 Spark SQL性能实现17.7倍的提升,是如何做到的
Spark SQL性能实现17.7倍的提升,是如何做到的
(文章来源:砍柴网)
Apache Spark是专为大规模数据处理而设计的快速通用的计算引擎,常用来构建大型、低延迟的数据分析应用程序。Spark一个主要特点在于,其能够在内存中进行计算,这使得其数据分析效率往往高于其它计算引擎,但是,服务器内存资源的限制也使得其性能的扩展存在着一定的瓶颈,在超大规模负载中无法充分发挥其利用内存进行计算的性能优势。
某全球领先的语音识别服务提供商是最早将Spark应用到生产环境的团队之一,该公司的语音云通过几千台服务器构成的云计算平台向用户提供多样的、实时语音处理能力,日均服务终端用户超过15亿,日增数据超过100TB。2014年该公司基于Spark和AI技术构建了DMP大数据平台(用户数据管理平台)。DMP平台的主要功能就是收集、存储、分析和挖掘庞大的用户数据,以实现广告精准投放。
Spark在该公司的大数据平台中主要用于海量用户数据分析,每天支撑稳定运行的Spark SQL统计分析指标和SQL脚本有几千个。但是在将Spark SQL用于海量用户数据分析的过程中,仍然面临着一些痛点,这些都限制了该公司语音云的数据分析能力。
Spark的性能不仅受到CPU、内存、网络、磁盘等硬件设备的制约,而且Spark SQL目前还不支持索引,也严重影响了Spark SQL在进行大规模数据分析时的性能,索引能够提升数据检索的效率,降低硬盘的IO瓶颈。
随着数据量越来越大,即席分析的需求越来越强烈,即席查询是用户根据用户自己的需求,灵活选择查询条件,系统能够根据用户的选择生成响应的统计报表和结果集;在数据仓库和大数据分析系统中,即席查询使用的越多,对系统的性能要求也就越高,如果内存能够缓存更多的热点数据,能够极大的提升即席查询处理速度并降低响应延迟。
数据既有随机读的需求(即席查询-Ad-hoc),又有全表扫描的需求(机器学习);机器学习就是通过特定算法从海量的历史数据中学习规律,从而对新的样本进行分析并对未来做出预测,在模型训练的过程中会产生大量的中间结果数据,通常情况下需要将中间结果数据持久化到文件系统上,如果内存能够缓存更多的中间结果数据,可以提升模型训练的速度。
(责任编辑:fqj)
-
互联网
+关注
关注
54文章
11103浏览量
102988 -
ai技术
+关注
关注
1文章
1256浏览量
24241
发布评论请先 登录
相关推荐
QPS提升10倍的sql优化
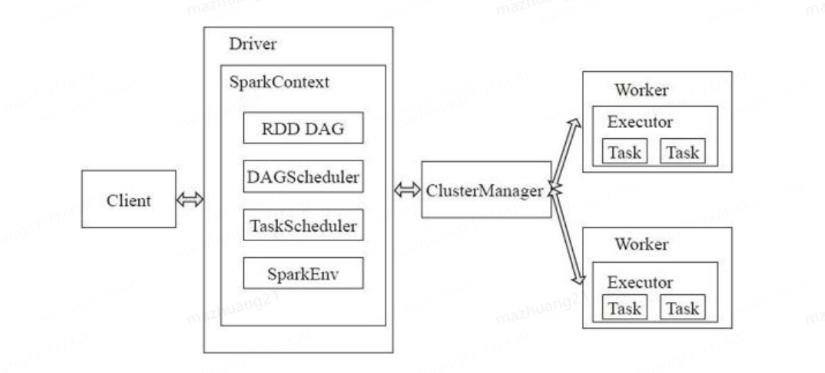
spark运行的基本流程
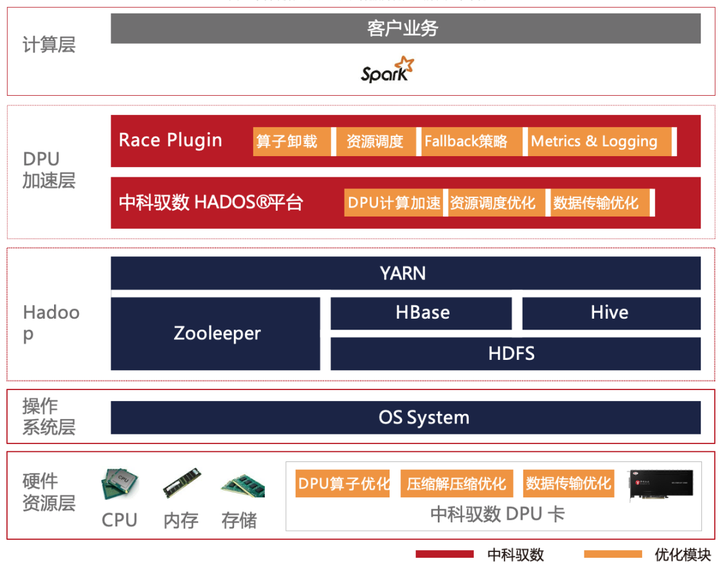
Spark基于DPU的Native引擎算子卸载方案

Flow Computing引领CPU性能革命:PPU技术实现百倍性能提升
STM32在PWM输出模式中,如何做到PWM移向输出?
