 Python快速入门指南基础知识详细说明
Python快速入门指南基础知识详细说明
随着人工智能大火,我们身边几乎处处充满着AL的气息,就连停车,都是机器人值班了。
可是很多人都不知道人工智能是由什么开发的,各种相关联的框架都是以Python作为主要语言开发出来的。
Python本身很普通,是所有编程语言中和自然语言或者说伪代码最像的,更为可贵的是其中一些特殊的库非常方便和强大,像numpy, scipy, matplotlib。
如果是一名新手想学习编程,一般都是选择python,因为更容易上手,并且,从Python学起,很快就能运用Python编程的底层逻辑去学习另外的语言,也就是说,学习Python是学习编程的绝佳起点。
接下来小编教大家如何快速入门,节约时间,能够一边工作一边学新知识!
学习基础知识
掌握元素(列表、字典、元组等)、变量、循环、函数等基础知识,达到能够熟练编写代码,至少不能出现语法错误。
1.交互式解释器
在命令行窗口执行python后,进入 Python 的交互式解释器。exit() 或Ctrl + D 组合键退出交互式解释器。
2.命令行脚本
在命令行窗口执行python script-file.py,以执行 Python 脚本文件。
3.指定解释器
如果在 Python 脚本文件首行输入#!/usr/bin/env python,那么可以在命令行窗口中执行/path/to/script-file.py以执行该脚本文件。
运算符合集
算术运算符:
比较运算符:
赋值运算符:
成员运算符:
这个阶段最重要的就是:学好基础知识。掌握了基础之后,便可以开始做项目练习锻炼编程思维了。
学习爬虫知识
所谓爬虫,就是按照一定的规则,自动的从网络中抓取信息的程序或者脚本。万维网就像一个巨大的蜘蛛网,我们的爬虫就是上面的一个蜘蛛,不断的去抓取我们需要的信息。
基础的抓取操作:
1、urllib
在Python2.x中我们可以通过urllib 或者urllib2 进行网页抓取,但是再Python3.x 移除了urllib2。只能通过urllib进行操作
带参数的urllib
url = 'https://blog.csdn.net/weixin_43499626'
url = url + '?' + key + '=' + value1 + '&' + key2 + '=' + value2
2、requests
requests库是一个非常实用的HTPP客户端库,是抓取操作最常用的一个库。Requests库满足很多需求
常见的反爬有哪些
1、通过user-agent来控制访问
user-agent能够使服务器识别出用户的操作系统及版本、cpu类型、浏览器类型和版本。很多网站会设置user-agent白名单,只有在白名单范围内的请求才能正常访问。所以在我们的爬虫代码中需要设置user-agent伪装成一个浏览器请求。
2、通过IP来限制
当我们用同一个ip多次频繁访问服务器时,服务器会检测到该请求可能是爬虫操作。因此就不能正常的响应页面的信息了。
存储
通过分析网页内容,获取到我们想要的数据,我们可以选择存到文本文件中,亦可以存储在数据库中,常用的数据库有MySql、MongoDB
存储为json文件
存储为cvs文件
存储到Mongo
以上知识虽然只是皮毛,给大家整理了一些知识,不过想要深入了解,还需要自己去学习, 在学习中有迷茫不知如何学习的朋友小编推荐去“蚁小二”,打破传统学习,每一课程一个小时就搞定,或者关注小编,传授你们更多python知识!
-
机器人
+关注
关注
210文章
28218浏览量
206582 -
人工智能
+关注
关注
1791文章
46881浏览量
237616 -
python
+关注
关注
56文章
4782浏览量
84467
发布评论请先 登录
相关推荐

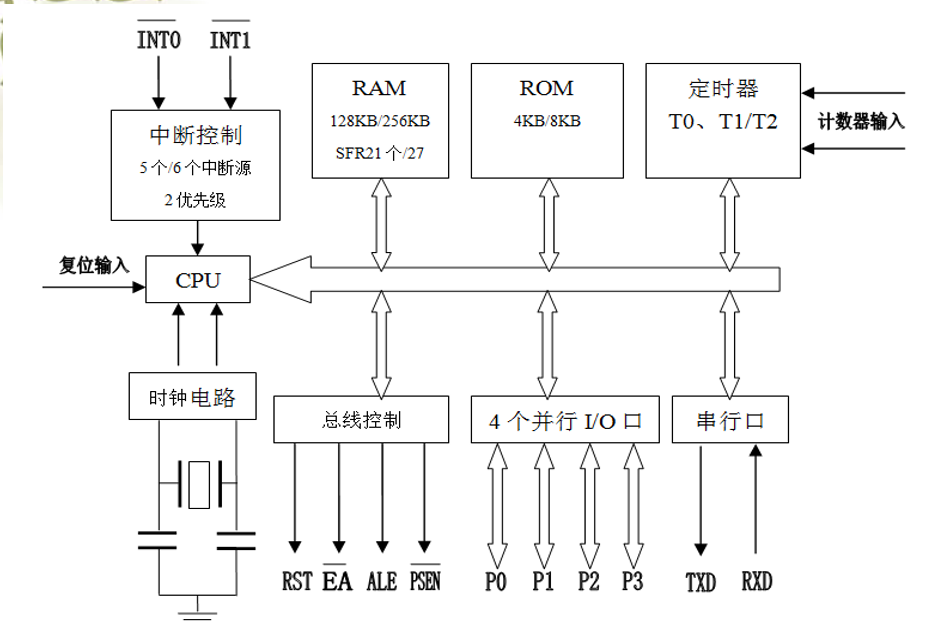
51单片机的结构及工作方式等基础知识详细说明

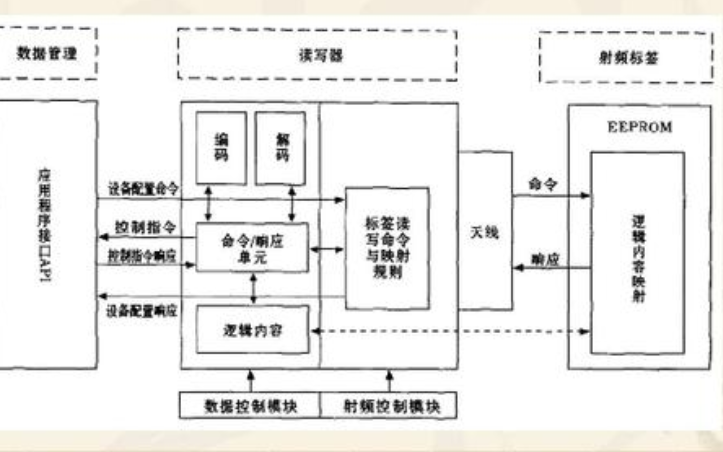
射频的基础知识培训教程详细说明

被动电子元器件的基础知识详细说明









 工商网监
工商网监
评论