 采用软件定义架构探讨OFDMA和MIMO技术的实现
采用软件定义架构探讨OFDMA和MIMO技术的实现
无线网络通信正在不断发生着变化。所有新的4G空中接口(WiMAX、LTE、UMB、802.20、WiBRO、下一代PHS等等)都共享着某些公共的技术:所有接口都基于正交频分多址接入(OFDMA);所有接口使用MIMO(多入多出);所有接口都采用“扁平化架构”并且都基于IP(互联网协议)。
本文将讨论其中的前两项:具体地说,首ff先是介绍如何实现OFDMA的核心DSP算法,然后是被LTE用来实现上行链路的新技术,最后简要介绍用于WiMAX和LTE的MIMO(所有IP方面的内容不在本文讨论范围内)。本文讨论的前提条件是采用软件定义的架构。
OFDM使用大量紧邻的正交子载波。每个子载波采用传统的调制方案(如正交幅度调制)进行低符号率调制,其数据速率保持与相同带宽下的传统单载波调制方案相同。增强性能的OFDMA技术允许通过给多个用户分配特殊频率并共享信道。
采用单载波方案的OFDM的主要优点是无需复杂的均衡滤波器就能够应付多种信道条件。例如,很长的铜线中产生的高频衰减,窄带干扰以及由于多径导致的频率选择性衰落。由于OFDM可以看作使用许多慢速调制的窄带信号,而不是使用一个快速调制的宽带信号,因此信道均衡可以得到简化。低符号率可以充分利用符号间可提供的保护间隔,从而使得处理时域扩展(time-spreading)成为可能,并能消除码间干扰(ISI)。
在目前为止的大多数系统中,如WiFi、16d和16e WiMAX和LTE下行链路,核心算法一直是FFT。然而,LTE上行链路进行了革新,要求使用更复杂的离散傅里叶变换(DFT)。
所有这些系统不仅需要高速FFT处理,而且要求灵活性。频增的市场压力要求供应商发布的产品兼容较早的标准,但也必须具备足够的灵活性,以便能通过简单的软件升级而升级到最终版本,或者是让同一个系统支持不同的模式或不同的标准(如用于LTE和WiMAX的公共平台)。
然而,也可以采用可编程平台,这种可编程平台可以在灵活的软件引擎上高效地实现面向硬件的算法。picoChip公司的高性能PC102就是一个很好的例子,它结合了软件开发环境的面市时间和提取优势以及在算法中采用并行机制带来的性能优势。
FFT其实就是离散傅里叶变换(DFT)的一种高效实现。对于一个N点DFT来说,直接实现要求N2次复杂的乘法与加法运算,但作为一个提供难以置信的效率增益的完美例子,经典的FFT只要求N2N次运算。
有两种方法可以将DFT减少为一系列更简单的运算。一种方法是执行频域抽取,另一种方法是执行时域抽取。这两种方法需要相同数量的复杂乘法和加法运算。两者的主要区别是,时域抽取接受数字翻转的输入,产生正常顺序的输出,而频域抽取则接受正常顺序的输入,产生数字翻转的输出。输入和输出运算由所谓的蝶形运算完成。每个蝶形运算都要将输入乘上复杂的旋转因子e-j2πn/N。
流水线FFT可以采用对串行输入流的实时连续处理进行表征。面向硬件的方法通过尽量减少复杂乘法器的数量和所需的存储空间来减少硅片的成本或面积。这样可以在一定的面积上并行计算更多的单元。
FFT算法涉及到数据的暂时分离,这是由蝶形运算执行的一项任务。由于样值要从输入流中的不同点处获取,因此流水线FFT需要对数据进行缓存和重新排序。目前有许多不同的架构可以解决这个问题。本文的FFT用例采用了标准的radix-4频域抽取算法。
