 FPGA做深度学习加速的技能总结
FPGA做深度学习加速的技能总结

前言
做深度学习加速器已经两年了,从RTL设计到仿真验证,以及相应的去了解了Linux驱动,深度学习压缩方法等等。今天来捋一捋AI加速器都涉及到哪些领域,需要哪些方面的知识。可以用于AI加速器的主要有三种不同架构的器件种类:CPU,GPU,AI芯片/FPGA。CPU是一个通用架构芯片,其计算能力和数据带宽相对受到限制,面对大计算量的深度学习就显露出其缺点了。GPU含有大量的计算阵列,可以适用于大规模运算,而且其生态较为成熟和完整,所以现在包揽了所有的深度学习训练和绝大部分深度学习推理。要说有没有缺陷,经常被拿来比较的就是其功耗较大,而且并不是完全针对于深度学习网络的结构,所以还并不能完全利用其计算和存储资源。为了更有针对性的加速深度学习网络,AI芯片(FPGA)近两年也出现了。Intel、阿里平头哥、腾讯、百度等都开始设计自己的AI加速芯片,使用FPGA的有赛灵思、旷视科技等。FPGA用于深度学习加速和AI芯片的架构具有通用性,两者可以看做相同架构,只是用于不同硬件器件。而且通常AI芯片的前期验证也是用FPGA完成的。这篇文章就捋一捋FPGA在做深度学习加速时需要的技能。
1. 一张图
AI加速是一个同时涉及到软件和硬件的领域,下面一张简单的图罗列了AI加速器所有知识。
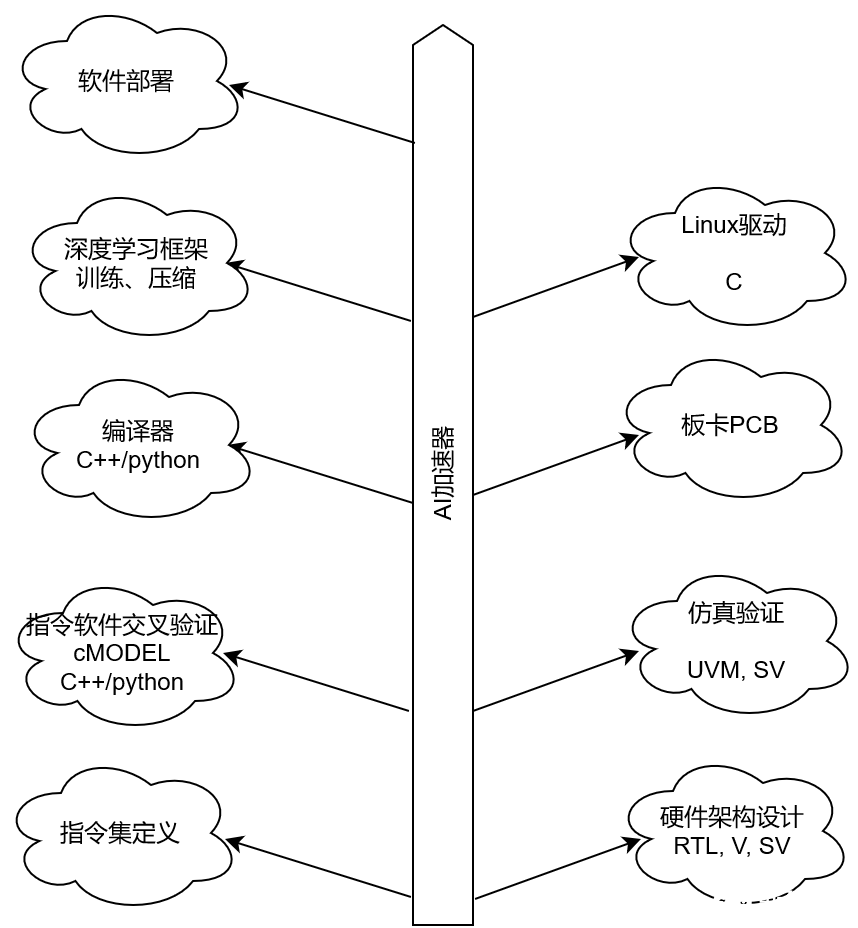
2. RTL
RTL部分设计主要考虑到以下几个方面:
1) 考察神经网络每个部分的计算量和参数数据,选择适合在FPGA上进行加速的部分。比如对于CNN网络,卷积运算占据整个网络的绝大部分计算,因此会占据FPGA中的绝大部分DSP资源。但是在卷积运算之间还存在激活函数、归一化等操作,这些虽然计算量不大,但是会对整个加速形成瓶颈,因此如何能够与卷积运算形成流水对性能影响也很大;
2) 设计加速算法。只要考虑好这两点就解决了主要问题:一个是计算资源利用率,另外一个是miss ratio。计算资源利用率包括FPGA上空间资源利用率,还包括计算资源的时间利用率。空间利用率越高,说明算力越高,时间利用率越高表明有效计算越高,加速效果越好。Miss ratio反映了片上cache存储的参数是否能够及时供给计算使用。如果能及时供给使用,那么从片外加载数据的时间就可以被压缩。
3) 架构的通用性。基本上架构都是基于指令集的,指令集主要依据加速器的计算核来定义的,算是复杂指令集。一个指令包含了参数的存储位置,需要数量,计算方式等等。由于深度网络操作数量比较单一,比如LSTM基本上就包括矩阵乘法、加法、向量乘法、激活等。大概也就有不超过10个指令就能涵盖一个LSTM网络了。为了适配这样的指令,架构大概包含以下结构:
外部总线:主要用于和外部ddr进行数据交互。
内部存储:储存要用到的参数和数据,及时供给计算核。Cache缓存是为了解决读取DDR带宽瓶颈问题。
