 SQL数据库的基础知识详细说明
SQL数据库的基础知识详细说明
如果说前端应用为网络世界搭建起了一座座房子,那么数据库数据就是住进这些房子的人。
网络世界(或者编程者的世界)与人类世界是相反的。编程世界的技术核心与真相,是在底层的。个人认为,无论是用怎样的架构部署,用怎样的语言编码或者方式展示,web应用和手机应用的底层,就是数据库里面的数据。在这些数据下面,有更底层的东西,值得我们去学习、去探索、去挖掘。或许哪天一不小心,我们就能挖到这个世界的真相。
思维导图:
1- 思维导图
1、数据库的定义
数据库是“按照数据结构来组织、存储和管理数据的仓库”。是一个长期存储在计算机内的、有组织的、有共享的、统一管理的数据集合。
1、 数据库是一个实体,它是能够合理保管数据的“仓库”,用户在该“仓库”中存放要管理的事务数据,“数据”和“库”两个概念结合成为数据库。
2、 数据库是数据管理的新方法和技术,它能更合适的组织数据、更方便的维护数据、更严密的控制数据和更有效的利用数据。
2、数据库管理系统
数据库管理系统(Database Management System)是一种操纵和管理数据库的大型软件,用于建立、使用和维护数据库,简称DBMS。它对数据库进行统一的管理和控制,以保证数据库的安全性和完整性。用户通过DBMS访问数据库中的数据,数据库管理员也通过DBMS进行数据库的维护工作。它可以支持多个应用程序和用户用不同的方法在同时或不同时刻去建立,修改和询问数据库。大部分DBMS提供数据定义语言DDL(Data Definition Language)和数据操作语言DML(Data Manipulation Language),供用户定义数据库的模式结构与权限约束,实现对数据的追加、删除等操作。
3、数据库类型
3.1、关系型数据库
关系型数据库,存储的格式可以直观地反映实体间的关系。关系型数据库和常见的表格比较相似,关系型数据库中表与表之间是有很多复杂的关联关系的。 常见的关系型数据库有Mysql,SqlServer等。
虽然关系型数据库有很多,但是大多数都遵循SQL(结构化查询语言,Structured Query Language)标准。 常见的操作有查询,新增,更新,删除,求和,排序等
3.2 非关系型数据库(NoSQL)
NoSql数据库如MongoDB、Redis、Memcache出于简化数据库结构、避免冗余、影响性能的表连接、摒弃复杂分布式的目的被设计。
非关系型数据库的分类:
(1)键值对存储(key-value):代表软件Redis,它的优点能够进行数据的快速查询,而缺点是需要存储数据之间的关系。
(2)列存储:代表软件Hbase,它的优点是对数据能快速查询,数据存储的扩展性强。而缺点是数据库的功能有局限性。
(3)文档数据库存储:代表软件MongoDB,它的优点是对数据结构要求不特别的严格。而缺点是查询性的性能不好,同时缺少一种统一查询语言。
(4)图形数据库存储:代表软件InfoGrid,它的优点可以方便的利用图结构相关算法进行计算。而缺点是要想得到结果必须进行整个图的计算,而且遇到不适合的数据模型时,图形数据库很难使用。
3.3 NoSQL 与关系型数据库的区别
首先一般非关系型数据库是基于CAP模型,而传统的关系型数据库是基于ACID模型的。
其次在 数据存储结构、可扩展性、数据一致性上,两者有一定的区别。
CAP定理:在理论计算机科学中,CAP定理(CAP theorem),又被称作布鲁尔定理(Brewer's theorem),它指出对于一个分布式计算系统来说,不可能同时满足以下三点:
一致性(Consistency)(所有节点在同一时间具有相同的数据)
可用性(Availability)(保证每个请求不管成功或者失败都有响应)
分隔容忍(Partition tolerance)(系统中任意信息的丢失或失败不会影响系统的继续运作)
ACID模型:ACID,是指数据库管理系统(DBMS)在写入/异动资料的过程中,为保证交易(transaction)是正确可靠的,所必须具备的四个特性:
原子性(Atomicity,或称不可分割性)、
一致性(Consistency)
隔离性(Isolation,又称独立性)
持久性(Durability)。
4、分布式数据库
所谓的分布式数据库技术,就是结合了数据库技术与分布式技术的一种结合。具体指的是把那些在地理意义上分散开的各个数据库节点,但在计算机系统逻辑上又是属于同一个系统的数据结合起来的一种数据库技术。
5、SQL定义与语法
5.1 什么是SQL
SQL 是用于访问和处理数据库的标准的计算机语言
SQL 指结构化查询语言
SQL 使我们有能力访问数据库
SQL 是一种 ANSI 的标准计算机语言
5.2 语法
SQL 对大小写不敏感。
SQL 分为两个部分:数据操作语言 (DML) 和 数据定义语言 (DDL)。
DML部分:
SELECT - 从数据库表中获取数据
UPDATE - 更新数据库表中的数据
DELETE - 从数据库表中删除数据
INSERT INTO - 向数据库表中插入数据
DDL部分:
CREATE DATABASE - 创建新数据库
ALTER DATABASE - 修改数据库
CREATE TABLE - 创建新表
ALTER TABLE - 变更(改变)数据库表
DROP TABLE - 删除表
CREATE INDEX - 创建索引(搜索键)
DROP INDEX - 删除索引
6、SQL基本语句
6.1、SELECT语句
SELECT 列名称 FROM 表名称 ;SELECT * FROM 表名称。
