 百度端对端语音识别专利揭秘
百度端对端语音识别专利揭秘
百度公司提出的端对端神经网络模型来进行语音识别,成功的代替了手工工程化部件的流水线操作,这让整个语音识别技术更加便捷,而使用神经网络来抽取输入端的特征信息相当于人功抽取特征则更加全面。
集微网消息,近年来,语音识别技术得到了迅猛的发展,这得益于人工智能的快速发展,其中最为主要的学业界的各大神经网络的出现,包括基础的序列神经网络模型RNN、LSTM和GRU。语音识别技术也已经进入到各行各业中,如工业、家电、通信和汽车电子等。于是,对于语音识别技术的要求也将更加严格了,更倾向于走向准确化和便捷化。
以往,构建语音识别模型主要是使用HMM的序列模型,再使用手工工程化部件来实现整个流水线操作,并且对于不同的语言的语音需要重新构建模型的结果特征。对此,国内语音识别技术第一梯队公司百度便提出了使用端对端的神经网络模型来进行语音识别工作,该专利为“端对端语音识别”(专利号:CN107408111A)。
首先,小编在这先介绍一下神经网络端对端的学习方式。对于语音识别来说,端到端深度学习做的是,训练一个深度神经网络,输入就是一段音频,输出直接是听写文本。其中这里的端表示输入源数据端,另外一端是神经网络处理的结果也就是我们最终需要的目标。这种训练学习的方式能应对多种语言的语音识别的场景构建,因为仅仅是需要改变输入端和输出端,深度神经网络的结构并不需要根据语言的语音不同而改变。
专利中提出的端对端的深度学习模型的架构图如图1所示。该架构包括训练以摄取语谱并生成文本的递归神经网络模型。首先,使用一个或更多个卷积层对语谱进行特征提取,紧接着,使用一个或多个递归层(双向GRU神经网络)对语谱的特征进行时序建模。最后再使用全连接层将递归层获取的语谱信息进行全连接作为CTC(链结式时间分类算法:重点解决输入数据与给定标签的对齐问题)的输入,经过Softmax计算输出各个文本标签的概率。
图1端对端深度学习模型架构图
经过上述端对端深度学习模型构建后,专利中还给出了端对端深度学习模型的训练方法,如图2所示。
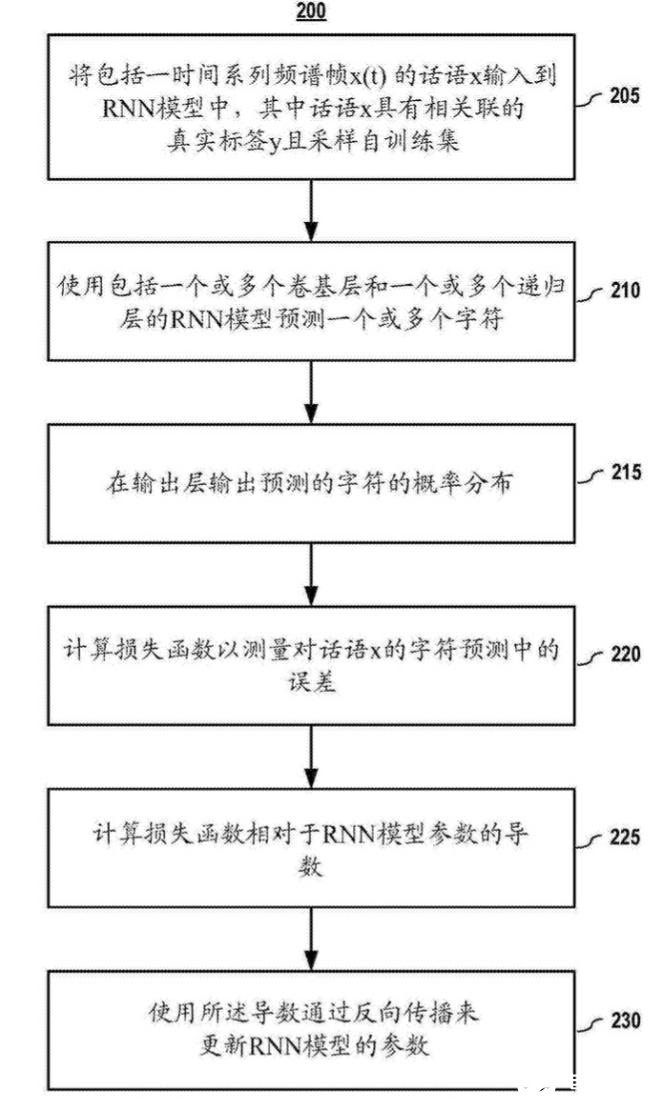
图2 端对端深度学习模型训练方法图
首先需要为模型设置好,输入端和输出端,对于语音识别技术来说,输入端为一时间序列频谱帧的话语X,输出端是与话语X具有相关联的真实标签Y。
构建深度神经网络模型(包括一个或多个卷积层和一个或多个递归层的模型)用来预测一个或多个字符也就是我们输出端的标签。
根据网络模型的输出端的标签的概率分布与真实标签的误差计算损失函数,提供损失函数推出标签预测的误差,再使用梯度反向传播算法更新模型参数。从而达到网络模型学习的目的。
百度公司提出的端对端神经网络模型来进行语音识别,成功的代替了手工工程化部件的流水线操作,这让整个语音识别技术更加便捷,而使用神经网络来抽取输入端的特征信息相当于人功抽取特征则更加全面,这让整个语音识别技术更加准确。从这两方面来看,端对端的神经网络模型确实是让语音识别技术走向了便捷化,准确化。
-
百度
+关注
关注
9文章
2308浏览量
91282 -
语音识别
+关注
关注
38文章
1768浏览量
113464
发布评论请先 登录
相关推荐

百度文心大模型4月1日起全面免费开放
百度百科启动“繁星计划”
ElfBoard开源项目|百度智能云平台的人脸识别项目






 工商网监
工商网监
评论