指令解析:获取指令进行解析,发送给相应模块进行处理。
内部总线:为每个计算核提供数据读写通路。
计算核:张量计算核,用于加速神经网络计算。
计算核互联线:实现不同计算核之间的直接互联,可以实现不同计算核的pipeline。
Batch:包含了计算核、指令解析、计算核互联线等。当然如果内部cache并不是用的很多,一个batch也可以包含有内部cache。这些batch实际上可以看做神经网络运行的线程,多个batch就支持多线程神经网络计算。比如一个LSTM网络可以在有batch=2的硬件上同时进行两个句子的运算。
线程控制:用于控制多batch操作。
3. 验证
验证主要包括两个方面,一个是对指令集正确性进行验证,另外一个是对RTL代码进行仿真。指令集的验证需要有一个CMODEL来对编译器生成指令的正确性进行校验,校验准确才能够给硬件使用。因为仿真环境也需要随机化指令来对RTL代码进行校验,所以cmodel也会用于仿真环境中。我以UVM为例来说明,其基本结构如下:
指令随机化:对指令进行约束,生成随机指令;
指令驱动:将指令转换成文件,提供给cmodel,以及初始化到ddr文件中;
参数随机化:随机化权重等参数;
参数驱动:将参数初始化为ddr文件;
AXI驱动:这个包含AXI读写ddr文件的驱动,用于和DUT进行交互;
Monitor:监测DUT行为,和cmodel的数据进行对比;
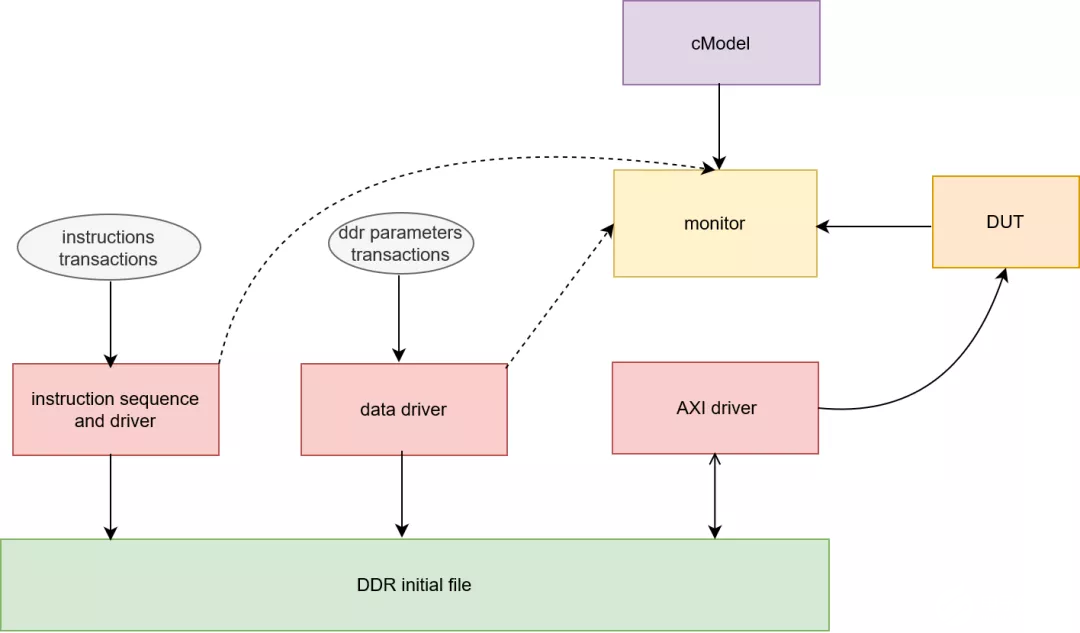
4. 驱动
驱动主要是完成ddr的初始化,线程控制的配置以及中断响应等。首先将权重等参数初始化到ddr中,然后通过axi总线配置FPGA的寄存器,同时对FPGA产生的中断进行响应。获取ddr中结果数据等。一般如zynq等SoC器件,因为集成了arm核,所以驱动相对简单。如果软件端在服务器,那么还需要PCIE等驱动来支持和服务器的交互。以SoC器件为例,linux驱动正常工作需要以下步骤:
1. 制作RTL硬件工程,生成bit文件和hardware配置文件;
2. 利用SDK生成fsbl文件,这个主要完成对zynq器件的一些基本硬件配置;
3. 制作linux的uboot、kernel、devicetree等文件;
4. 用fsbl、bit、uboot、kernel、devicetree制作boot.bin;
5. 选择linux文件系统,如linaro等。制作SD卡镜像,烧写到SD卡中,启动SoC器件;
5. 编译器
编译器主要能够根据深度学习模型来生成指令,并优化指令。以TVM为例,它基于计算图,对接市场上主流的深度学习框架:tensorflow、pytorch等,将这些模型进行计算图的转化,然后基于这些计算图来进行图的优化和指令优化。TVM目标是通用性,所以其兼容CPU、GPU、TPU,同时还要对接更多的深度学习框架。所以其很庞大。针对FPGA自身的AI加速器,可以以这个为借鉴,开发自己的compiler。同时依据自身硬件特点进行指令的优化。
