 基于无监督学习和图学习的大数据挖掘
基于无监督学习和图学习的大数据挖掘
在IJCAI-2019期间举办的腾讯TAIC晚宴和Booth Talk中,来自TEG数据平台的张长旺向大家介绍了自己所在用户画像组的前沿科研结果:
1. 非监督短文本层级分类;
2. 大规模复杂网络挖掘和图表示学习。
其所在团队积极与学术界科研合作,并希望有梦想、爱学习的实力派加入,共同研究和应用半监督/弱监督/无监督学习、小样本学习、大规模复杂网络挖掘和图表示学习等做大数据挖掘。
科研结果1:非监督短文本层级分类
首先以下用户和AI算法的对话,显示了现实业务中使用现有监督文本分类算法的遇到的一些困境和问题:
算法需要海量训练数据
算法模型用户不可控
算法不能很好的适应类目的变化
我们分析现有监督算法的主要问题在于没有真正的知识, 没有对于文本和类目的真正的理解。现有算法只是在学习大量人工标注训练样本里面的模式。为了解决这个问题,我们启动了一个叫做: 基于关键词知识与类目知识的非监督短文本层级分类的探索项目。
项目的主要思想是引入关键词和类目两种知识来帮助算法理解关键词和类目的含义。然后基于知识进行文本的分类和标注。关键词知识主要来自3个方面包括:关键词的网络搜索上下文、关键词的百科上下文、关键词到类目词的后验关联概率。我们提出类目语义表达式来支持用户表达丰富的类目本身和类目之间的关系的语义。这两样知识的引入帮助算法摆脱了对于大量人工标注训练样本的依赖,同时算法分类的过程做到了人工可理解,人工可控制。
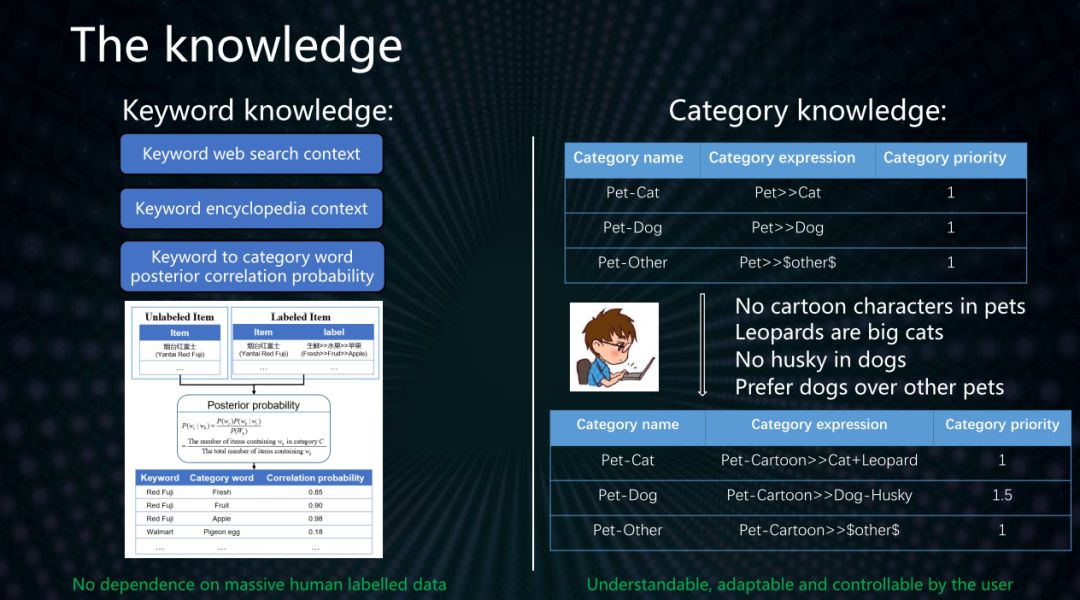
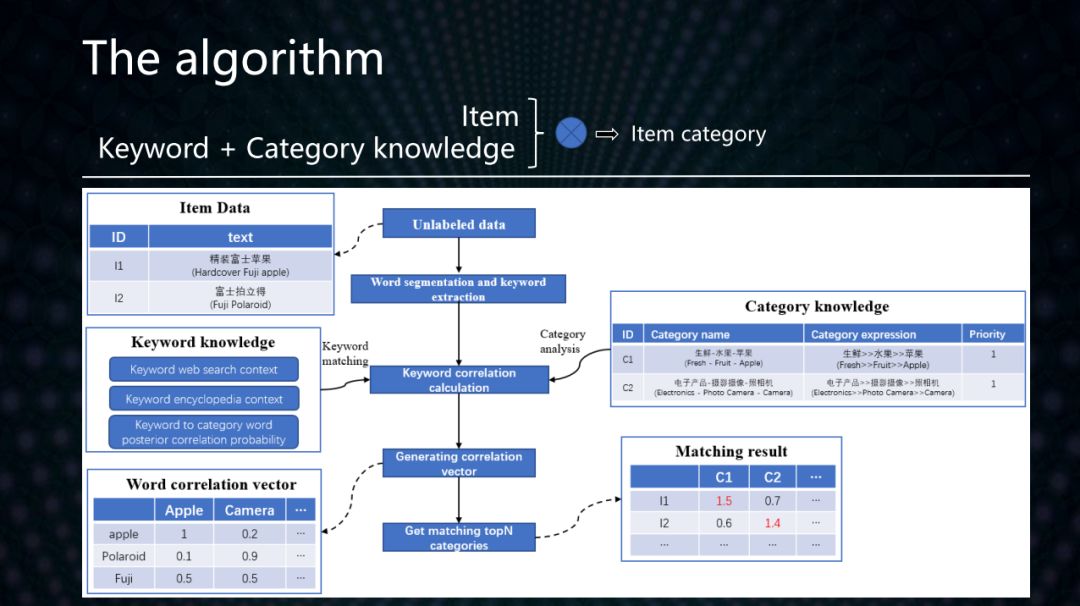
基于关键词和类目知识的无监督文本层级分类算法流程如下:
对文本提取关键词
根据关键词知识计算关键词到类目词的相关度词向量
根据关键词的相关度词向量计算文本的相关度词向量
根据文本的相关度词向量和类目语义表达式计算文本与每个类目的匹配度
每个文本被分为与之匹配度最高的类目
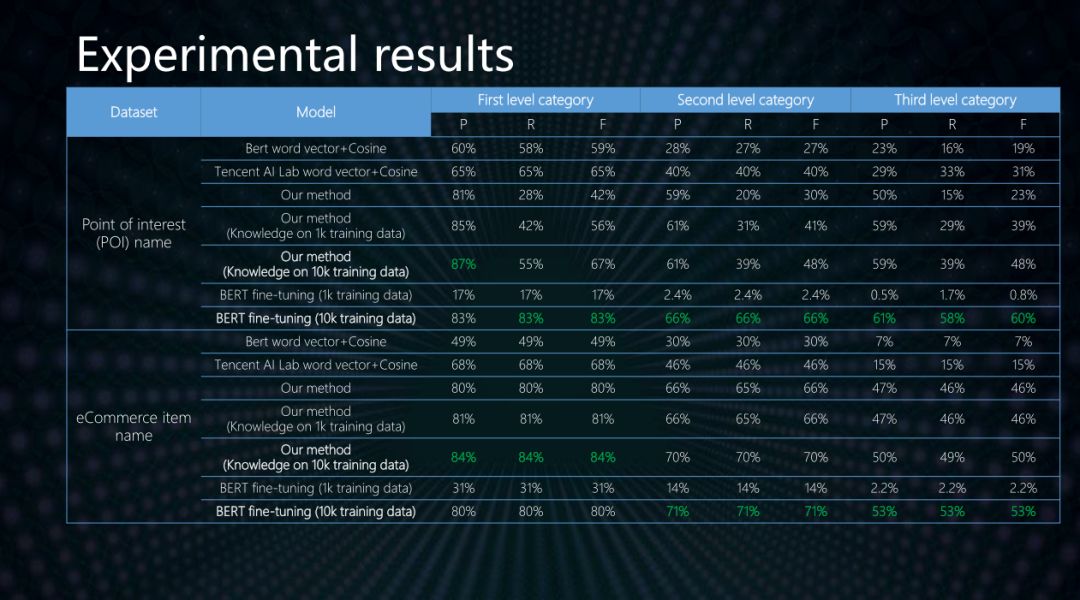
