 MYSQL中读写分离有什么作用及基本架构说明
MYSQL中读写分离有什么作用及基本架构说明
现在绝大部分软件项目,都会使用到关系型数据库,比如MySQL、Oracle、DB2等等,目前这些数据库的单机性能已经是不断优化和提高了,但是随着数据增长的速度和并发访问量的增加,在某些公司、某些场景下,单机数据库已经很难满足业务的需要了,所以必须考虑数据库集群的方式来提高系统的可用性;最常见的两种方法:
分库分表:把数据分散到不同的数据库上,每台数据库中存储的数据是不相同的(这里先不考虑每个库做备份或读写分离);分库分表既可以分散数据库访问的压力,也可以分散数据存储的压力;但是使用分库分表方案的时候,会带来扩容、事务、关联查询等问题和难点,具体这里就不展开讲了。
读写分离:将数据库读操作和写操作分散到不同的节点上,通常是一台数据库做写操作,1到N台做读操作;读写分离的架构,每一台数据中的数据是相同的(这里先忽略延迟的问题),所以只分散了数据库访问的压力,并没有分散数据存储的压力;我们这里主要讲一讲读写分离。
读写分离基本架构
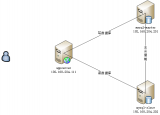
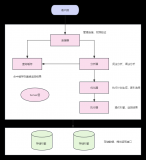
MySQL读写分离的基本架构,可以参考下图:
如上图,读写分离实现的基本步骤是:
数据库服务器搭建多台,一主N从(N大于等于1);
主数据库只负责写操作,从数据库只负责读操作;
主数据库复制数据到从数据库上;
客户端写操作路由到主数据库上,读操作路由到从数据库上。
读写分离还有另外一种架构,就是在MySQL数据库和客户端之间,增加一层中间代理层,客户端只连接代理, 由代理根据请求类型,把请求分发到不同的数据库上:
第一种架构,整体架构比较简单直接,性能会稍微高一些,但是如果才用直连的方式,客户端可能会稍微麻烦一些(通常需要引入一些组件,负责管理数据库);
第二种架构,对客户端比较友好,因为客户端只需要和代理交互,并不用关注数据库的具体信息;但是因为多了一层代理,多多少少会对性能有一定的影响。
读写分离带来的好处
读写分离结构中,会有两台甚至更多台数据库,这种冗余的设计,可以提高数据的安全性和系统的可用性;就算是在分库分表的架构中,每一台子库,也可以一主多备的部署方式;
读写分离更多的时候使用在读操作远远大于写操作的场景下,这样可以保证写操作的数据库承受更小的压力,也可以缓解X锁和S锁争用;
服务器数量的增加,意味着可以有效地利用多台服务器的资源;读操作被分摊,提高了系统的性能;
如果写操作比读操作多,或者相近,可以采用双主相互复制的架构。
读写分离会带来的问题
之前的文章,我也反复强调过,任何的架构、软件、框架、组件...在解决一部分问题的时候,一定会带来其他的问题;读写分离最大的一个问题就是,数据从主复制到从的过程中,可能会存在延迟的,如果客户端在执行完一个读操作后,立刻从存库中查询的话,可能会读取到旧数据的情况(我们不断优化,也只能缩短这个时间,并不能完全消除掉这个时间)。
那么针对这个问题,有哪些处理方法呢?
根据具体场景进行评估,是否可以接收这个延迟(这好像是一句废话,但是大多数业务场景,是可以接收这点儿延迟的);
对于实时性要求很高的场景(查询的数据必须是最新的结果),将这些请求强制路由到主库上;
执行完写操作之后,在读操作发生之前,让中间的时间变长(也就是从业务操作角度来做一些控制,不一定操作完了立刻查询);
判断主备无延迟,可以通过判断seconds_behind_master参数、对比GTID、对比位点等方式,判断从数据库是否和主数据库一致。
-
服务器
+关注
关注
12文章
9160浏览量
85418 -
数据库
+关注
关注
7文章
3799浏览量
64389 -
MySQL
+关注
关注
1文章
809浏览量
26566
发布评论请先 登录
相关推荐
MySQL编码机制原理
适用于MySQL的dbForge架构比较
嵌入式Hypervisor:架构、原理与应用 阅读体验 +分离内核的嵌入式Hyperviso
乒乓球架构中LMX2820的高隔离、快速频率切换应用说明

SSD基本架构

MySQL的整体逻辑架构
labview 创建mysql 表时 设置时间 怎么在mysql中是格式是date 而不是datetime?
ARM中的编码方式与寻址方式有何不同?
查询SQL在mysql内部是如何执行?





 工商网监
工商网监
评论