 如何切实地设计实现现实世界中的强化学习
如何切实地设计实现现实世界中的强化学习
许多文章解释了强化学习(RL)的概念,但鲜有文章解释如何切实地设计实现现实世界中的强化学习。
小芯这次想分享人工智能范式转变课程,讨论设计权衡问题,并深入研究技术细节。
那么,我们开始吧!
首先,喝酒?
想象一下你身处聚会,有点微醺或酩酊大醉,自愿参加一个饮酒游戏,想要打动一个(或多个)颇具魅力的泛泛之交。
有人蒙住你的眼睛,给你一杯或一瓶啤酒,喊道:“倒酒!”
你会怎么做?
可能会有以下反应:该死,我应该怎么做?怎样能赢!要是输了怎么办!?
游戏规则如下:在10秒内把啤酒灌满,尽可能接近玻璃杯上的标记。可以把啤酒倒进倒出。
RL(强化学习)解决方案面临着类似的任务,高大上且有意义,欢迎了解。
现实世界中的啤酒问题
环保共享单车业务存在一个大问题。一天中,每个单车停放处(杯)的共享单车(啤酒)数量过多或不足。
纽约市单车停放处的单车过剩和不足
对于骑自行车的人来说,这十分不便,并且要花费数百万美元来管理运营,也不划算。不久前,笔者在纽约大学的团队任务是提供人工智能解决方案,将人工干预降到最小,帮助管理自行车库存。
目标:每天将各个单车停放处的数量保持在1至50之间(想想杯子上的标记)。这在共享经济中被称为“再平衡问题”。
限制条件:由于运营限制,团队每天每小时只能移动1、3或10辆单车(可以倒入或倒出的啤酒量)。当然,他们可以选择什么都不做。团队移动的单车越多,价格越昂贵。
惰性RL(强化学习)解决方案
来源:Pexels
团队决定使用RL (强化学习),它克服了传统方法的许多局限(例如基于规则和预测)。
如果想了解RL(强化学习)以及一些关键概念,乔纳森·辉(JonathanHui)撰写了一篇很棒的介绍,托马斯·西蒙尼尼(ThomasSimonini )详细解释了解决方案中应用的RL算法Q-Learning。
事实证明,人类创建了极具惰性的人工智能。当单车存量超过60辆时,它通常会选择不执行任何操作或执行最少操作(移动1或3辆自行车)。似乎有违常理,但这是非常明智的。
根据直觉,可能会移动尽可能多的单车以将其保持在50辆以下,尤其是在停放处停满时。但是,RL(强化学习)识别出移动成本(移动的单车越多,成本越高)以及在某些情况下成功的机会。考虑到所剩时间,根本不可能实现目标。它知道最好的选择是“放弃”。因此,放弃比继续尝试要付出更少的代价!
所以呢?当人工智能做出非常规决策时,类似于谷歌Alpha Go研发的著名Move 37 and 78 ,它们会挑战人类的偏见,帮助打破知识的魔咒,并将人类推向未知的道路。
创造人工智能既是一种发明,也是一种探索人类内心活动的旅程。——DeepMind创始人德米斯·哈萨比斯 (Demis Hassabis)在《经济学人》杂志《2020年的世界》(The World in 2020)一文中所言。
但是,请保持谨慎。人类价值体系无可替代,因此人类不会一落千丈或迷失自我。
哲学知识已经足够了,现在现实一点吧
RL如何管理单车停放处?
下图显示了在有无RL的情况下,一天当中单车的停放量。
· 蓝色线是无RL情况下的单车停放趋势。
· 黄色线是最初RL情况下移出单车的趋势,很昂贵。
· 绿色线是训练有素的RL,它仅移出足以满足目标的单车,更能了解成本。
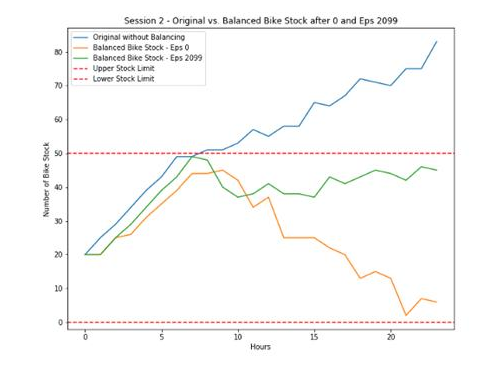
作者分析
RL如何决定该做什么?
以下是经过98,000次训练后RL解决方案Q表的快照。它解释了RL如何根据停放处(垂直数据)上的自行车数量来决定做什么(水平数据)。RL不太可能选择用红色进行操作。看看底部的红色区域。
作者分析
RL能有多智能?以下图表介绍了RL对停放处的管理情况。通过深入学习,RL可以将整体成功率逐步提高到98%,令人印象深刻。
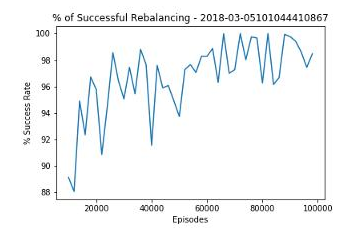
作者分析
希望大家喜欢这篇文章,并由衷地期待RL在现实世界中展示出的潜力。
-
人工智能
+关注
关注
1791文章
47044浏览量
238030 -
强化学习
+关注
关注
4文章
266浏览量
11234
发布评论请先 登录
相关推荐
蚂蚁集团收购边塞科技,吴翼出任强化学习实验室首席科学家
如何使用 PyTorch 进行强化学习
谷歌AlphaChip强化学习工具发布,联发科天玑芯片率先采用

增强现实是虚实结合吗为什么
增强现实技术的特点有哪些
虚拟现实技术和增强现实技术区别与联系
ar增强现实技术的特点是什么
通过强化学习策略进行特征选择

数字孪生:当数字科技遇上现实世界
增强现实ar是什么
一文详解Transformer神经网络模型






 工商网监
工商网监
评论