通过在两个文本分类数据集合上面的实验,我们发现,我们自研的算法能够在没有训练样本的情况下提供质量可用的结果,其一级类目准确率能够达到80%,并且明显高于现有其他非监督算法。
科研结果2:大规模复杂网络挖掘和图表示学习
Network Representation Learning 或者说 Graph Embedding 是复杂网络最新的研究课题,意在通过神经网络模型,把图结构向量化,为节点分类、链路预测、社团发现等挖掘任务提供方便有效的特征,以克服图结构难以应用到机器学习算法中的难题。
本次我们在IJCAI发表的学术论文“Identifying Illicit Accounts in Large Scale E-payment Networks - A Graph Representation Learning Approach”创新性提出结合边属性的图卷积神经网络模型,弥补了现有算法无法利用边属性为节点分类提供更多信息的不足。
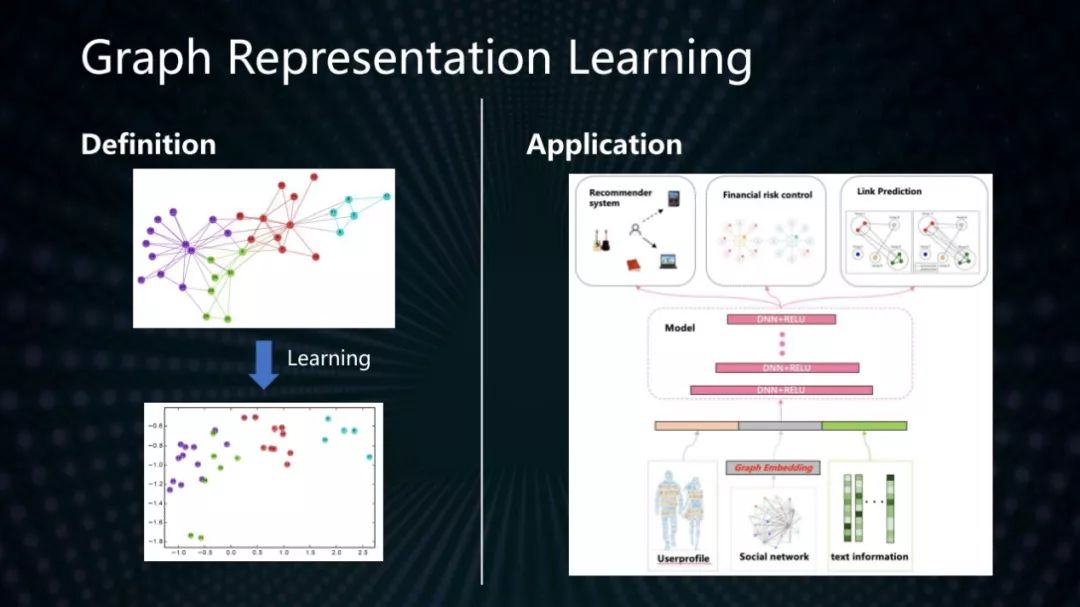
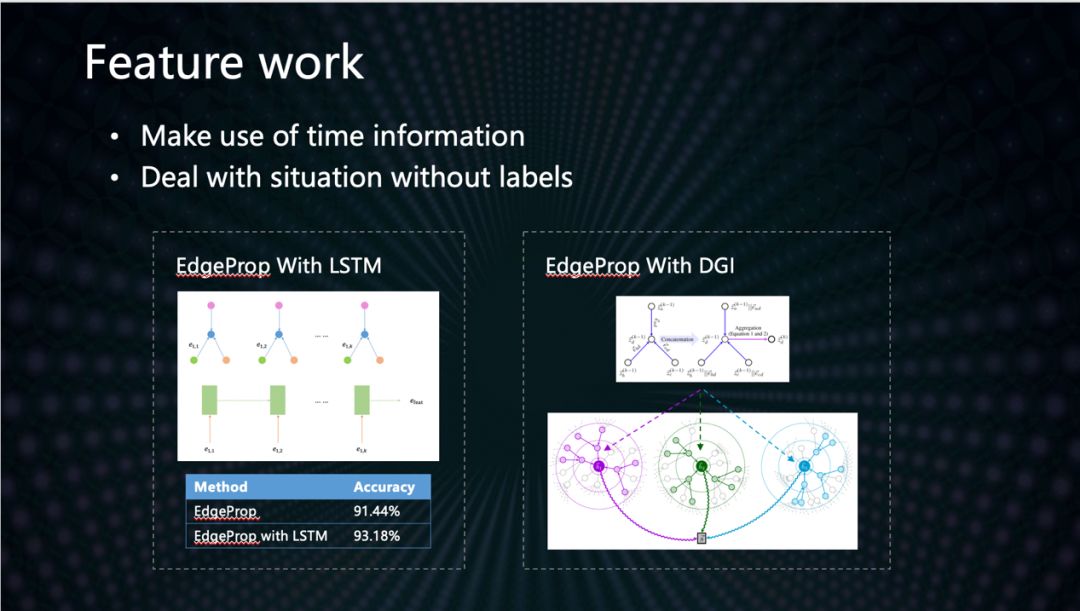
