 一种基于视频流的自监督特征表达方法
一种基于视频流的自监督特征表达方法
编者按:著名心理学家Paul Ekman和研究伙伴W.V.Friesen,通过对脸部肌肉动作与对应表情关系的研究,于1976年创制了“面部运动编码系统”,而利用微表情的“读心术”正是基于这一研究体系。由于该领域有限的数据集和高昂的标注成本,有监督学习的方法往往会导致模型过拟合。本文中,将为大家介绍中科院计算所VIPL组的CVPR2019新作:作者提出了一种基于视频流的自监督特征表达方法,通过利用巧妙的自监督约束信号, 得到提纯的面部动作特征用于微表情识别。
1.研究背景
面部运动编码系统 (FACS,Facial Action Coding System)从人脸解剖学的角度,定义了44个面部动作单元(Action Unit,简称AU)用于描述人脸局部区域的肌肉运动,如图1所示,AU9表示“皱鼻”,AU12表示“嘴角拉伸”。各种动作单元之间可以自由组合,对应不同的表情。如“AU4(降低眉毛)+AU5(上眼睑上升)+AU24(嘴唇相互按压)”这一组合对应“愤怒”这一情绪状态。
面部动作单元能够客观、精确、细粒度地描述人脸表情。然而昂贵的标注代价在很大程度上限制了AU识别问题的研究进展,其原因在于不同的AU分布在人脸的不同区域,表现为不同强度、不同尺度的细微变化。具体来说,为一分钟的人脸视频标注一个AU,需要耗费一名AU标注专家30分钟。目前学术界已发布的AU数据集只包含了有限的采集对象,以及有限的人脸图像(如2017年CMU发布的GFT数据集有96个人,约35,000张人脸图像)。
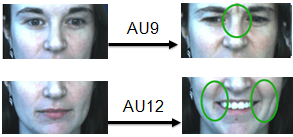
图1. 面部动作单元示例
当前已有的工作多采用人脸区域分块、注意力机制等方法学习人脸局部区域的AU特征,这类方法在训练阶段需要利用精确标注的AU标签,由于目前业界发布的AU数据集人数及图像总量不足,采用监督学习方法训练得到的模型往往呈现出在特定数据集上的过拟合现象,这无疑限制了其实际使用效果。
我们提出了一种能够在不依赖AU标签的前提下,从人脸视频数据中自动学习AU表征的方法(Twin-Cycle Autoencoder,简称TCAE)。TCAE用于后续的AU识别任务时,只需要利用训练数据训练一个分类器即可,显著减少了所需的训练数据,并提升了模型的泛化能力。
2.方法概述
如图2所示,该方法以两帧人脸图像(源图,目标图)之间的运动信息为监督信号,驱使模型提取出用于解码运动信息的图像特征。这个方法的理念在于,模型只有感知并理解了人脸图像中各个面部动作单元的状态(AU是否激活),才能够将源图的面部动作转换为目标图像的面部动作。
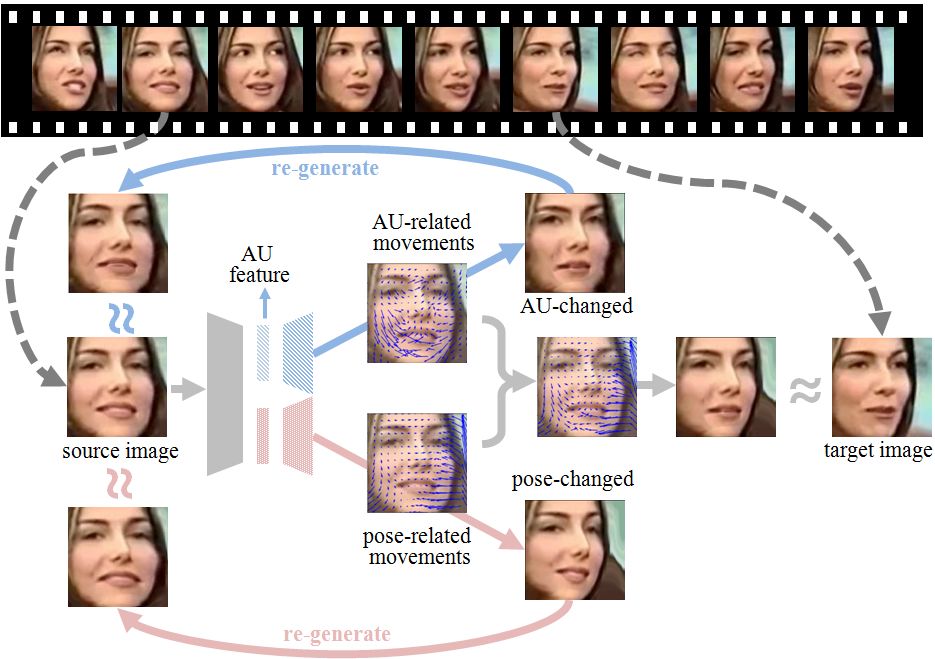
图2. TCAE 设计图