计算图是基本很多编译器采用的图结构,其贯穿了指令优化和生成始终。计算图中的节点包含了数据信息和相应操作。这些节点相互连接形成了一个网络计算的依赖关系。计算图是一个基于tensor操作的图,它并不像通用CPU编译器的细化的标量操作。因为FPGA加速器中计算核一般都是张量操作。这是和CPU不同的。而且这样的计算图也相对简洁。
一个张量操作的实现有很多可能,因为依据数据之间的依赖关系和维度大小,可以对张量运算进行分解为多步操作。这些分解有很多。因此优化一个计算图就会面临很多这样可能的步骤。这被称为schedule,优化就是在这些schedule空间中找出最优的那个顺序。TVM中提出了一个基于机器学习模型的优化方法,去搜寻schedule空间,找到最适于硬件的图。然后生成指令。
6. 模型压缩
模型压缩有很多方法,根据压缩目标主要包括量化和剪枝。量化就是将浮点定点化,剪枝就是去除一些冗余的连接或者数据。从一些文献调研的结果有以下一些方式:
1) 二值化网络;
2) 向量压缩方法;
3) 知识蒸馏;
4) CP分解;
5) 降维分解;
6) 深度压缩;
7) 自动化搜索空间;
7. 软件部署
因为FPGA并不适合加速神经网络的所有部分或者还没有相应IP来加速一些模块,那么这些操作就会放在CPU上进行,比如对于LSTM网络,前边的embedding层还有后端的softmax或者类别生成。这些都更适合在CPU上做。因此软件部署来调用FPGA硬核IP,和FPGA进行交互。同时还有一些数据准备、打印等操作,客户展示。这些都是软件部署要做的。
总结
一个AI加速涉及到了算法、软件、驱动、硬件方面,因此通常做AI加速的团队都比较庞大,包含了算法到硬件的各种人才。
-
FPGA
+关注
关注
1663文章
22494浏览量
638982 -
AI
+关注
关注
91文章
40962浏览量
302531 -
深度学习
+关注
关注
73文章
5604浏览量
124609
发布评论请先 登录
算法工程师需要具备哪些技能?
Microsemi IGLOO2 FPGA与SmartFusion2 SoC FPGA深度剖析
机器学习和深度学习中需避免的 7 个常见错误与局限性

【团购】独家全套珍藏!龙哥LabVIEW视觉深度学习实战课(11大系列课程,共5000+分钟)
【团购】独家全套珍藏!龙哥LabVIEW视觉深度学习实战课程(11大系列课程,共5000+分钟)
从0到1,10+年资深LabVIEW专家,手把手教你攻克机器视觉+深度学习(5000分钟实战课)

如何深度学习机器视觉的应用场景
嵌入式需要掌握哪些核心技能?
如何在FPGA部署AI模型
如何在机器视觉中部署深度学习神经网络

Andes晶心科技推出新一代深度学习加速器
深度学习对工业物联网有哪些帮助
自动驾驶中Transformer大模型会取代深度学习吗?

FPGA在机器学习中的具体应用
基于FPGA的压缩算法加速实现



评论