 使用LSTM模型对智能家居里的活跃设备进行预测
使用LSTM模型对智能家居里的活跃设备进行预测
今年 8 月份,香港中文大学张克环教授研究组在 arxiv 上公布了一篇文章,展示了他们组对于智能家居隐私性的研究。文章作者尝试使用 LSTM 模型对智能家居里的活跃设备进行预测。该预测可以使服务提供商(ISP)猜测用户正在家里使用什么类型的设备,从而有可能对拥有不同设备的用户有不同的商业推广手段。

在此之前,已经有不少人做了相关的研究,但他们的研究大都是基于纯净的实验室环境,很难移植到复杂的现实环境中。作者通过分析真实世界中的 IoT 设备以及公开数据集,发现物联网设备的流量与桌面流量和移动流量相比有以下区别:
同一类别的设备有相似的流量模式(下图为两种语音助手识别语音命令时的流量变化情况)
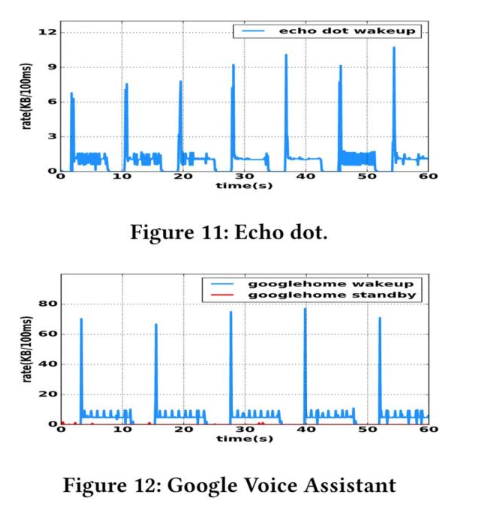
设备都有「心跳」传输来保证网络和设备的联通,不同设备的「心跳」模式不同不同设备传输协议比例不同(下图展示了 IoT 设备和非 IoT 设备的协议使用情况)
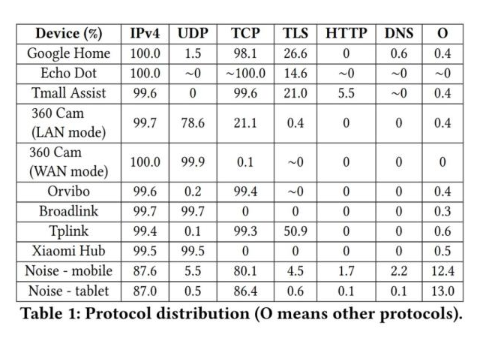
作者认为,这些特征表明即使是在复杂场景下,而且具有一定的安全设备(NAPT 和 VPN)也能鉴别不同的 IoT 设备。由于现有的数据集不满足作者的要求,因此作者团队自己搭建了一个数据采集的系统。
实验数据收集
该系统包含 10 个 IoT 设备和 4 个非 IoT 设备,系统内设备如下图所示。
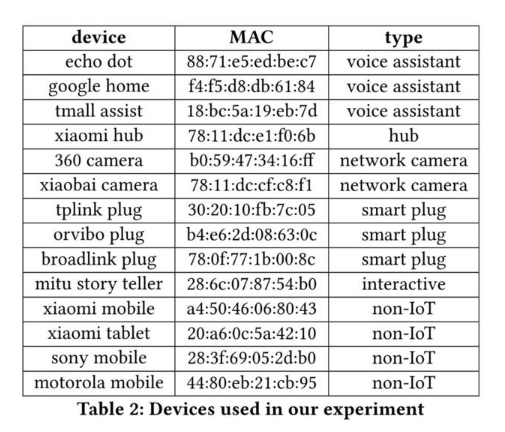
作者准备在三个环境下收集流量信息:单一设备环境、多设备嘈杂环境 (使用 NAPT 技术) 以及 VPN 环境。
首先介绍一下 NAPT 技术和 VPN 技术。NAPT 是一种网络地址转换技术,与 NAT 不同,NAPT 支持端口的映射。NAT 实现的是本地 IP 和 NAT 的公共 IP 之间的转换,因此本地局域网中同时与公网进行通信的主机数量就受到 NAT 的公网 IP 地址数量的限制。而 NAPT 克服了这种缺陷——NAPT 技术在进行 IP 地址转换的同时还对端口进行转换,因此只要 NAT 中的端口不冲突,就允许本地局域网的多台主机利用一个 NAT 公共 IP 就可以同时和公网进行通信。
VPN 通常用于互连不同的网络,以形成具有更大容量的新网络。它是基于 IP 隧道机制,不同子网中的主机可以相互通信,并且可以通过认证和加密保密传送的信息。
在生成流量的过程中,作者采用了两种触发方式:手动触发和自动触发,手动触发可以模拟真实环境下的人机交互,自动触发可以减轻实验者的负担。在自动触发模式下,作者使用 Monkey Runner 对需要用 APP 进行交互的 IoT 设备进行触发;对于语音助手等 IoT 设备,作者通过重复播放口令来进行触发。