考虑到两帧人脸图像之间的运动信息包含了AU以及头部姿态的运动分量,TCAE通过利用巧妙的自监督约束信号,使得模型能够分离出AU变化引起的运动分量,以及头部姿态变化引起的运动分量,从而得到提纯的AU特征。与其他监督方法,TCAE可以利用大量的无标注人脸视频,这类视频是海量的。与半监督或者弱监督方法相比, TCAE采用了自监督信号进行模型训练,避免了对数据或者标签的分布做出任何假设。
3.算法详解
如图3所示,TCAE包含四个阶段,分别是特征解耦,图像重建,AU循环变换,以及姿态(pose)循环变换。
给定两张人脸图像,TCAE在特征解耦阶段使用编码器得到每张图像的AU特征以及姿态特征,随后,两帧图像的AU特征被送入AU解码器,用于解码出AU位移场;两帧图像的姿态特征被送入姿态解码器,用于解码出姿态位移场。考虑到AU的变化是稀疏的,且AU位移场的数值与姿态位移场相比更小,我们为AU位移场添加了L1约束:
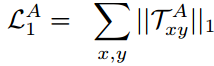
在目标图重建阶段,TCAE通过线性组合AU位移场和pose位移场,得到源图和目标图之间的整体位移场,进行图像重建:
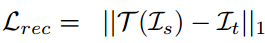
在AU循环变换阶段,仅变换了AU的人脸图像被重新变换到源图,由此我们获得一个像素层面的一致性约束:
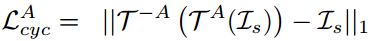
另外,对于变换了AU的人脸图像,其AU特征应该接近目标图像的AU特征,其姿态特征应该和源图的姿态特征一致,由此我们获得一个特征层面的一致性约束:
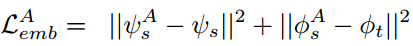
同理,在pose循环变化阶段,我们同样可以获得类似的像素及特征层面的一致性约束:
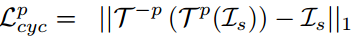
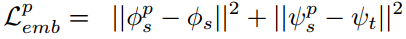
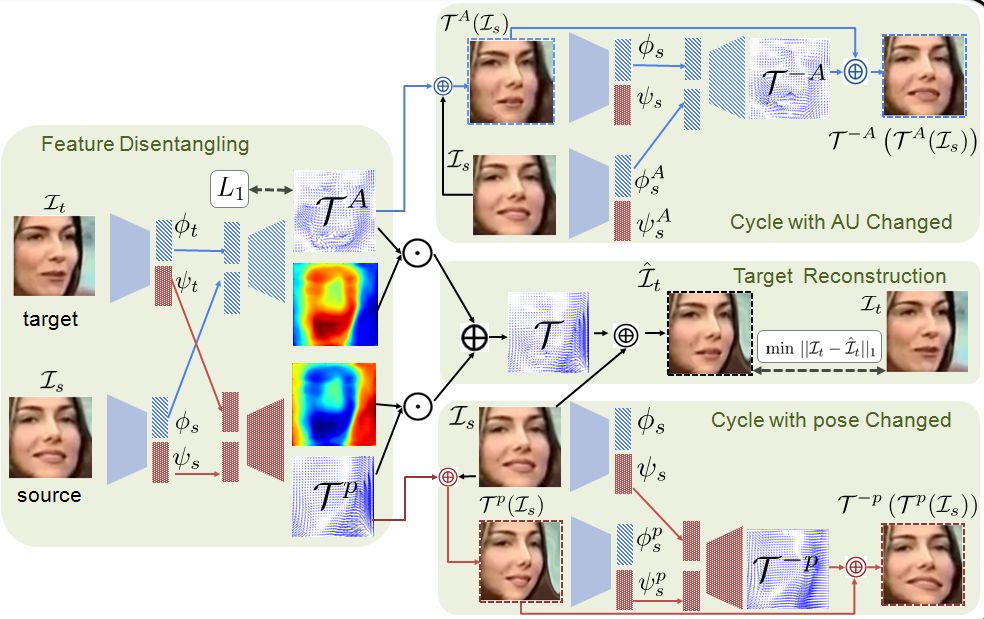
图3. TCAE的四个阶段示意图,四个阶段分别是特征解耦,图像重建,AU循环变换,以及pose循环变换。
4.实验结果
多个数据集上的实验证明,TCAE能够成功提取出人脸图像的AU及姿态特征。如图4所示,给定两张人脸图像(源图,目标图),TCAE能够仅仅改变源图的AU或者头部姿态。可视化的AU位移场呈现出运动方向的多样性。
在AU识别任务上,TCAE取得了与监督方法可比的性能。表1及表2的结果表明,TCAE明显优于其他自监督方法。在GFT数据集(该数据集存在大范围的头部姿态变化)上,TCAE的性能优于其他监督方法。
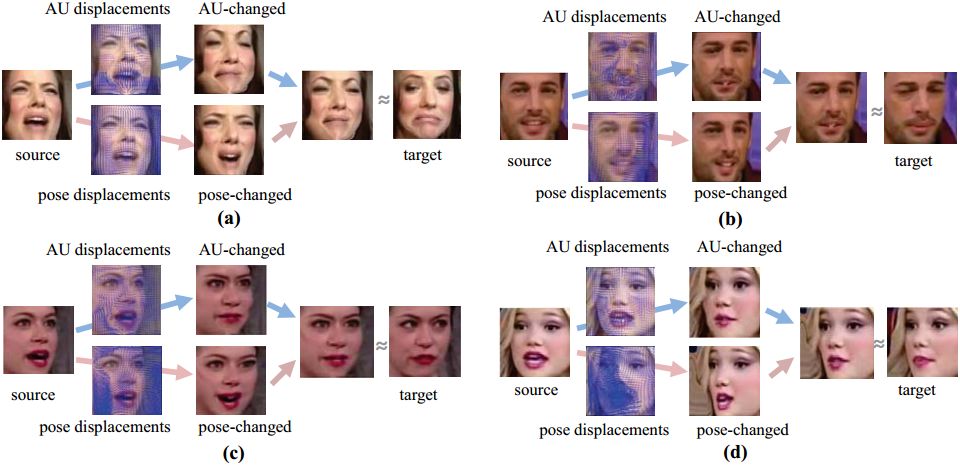
图4. 可视化结果