FFT的picoArray实现方案
picoChip PC102是一款高性能的多核DSP,专门针对无线做过优化。它在单个裸片上集成了300多个种类略有不同的处理器(或“阵列单元”):每个处理器均是自带存储器的传统16位哈佛结构DSP,如表1所示。
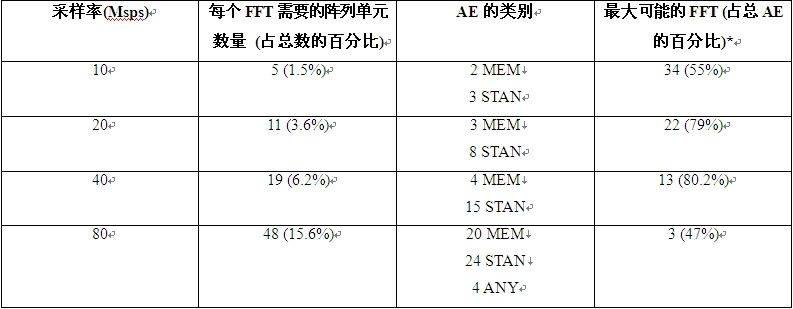
表1:PC102处理器变化和存储器分布(*FFT的最大数量受限于可用MEM类AE的数量)。
picoArray编程模型使得组装流水线结构变得非常容易,这也是实现FFT所用的方法。举例来说,每个radix-4蝶形运算包括4个复杂的乘法(注意,第4个蝶形运算只包含复杂的加法),并被映射到一个独立的处理器。每个阵列单元都是从内部总线获取输入数据,经过处理后再向流水线中的下一个DSP提供输出。由于总的吞吐量受限于最慢的阵列单元,因此理想情况下阵列单元上的每个环回都应花相同数量的周期才能实现最佳的性能。例如,如果每个阵列单元在8个周期内处理每个样值,那么最大吞吐量在160MHz时可达每秒20M个采样。
FFT实现接收16+j16、左对齐、按顺序输入的数据,提供16+j16、也按顺序的输出数据。在每个蝶形运算中会发生位增加现象,其中2个位用于加法,16个位用于复杂的乘法,这种位增加在采用就近舍入策略的40位STNA2 AE累加器中很容易管理。这种机制可以保持中间值的最佳可能精度 ,从而达到较高的输出数据信噪比。图1a显示了本实现中的单元。
图1b:FFT内部单元;并行FFT可实现LTE上行链路要求的更高吞吐量DFT。
表2总结了PC102上的256点FFT的性能。表2给出了复杂采样速率在10MSps和80MSps之间的256点FFT所要求的资源,并给出了在PC102上能以每个速率点执行的最大FFT数量。从表中可以看出,单个10MSps FFT需要约1.5%的资源。
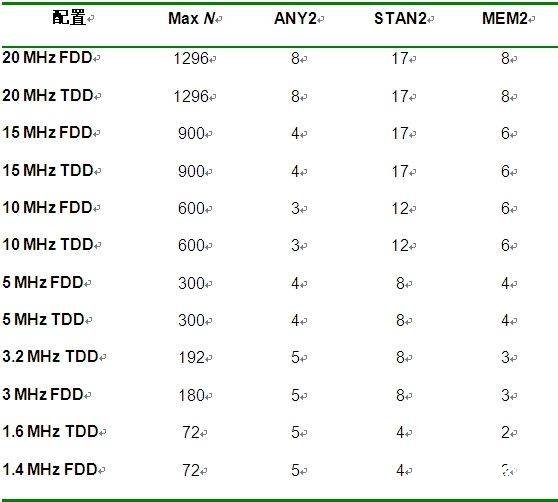
表2:picoArray上的OFDMA采用的256点 16+j16 FFT的资源使用。
从图1b可以看出如何通过整合“构建模块”FFT来获得更高的吞吐量--显然并行架构是非常适合的。
虽然目前大多数标准采用OFDM(WiFi、802.16d、Flash OFDM)或OFDMA(802.16e),但LTE选用的上行链路发送机制是最新的SC-FDMA(单载波FDMA),也称为DFT扩展OFDM。
与传统OFDMA相比,SC-FDMA的优点是信号具有更低的峰值/平均功率比(PAPR),因为它采用了固有的单载波结构。这在上行链路中尤其重要,因为在上行链路中更低的PAPR可以使移动终端在发送功效方面得到更大的好处,并进而延长电池使用时间。因此一些人士认为,SC-FDMA“集两者之大成”,即单载波的低PAPR和多载波的鲁棒性。当然,天下没有免费的午餐,这些好处的代价是增加了数字处理的复杂性,如上所述。
SC-FDMA上行链路的实现如图2所示,其中DFT位于OFDM调制器之前,这表明比标准OFDMA要多一些步骤。
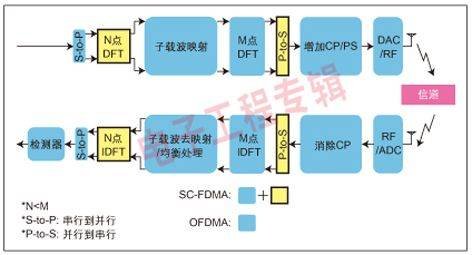
图2:SC-FDMA或DFT扩展OFDM。
众所周知,如果变换点数可以分解成少量的数(素数),就可以高效地实现DFT。分解时素数越少,实现越简单。当然,经典FFT使用单个素数因子2。