多路电源并联输出如何做到均流不倒灌?
龙芯:自主研发CPU提升性能,单核通用性能提高20倍
Spark基于DPU Snappy压缩算法的异构加速方案
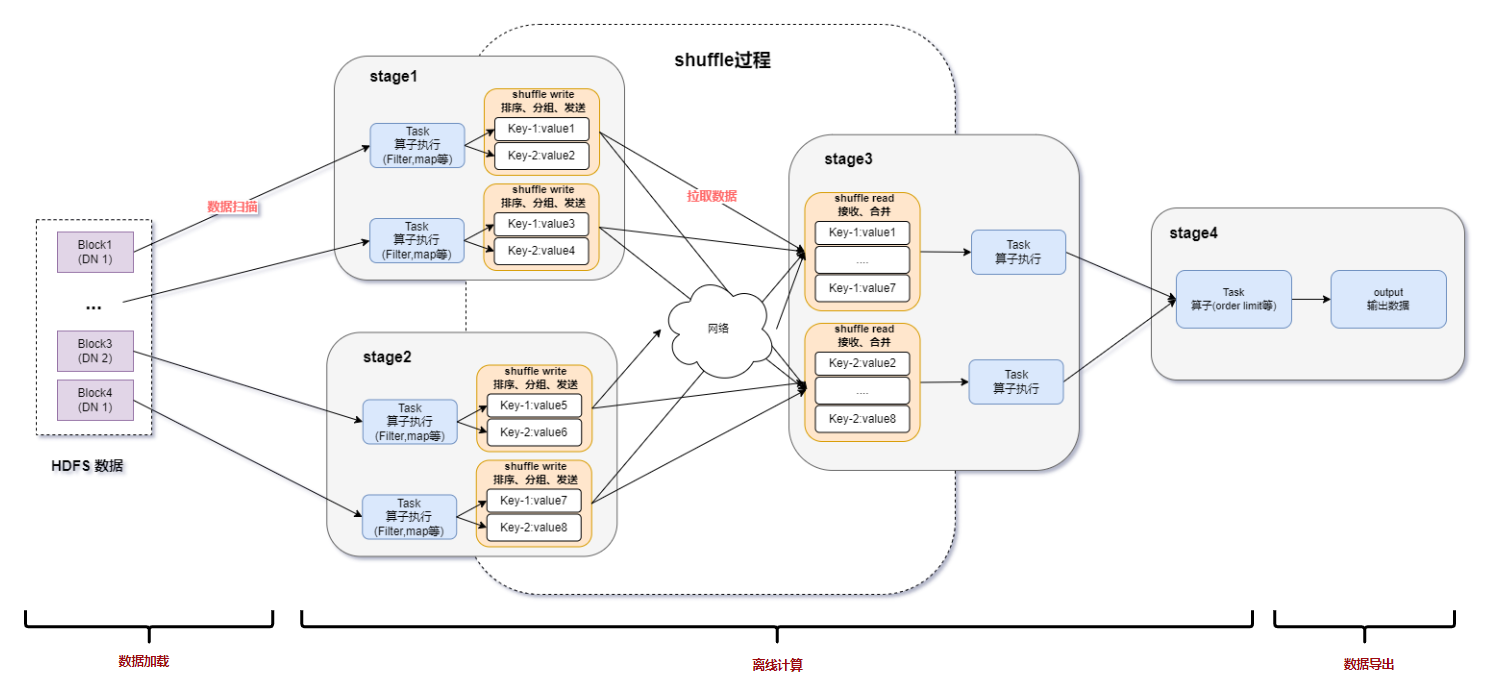
基于DPU和HADOS-RACE加速Spark 3.x
光伏户用如何做到低成本获客?
工业级连接器如何做到高抗冲击性?选款一定要了解这几点






 工商网监
工商网监
评论