手动触发模式只在多设备场景下使用,在该模式下,作者通过随机进出房间来对房间内的试验设备进行触发。该种方式与自动触发相比,更具有随机随机性,从而有助于模型的泛化。
整个流量收集过程持续 49.4 个小时,共收集 4.05GB 的数据,共包含 7223282 条有效通信包。
数据预处理
在进行实验评估之前,作者先对数据进行了预处理——将初始数据转换为模型能够处理的数值向量。
数据预处理过程可分为两部分,特征提取和制作数据包的标签。在特征提取过程中,共提取了五个特征,分别是端口 (dport)、协议 (protocol)、方向 (direction)、帧长 (frame length)、时间间隔 (time interval),并将这五个特征组成一维向量,如下图所示。
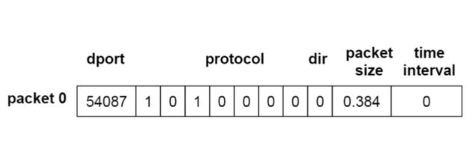
在给数据包制作标签的过程中,针对在 VPN 环境下较难打标的问题,作者发现了如下规律,从而能够较精确地给数据包打标签:
经过 VPN 处理后,数据包的体积会变大不同体积的数据包经过 VPN 加密后体积相同VPN 会引起数据包传输延迟,这个延迟通常短于 0.02 秒
模型选择
在模型选择上,作者共选取了三个模型:随机森林(基线模型)、LSTM 模型以及 BLSTM(双向 LSTM)模型。由于随机森林无法直接学习离散值,作者对端口的特征值进行了独热编码处理。
对于 LSTM 模型,作者也对输入模型的数据进行了处理,他将多个连续向量进行了分组并组成流量窗,如下图所示。

作者使用的 LSTM 模型如下图所示。该模型由多个基础模块组成,每个基础模块又包含有 Embedding 层、LSTM 层、全连接层以及 Softmax 层。
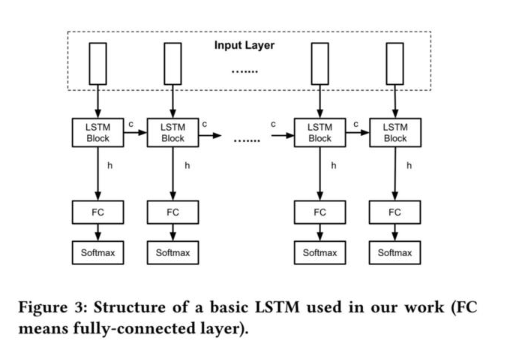
由于 LSTM 模型在学习上下文信息时只能查看数据包的「过去」,因此作者又使用了 BLSTM 模型。BLSTM(双向 LSTM)是 LSTM 的扩展,它通过组合从序列末尾移动到其开头的另一个 LSTM 层来利用来自「未来」的信息。作者使用的 BLSTM 模型见下图。
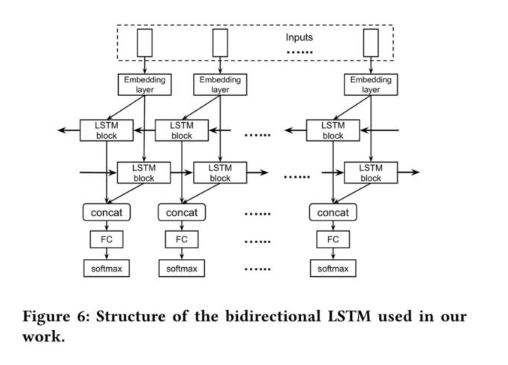
模型评估
数据集
共有两种数据集,Dataset-Ind 以及 Dataset-Noise。每种数据集又有两个版本:NAPT 版本和 VPN 版本。Dataset-Ind 数据集包含来自 10 个单独 IoT 设备的流量数据,这些数据被组成流量窗。Dataset-Ind 数据集共有 32760 个流量窗。
