf",&a[0],&a[1],&a[2],&a[3]); fclose(fp); // write data block loop while(count) { i = (count < MAX_DMA_LEN)? count : MAX_DMA_LEN; t.offset = offset; t.len = i; t.tx_buf = gbuf; isa_write_buf(fd, &t); count -= i; } // get end values for calculating CPU usage in % fp = fopen("/proc/stat","r"); fscanf(fp,"%*s %Lf %Lf %Lf %Lf",&b[0],&b[1],&b[2],&b[3]); fclose(fp); // calculate CPU usage in % loadavg = ((b[0]+b[1]+b[2]) - (a[0]+a[1]+a[2])) /((b[0]+b[1]+b[2]+b[3]) - (a[0]+a[1]+a[2]+a[3])); loadavg *= 100; i = (offset >> 12) & 0xf; printf("%s bus write, CPU utilization is : %Lf%%\n",bus_type_name[i], loadavg); |
使用100M数据长度来测试总的CPU负载率的情况如下:
| 模式 | MemCpy DMA | 纯软件操作 |
| 同步总线读 | 6.01% | 50.3% |
| 同步总线写 | 5.71% | 50.0% |
ESM7000使用的是具有双核CPU的iMX7D,总CPU负载率50%,表示某个CPU核的负载已经100%。DMA的使用对提高系统整体的性能是非常显著的。
进一步可测试应用层实际的传输速率如下:
| 模式 | 传输速率 | CPU负载 |
| MemCpy DMA同步总线读 | 8.67MB/s | 6.01% |
| MemCpy DMA同步总线写 | 7.93MB/s | 5.71% |
若把每个周期传输的字节数从4个提升到8个,传输率则可有50%的提升。
-
Linux
+关注
关注
87文章
11302浏览量
209427 -
嵌入式主板
+关注
关注
7文章
6085浏览量
35314
发布评论请先 登录
相关推荐
飞腾助力首届教育信息技术应用创新大赛圆满落幕
有方科技参编的信息技术团体标准发布
龙芯中科助力2024首届教育信息技术应用创新大赛成功举办
拓维信息参与牵头组建!长沙新一代信息技术产教联合体正式获批

中科创达荣获2024年软件和信息技术服务优秀企业
信创国产化背景下的工控主板发展现状
加速鲲鹏落地!拓维信息信创迁移工具荣获鲲鹏原生开发技术认证
梯度科技入选2023年信息技术应用创新解决方案名单
中软国际信创服务助力大连信创产业发展
翼辉信息入选2023年信息技术应用创新解决方案名单

光庭信息荣膺武汉市侨届“科创之星”称号
龙芯中科三项信创方案入围工信部2023年信息技术应用创新应用示范案例名单

RX78M组 EtherCAT ETG.5003示例程序固件信息技术






 工商网监
工商网监
评论