表1. BP4D及DISFA数据集评测结果
(评测标准:F1 值 (%))

表2. GFT及EmotioNet数据集评测结果
(评测标准:F1 值 (%) )
5.总结与展望
TCAE通过自监督的方法学习到了鲁棒的AU表征,实验证明该AU表征是鲁棒的,适用于AU分类任务的。可视化结果表明,TCAE具有潜在的人脸表情编辑价值。另外,TCAE在训练阶段使用了大量的无标签数据(近6000人,约10,000,000张图像),由此可见使用自监督方法训练模型时数据利用的效率需要进一步提高,这一点在BERT的实验分析中也得到了印证:Good results on pre-training is >1,000x to 100,000 more expensive than supervised training。
-
解码器
+关注
关注
9文章
1158浏览量
41332 -
图像
+关注
关注
2文章
1091浏览量
40747 -
数据集
+关注
关注
4文章
1215浏览量
25066
原文标题:【CVPR2019】“识面知心”——基于自监督学习的微表情特征表达
文章出处:【微信号:deeplearningclass,微信公众号:深度学习大讲堂】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
一种基于点、线和消失点特征的单目SLAM系统设计

一种基于基础模型对齐的自监督三维空间理解方法
纸基微流控芯片的加工方法和优势
一种基于因果路径的层次图卷积注意力网络

数据准备指南:10种基础特征工程方法的实战教程

一种创新的动态轨迹预测方法
一种简单高效配置FPGA的方法
特征工程实施步骤

华芯微电子取得一种过流保护电路专利
一种无透镜成像的新方法






 工商网监
工商网监
评论