SELECT 语句用于从表中选取数据。
结果被存储在一个结果表中(称为结果集)。
星号(*)是选取所有列的快捷方式。
6.2、distinct语句
关键词 DISTINCT 用于返回唯一不同的值。
SELECT DISTINCT 列名称 FROM 表名称
6.3、where语句
WHERE 子句用于规定选择的标准
SELECT 列名称 FROM 表名称 WHERE 列 运算符 值;
运算符:= <> > < >= <= BETWEEN LIKE AND OR
6.4、AND & OR语句
AND 和 OR 运算符用于基于一个以上的条件对记录进行过滤。
AND 和 OR 可在 WHERE 子语句中把两个或多个条件结合起来。
如果第一个条件和第二个条件都成立,则 AND 运算符显示一条记录。
如果第一个条件和第二个条件中只要有一个成立,则 OR 运算符显示一条记录。
6.5、Order By语句
ORDER BY 语句用于根据指定的列对结果集进行排序。
ORDER BY 语句默认按照升序(AES) 对记录进行排序。
如果您希望按照降序对记录进行排序,可以使用 DESC 关键字。
6.6、insert 语句
INSERT INTO 语句用于向表格中插入新的行;
INSERT INTO 表名称 VALUES (值1, 值2,....)
INSERT INTO table_name (列1, 列2,...) VALUES (值1, 值2,....)
6.7、update 语句
Update 语句用于修改表中的数据。
UPDATE 表名称 SET 列名称 = 新值 WHERE 列名称 = 某值
6.7、delete语句
DELETE 语句用于删除表中的行。
DELETE FROM 表名称 WHERE 列名称 = 值
6.8、Top子句
TOP 子句用于规定要返回的记录的数目。
注释:并非所有的数据库系统都支持 TOP 子句。
SQL Server 中:
SELECT TOP number|percent column_name(s) FROM table_name
MySql中:
SELECT column_name(s) FROM table_name LIMIT number
Oracle中:
SELECT column_name(s) FROM table_name WHERE ROWNUM <= number
6.9、通配符
在搜索数据库中的数据时,SQL 通配符可以替代一个或多个字符。
SQL 通配符必须与 LIKE 运算符一起使用。
% 替代一个或多个字符
_ 仅替代一个字符
[charlist] 字符列中的任何单一字符
[^charlist] 或者 [!charlist] 不在字符列中的任何单一字符
6.10、IN操作符
IN 操作符允许我们在 WHERE 子句中规定多个值。
SELECT column_name(s) FROM table_name WHERE column_name IN (value1,value2,...)
6.11、Aliases别名
通过使用 SQL,可以为列名称和表名称指定别名(Alias)。
SELECT column_name AS alias_name FROM table_name
7、SQL基本数据库操作
7.1、JOIN表连接
SQL join 用于根据两个或多个表中的列之间的关系,从这些表中查询数据。
JOIN: 如果表中有至少一个匹配,则返回行
LEFT JOIN: 即使右表中没有匹配,也从左表返回所有的行
RIGHT JOIN: 即使左表中没有匹配,也从右表返回所有的行
FULL JOIN: 只要其中一个表中存在匹配,就返回行
关键字语法:
SELECT column_name(s)
FROM table_name1
JOIN(或者INNER JOIN、LEFT JOIN、RIGHT JOIN、FULL JOIN) table_name2
ON table_name1.column_name=table_name2.column_name
7.2、UNION合并
UNION 操作符用于合并两个或多个 SELECT 语句的结果集。
注意:UNION 内部的 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每条 SELECT 语句中的列的顺序必须相同。
关键字语法:
SELECT column_name(s) FROM table_name1
UNION
SELECT column_name(s) FROM table_name2
注释:默认地,UNION 操作符选取不同的值。如果允许重复的值,请使用 UNION ALL。
7.3、表备份
SQL SELECT INTO 语句可用于创建表的备份复件。
SELECT INTO 语句从一个表中选取数据,然后把数据插入另一个表中。
SELECT INTO 语句常用于创建表的备份复件或者用于对记录进行存档。
语法:
SELECT * (或者指定列column_name(s))
INTO new_table_name [IN externaldatabase]
FROM old_tablename
注意:可以添加where子句,或者join连接等。
7.4、创建数据库
CREATE DATABASE 用于创建数据库。
语法:CREATE DATABASE database_name
7.5、创建数据库表
CREATE TABLE 语句用于创建数据库中的表。
语法:
CREATE TABLE 表名称
(
列名称1 数据类型,
列名称2 数据类型,
列名称3 数据类型,
....