LTE中的DFT预编码器尺寸取决于为指定用户的上行链路数据发送分配的子信道数量。
其中N是子载波的数量,a、b和c在 N ≤1320 条件下都大于等于0 (20MHz带宽时)。对于指定的用户,N范围可以从12个音 (a,b,c=0,即单个资源模块)到1296,总共35个不同的选择,这些音再一起经过调制形成单载波上行链路。然而,这是在手机发送器侧,因为基站接收机要处理许多用户,每个用户从这些选项中作出选择,针对所有可能的帧配置的总允许变换器数量是531、783、569。这种灵活性显然增加了接收iDFT的复杂性。
用于分解iDFT的技术是“分而治之”,主要原理与大家熟悉的FFT相同,但iDFT的长列表无法被分解成单个素数因子。相反,每个音可以被分解成长度为2、3和5的三个短iDFT。这些是iDFT的“引擎”。在本例实现中,一些iDFT已经被分解成素数因子(如4、8和9)以外的其他因子,以便将流水线级的最大数量减小至3,从而带来缩短延迟的好处。
图3显示了LTE iDFT的逻辑结构,这种结构可用来在PC102/PC20x上实现20MHz的LTE eNodeB。
图3:LTE iDFT库结构。
流水线级必须能够实现所有35种可能的iDFT功能,并动态地重新配置和避免由于不同长度iDFT同时流过而造成的任何流水线危害。最简单的架构是重新排序+级缓冲对A、B和C都成为用来实现所有6个iDFT引擎的相同功能块的实例(如果计算1点iDFT就是7台引擎,即通过不变)。更优化的解决方案确认只有一级需要实现9点引擎,另外一级需要实现8点引擎,第三级需要4点引擎,加上2、3和5个引擎,因为任何iDFT长度都不需要超过一个9、8或4。
使事情复杂化的因素之一是,LTE是一个带宽可扩展的系统(简言之,TDD/FDD都是1.25MHz~20MHz)。表3列出了不同模式时的不同实现方式。虽然与FFT相比灵活性有一定的代价(见表2),但值得注意的是,这种架构在实现这些配置时效率仍然特别高:即使所需的20MHz+20MHz FDD(最坏情况)资源也仍只占PC102的10%。
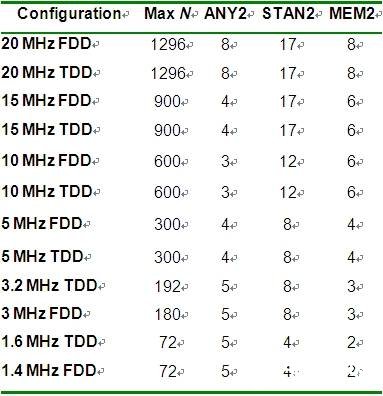
表3:picoArray上可扩展iDFT的资源使用。
MIMO
MIMO是指在发送机和接收机上使用多幅天线以改善通信性能,它是所有4G系统的一个特点。
MIMO不需要增加带宽或发送功率就能显著地提高数据吞吐量和链路距离,并具有更高的频谱效率(每秒每赫兹带宽可传更多的位)和链路可靠性或空间分集性能(降低了衰落)。
发送(TX)端有m幅天线,接收(RX)端有n幅天线,就形成了一个mn的MIMO,此时信道的数量就等于所有组合之和:例如一个22的MIMO就有4个“信道”(1-1,1-2,2-1,2-2),性能将达到SISO系统中香农极限值的两倍。你只能从4个“信道”中发送2倍的信息,因为你需要“解开”信道矩阵才能提取信息。在实际应用中,信道不是完全独立的(存在一定的相关性),因此优势有所降低。事实上有个似是而非的结论,即信道越差(更多的多径等),MIMO的用处就越大,因为信道相关性越少。在自由空间中,由于4个信道非常相似,因此带来的好处非常有限。