Dataset-Noise 数据集中的数据也是以流量窗的形式存在,与 Dataset-Ind 数据集不同的是,该数据集中的每个流量窗都是由多个设备的数据包组成。Dataset-Noise 数据集包含 114989 个流量窗。
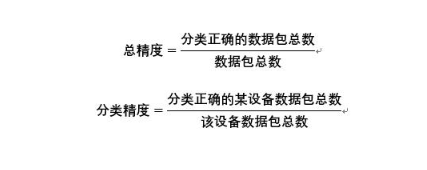
评估指标
总精度(overall accuracy) 和分类精度(category accuracy)
评估结果
在 Datatset-Ind 数据集下的评估结果如下表所示。从表中可以看出,LSTM 模型的精度普遍高于随机森林模型。
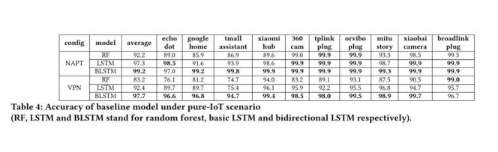
随后,作者又在 Dataset-Ind 数据集下研究了流量窗大小对实验精度的影响,结果显示,流量窗越大,实验精度越高。因此,在接下来的实验中,流量窗的大小默认为 100。
在 Dataset-Noise 数据集下的评估结果如下图所示。由图中可以看出,随机森林模型在该数据集下的总精度下降明显,在 NAPT 环境下总精度为 84.5%,在 VPN 环境下的总精度为 67.6%。而 LSTM 模型在 NAPT 环境下表现较好,在 VPN 环境下表现较差。
作者对随机森林模型和 LSTM 模型精度降低的现象进行了分析,认为随机森林模型精度降低的原因是多个 IoT 设备和非 IoT 设备同时使用一个端口进行通信,使得该模型分类失败;而 LSTM 模型精度下降的原因,作者认为是由稀疏流量造成的:因此在 VPN 协议的极端情况下,智能插头(图中 orvibo, tplink)产生的流量包可以在流量窗口中被稀释到不到 3%。令这两款智能插头不能被识别出。
结论
根据实验结果,作者认为即使是在加密和流量融合的情况下,物联网设备的网络通信也会产生严重的隐私影响。人们应该进行更多该方面的研究,以更好地了解智能家居网络中地隐私问题并缓解此类问题。
-
物联网
+关注
关注
2914文章
45014浏览量
377908 -
智能家居
+关注
关注
1931文章
9619浏览量
186684 -
数据集
+关注
关注
4文章
1210浏览量
24865
发布评论请先 登录
相关推荐
人脸识别技术在智能家居中的应用有哪些
Zigbee智能家居的未来发展趋势
如何使用Python构建LSTM神经网络模型
LSTM神经网络在时间序列预测中的应用
图为大模型一体机新探索,赋能智能家居行业
人工智能如何强化智能家居设备的功能
扫码模组在智能家居领域中的应用

提升智能家居安全,芯科科技分享CPMS独家方案
智能家居包含哪些人工智能应用
智能家居系统设计方案
LSTM模型的基本组成
基于英飞凌MCU PSoC™ 6的 Matter智能家居解决方案





 工商网监
工商网监
评论