)
7.6、创建索引
CREATE INDEX 语句用于在表中创建索引。
在不读取整个表的情况下,索引使数据库应用程序可以更快地查找数据。
创建简单索引的语法(允许使用重复的值):
CREATE INDEX index_name ON table_name (column_name);
在表上创建一个唯一的索引。唯一的索引意味着两个行不能拥有相同的索引值。
CREATE UNIQUE INDEX index_name ON table_name (column_name);
7.7、DROP语句
通过使用 DROP 语句,可以轻松地删除索引、表和数据库。
DROP INDEX index_name 删除索引,但是不同的数据库有不同的用法:
例如MySQL:ALTER TABLE table_name DROP INDEX index_name
SQL Server:DROP INDEX table_name.index_name
DROP TABLE 表名称 :删除表
DROP DATABASE 数据库名称 :删除数据库
TRUNCATE TABLE 表名称 :除去表内的数据,但并不删除表本身
7.8 ALTER 语句
ALTER TABLE 语句用于在已有的表中添加、修改或删除列。
例如:
ALTER TABLE table_name ADD column_name datatype
8、数据类型
8.1、常用的数据类型:
8-常用的数据类型图
8.2、Microsoft Access、MySQL 以及 SQL Server 所使用的数据类型和范围。
请参考W3school:SQL数据类型
9、约束(Constraints)
约束用于限制加入表的数据的类型。
可以在创建表时规定约束(通过 CREATE TABLE 语句),或者在表创建之后也可以(通过 ALTER TABLE 语句)。
主要约束:
NOT NULL 非空
NOT NULL 约束强制列不接受 NULL 值。
NOT NULL 约束强制字段始终包含值。这意味着,如果不向字段添加值,就无法插入新记录或者更新记录。
UNIQUE 唯一标识
UNIQUE 约束唯一标识数据库表中的每条记录。
UNIQUE 和 PRIMARY KEY 约束均为列或列集合提供了唯一性的保证。
PRIMARY KEY 拥有自动定义的 UNIQUE 约束。
请注意,每个表可以有多个 UNIQUE 约束,但是每个表只能有一个 PRIMARY KEY 约束。
PRIMARY KEY 主键
PRIMARY KEY 约束唯一标识数据库表中的每条记录。
主键必须包含唯一的值。
主键列不能包含 NULL 值。
每个表都应该有一个主键,并且每个表只能有一个主键。
AUTO INCREMENT 字段
我们通常希望在每次插入新记录时,自动地创建主键字段的值。
我们可以在表中创建一个 auto-increment 字段。
FOREIGN KEY 外键
一个表中的 FOREIGN KEY 指向另一个表中的 PRIMARY KEY。
CHECK 限制值的范围
DEFAULT 默认值
10、视图View
10.1、什么是视图
在 SQL 中,视图是基于 SQL 语句的结果集的可视化的表。
视图包含行和列,就像一个真实的表。视图中的字段就是来自一个或多个数据库中的真实的表中的字段。我们可以向视图添加 SQL 函数、WHERE 以及 JOIN 语句,我们也可以提交数据,就像这些来自于某个单一的表。
注释:数据库的设计和结构不会受到视图中的函数、where 或 join 语句的影响。
10.2、语法
创建视图
CREATE VIEW view_name AS
SELECT column_name(s)
FROM table_name
WHERE condition
注释:视图总是显示最近的数据。每当用户查询视图时,数据库引擎通过使用 SQL 语句来重建数据。
更新视图
CREATE OR REPLACE VIEW view_name AS
SELECT column_name(s)
FROM table_name
WHERE condition
删除视图
DROP VIEW view_name
10.3、视图的作用
视图仅支持查询,不支持增删改等数据操作。您可以将视图当作是一种临时表。
视图的作用:
1、 提高了sql代码的复用性。