MIMO有多种不同的使用方式。拿WiMAX下行链路来说,它有两种标准的MIMO模式:Matrix A和Matrix B。前者也被称为空间时间编码(STC),它通过两幅发射天线以不同的形式发送相同的信号。由于发送的是相同的符号,数据速率在SISO上不会提高,但由于两种形式(s和-s*)不同,接收机有更好的机会恢复数据,因此鲁棒性和范围(针对指定的数据速率)得到了改善。为了在下行链路中实现这一技术,虽然符号率块不受影响(发送的一个符号),但现在有两个突发链(burst chain),它们用不同调制形式的信息馈送到两幅天线。
Matrix B则相反,它通过发送两个不同的符号来获得双倍的数据速率。在这种情况下,共有两个突发链(针对两幅天线),每个链处理独立的符号;在实际应用中,它将不是简单的复制,而是符号率部分将被设计得更加快速,然后将输出信号交替发送给两个TX分支。实际系统同时支持两种模式,可以根据每个用户要求选择Matrix A或B:向条件较好的系统以较快的速度发送数据,而使用STC能使蜂窝边缘的系统受益。
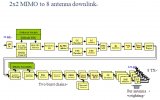
这非常适合多核架构。如图4所示,有两个独立的突发链馈送倒两幅天线:同样的架构被简单地例示了两次,这对工程师来说非常简单。这个特殊的图实际上稍微有些复杂,在实际应用中,许多系统都结合使用MIMO和多种空间技术,如波束成形、“调零”(null-steering)天线或SDMA。这个特殊设计共有8幅天线,配置为每个MIMO分支4幅,每个天线都可以独立控制。
图4:具有两个独立突发链的MIMO下行链路系统。
在接收机侧,信号处理相对更加复杂:不仅因为Matrix B有更高的峰值数据速率,而且用于区分不同信号的接收机特别复杂。
本文小结
空中接口正变得越来越复杂,并且依赖于更复杂的算法才能获得最佳的性能、效率和范围。基于FFT的OFDMA已经成为下一代无线的标准技术。但最新的技术,如LTE,也在寻求做出更多的改善:它们采用更复杂的技术,如SC-FDMA,并要求灵活的DFT技术。
我们可以使用软件可编程架构来模仿面向硬件的折中所具有的优势和灵活性,引导系统制造商更早地进入需要WiMAX和LTE等算法的市场。这样就能让他们比竞争对手更早地推出产品,并仍确保与标准的兼容。事实上,一个合适的架构可以实现从一个公共平台开始的所有标准(如802.16d/e和LTE,以及下一代PHS或UMB)。扩展这种架构以支持MIMO相对比较简单。
责任编辑:gt
-
滤波器
+关注
关注
161文章
7902浏览量
179296 -
4G
+关注
关注
15文章
5537浏览量
119736 -
无线
+关注
关注
31文章
5473浏览量
174116
发布评论请先 登录
相关推荐
MIMO-OFDMA无线基站的DSP-FPGA系统划分
无线AP为什么采用MIMO技术?
4G空中接口中的OFDMA和MIMO技术讨论
如何进行无线MIMO测试开发?
如何实现OFDMA的核心DSP算法?
ARM架构MT7981方案 2+8口千兆5G路由器--HC-G80采用openwrt系统可二次开发
4G空中接口通用的OFDMA和MIMO技术探讨
MIMO-OFDMA无线基站的DSP-FPGA系统划分
DoCoMo北京研究所推8×8MIMO-OFDMA实时传输实
基于软件定义架构的OFDMA核心DSP算法的实现及LTE的MIMO技术的讨论分析
ofdma技术的基本原理是什么?ofdma优缺点介绍







 工商网监
工商网监
评论