现有的图学习算法,绝大部分都忽视了边上信息的价值。在这里我们提出了一种可以把边的信息传输到节点表示结果的改进的GCN算法。算法主要思路是在做GCN里面周边邻居节点向量的聚合计算之前,把每个节点连接边的Embedding向量拼接在对应邻居节点的Embedding向量后面。实验显示,我们的算法对于金融分类问题具有更优的结果。我们团队正在进一步优化模型,正在研发利用时序的GCN模型,以可以利用边的时序交互信息,从而更好的表示动态网络。

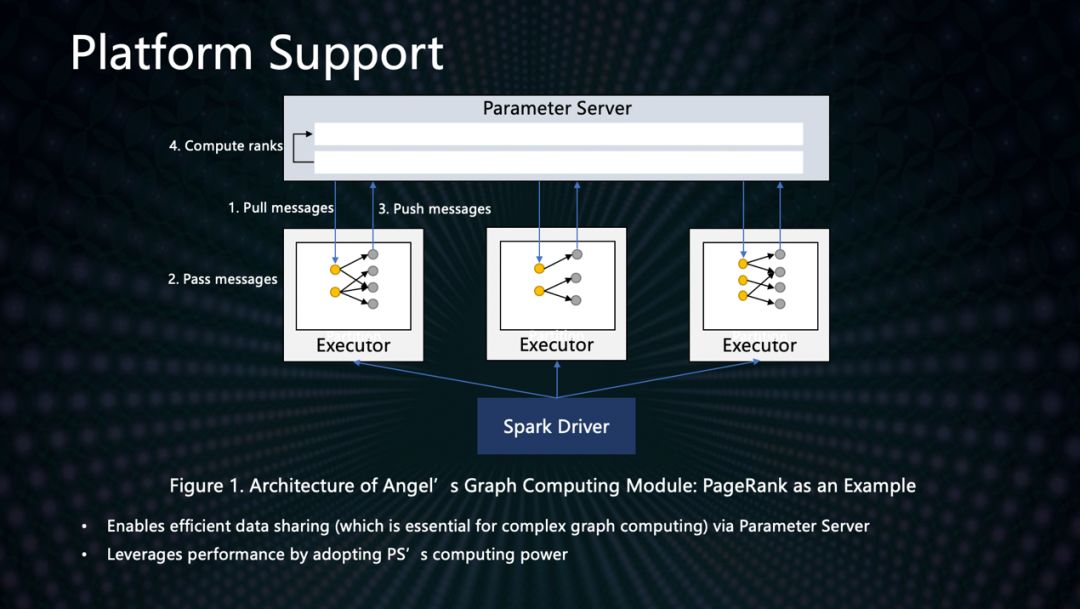
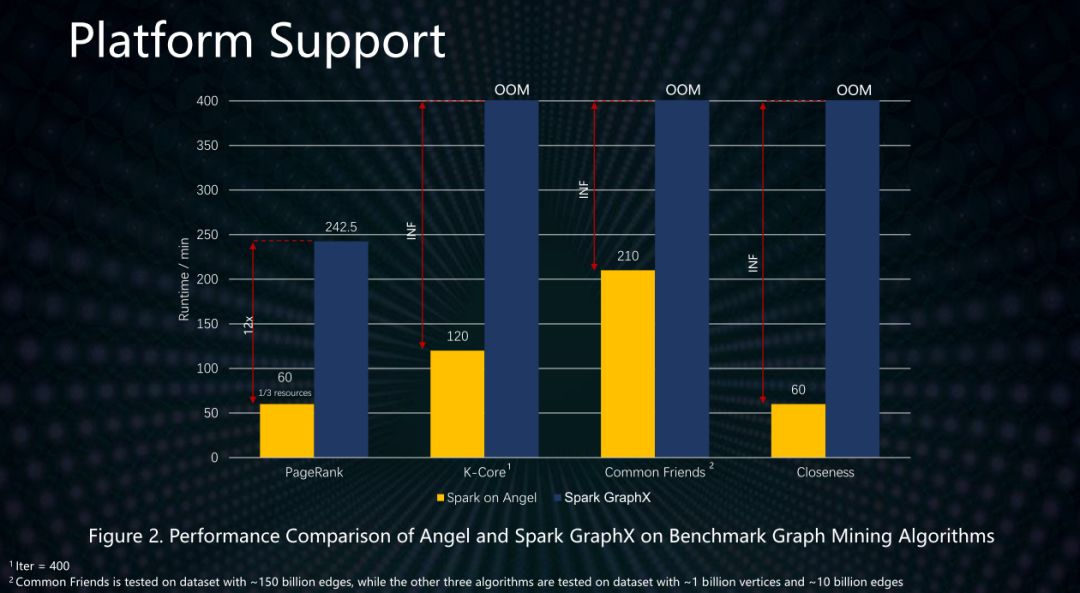
同时,数平数据中心研发的Angel参数服务器平台,针对关系型数据结构,在计算性能上对图算法做了优化,极大加速了PageRank等算法的计算速度,比如计算用户中心度的Closeness算法,性能比基于Spark GraphX的算法提升了6.7倍。下图显示对于大型图的计算,我们Angle框架的速度具有明显的优势。
我们所在团队积极与学术界科研合作,并希望有梦想、爱学习的实力派加入,共同研究和应用半监督/弱监督/无监督学习、小样本学习、复杂网络挖掘和图表示学习做大数据挖掘。
-
算法
+关注
关注
23文章
4612浏览量
92874 -
大数据
+关注
关注
64文章
8886浏览量
137434
原文标题:IJCAI2019报告:基于无监督学习和图学习的大数据挖掘
文章出处:【微信号:Tencent_TEG,微信公众号:腾讯技术工程官方号】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
时空引导下的时间序列自监督学习框架

基于大数据与深度学习的穿戴式运动心率算法

【《大语言模型应用指南》阅读体验】+ 基础知识学习
基于FPGA的类脑计算平台 —PYNQ 集群的无监督图像识别类脑计算系统
图机器学习入门:基本概念介绍

无监督深度学习实现单次非相干全息3D成像

机器学习基础知识全攻略
Meta发布新型无监督视频预测模型“V-JEPA”
数据挖掘的应用领域,并举例说明
描绘未知:数据缺乏场景的缺陷检测方案






 工商网监
工商网监
评论