当一个查询你需要频频的作为子查询使用时,视图可以简化代码,直接调用而不是每次都去重复写这个东西。
2、 提高了数据的安全性。
系统的数据库管理员,需要给他人提供一张表的某两列数据,而不希望他可以看到其他任何数据,这时可以建一个只有这两列数据的视图,然后把视图公布给他。
11、索引
索引是一种特殊的查询表,可以被数据库搜索引擎用来加速数据的检索。简单说来,索引就是指向表中数据的指针。数据库的索引同书籍后面的索引非常相像。
尽管创建索引的目的是提升数据库的性能,但是还是有一些情况应当避免使用索引。下面几条指导原则给出了何时应当重新考虑是否使用索引:
1、小的数据表不应当使用索引;
2、需要频繁进行大批量的更新或者插入操作的表;
3、如果列中包含大数或者 NULL 值,不宜创建索引;
4、频繁操作的列不宜创建索引。
SQL中的索引分为两种,一种为聚集索引和非聚集索引。
12、函数
常用的函数:
AVG () : 返回数值列的平均值。NULL 值不包括在计算中
COUNT() : 返回匹配指定条件的行数
MAX() : 返回一列中的最大值。NULL 值不包括在计算中
MIN() : 返回一列中的最小值。NULL 值不包括在计算中
SUM() : 返回数值列的总数(总额)
不常用:
FIRST() : 返回指定的字段中第一个记录的值
LAST() : 返回指定的字段中最后一个记录的值。
UCASE() : 把字段的值转换为大写
LCAS() : 把字段的值转换为小写
MID() : 用于从文本字段中提取字符
LEN() : 返回文本字段中值的长度
ROUND() : 用于把数值字段舍入为指定的小数位数
NOW() : 返回当前的日期和时间
FORMA() : 用于对字段的显示进行格式化
REPLACE() : 字符串替换函数
CONCAT():将两个字符串连接为一个字符串
GROUP BY 语句:
合计函数 (比如 SUM) 常常需要添加 GROUP BY 语句。
语法:
SELECT column_name, aggregate_function(column_name)
FROM table_name
WHERE column_name operator value
GROUP BY column_name
HAVING 语句:
在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与合计函数一起使用。
语法:
SELECT column_name, aggregate_function(column_name)
FROM table_name
WHERE column_name operator value
GROUP BY column_name
HAVING aggregate_function(column_name) operator value
例如:
SELECT Customer,SUM(OrderPrice) FROM Orders
GROUP BY Customer
HAVING SUM(OrderPrice)<2000
-
SQL
+关注
关注
1文章
762浏览量
44117 -
数据库
+关注
关注
7文章
3795浏览量
64367
发布评论请先 登录
相关推荐
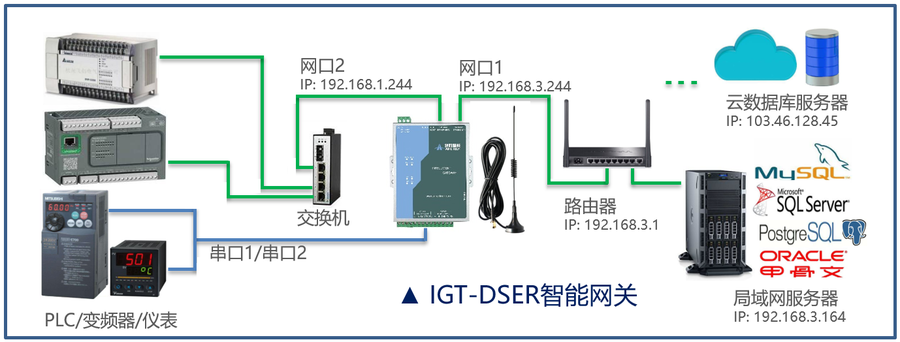
不用编程不用电脑,快速实现多台Modbus协议的PLC、智能仪表对接SQL数据库
SQL数据库设计的基本原则
SQL与NoSQL的区别
数据库数据恢复—通过拼接数据库碎片恢复SQLserver数据库

数据库数据恢复—SQL Server数据库出现823错误的数据恢复案例

干货分享 如何采集OPC DA数据并存储到SQL Server数据库?
数据库数据恢复—SqlServer数据库底层File Record被截断为0的数据恢复案例
恒讯科技分析:sql数据库怎么用?
数据库数据恢复—SQL Server数据库所在分区空间不足报错的数据恢复案例
数据库数据恢复—数据库所在分区空间不足导致sqlserver故障的数据恢复案例
数据库数据恢复—raid5阵列上层Sql Server数据库数据恢复案例

数据库数据恢复—ndf文件大小变为0KB的数据恢复案例
数据库数据恢复—Sql Server数据库文件丢失的数据恢复案例





 工商网监
工商网监
评论