 模拟内存计算迎来挑战 解决边缘AI推理迫在眉睫
模拟内存计算迎来挑战 解决边缘AI推理迫在眉睫
机器学习和深度学习已经成为我们生活中不可或缺的一部分。通过自然语言处理(NLP)、图像分类和对象检测的人工智能(AI)应用已经深入到我们许多设备中。大多数人工智能应用程序都是通过基于云的引擎提供服务,这些引擎可以很好地为它们的用途提供基础支持,比如在Gmail中输入电子邮件回复时获得单词预测。
尽管我们很享受这些人工智能应用所带来的好处,但这种方法也带来了隐私、功耗、延迟和成本方面的挑战。如果在数据起源处有一个本地处理引擎能够执行部分或全部计算(推理),则可以解决这些挑战。这在传统的数字神经网络实现中是很难做到的,在这种情况下,内存成为了耗电的瓶颈。这个问题可以通过多层内存和使用模拟内存计算方法来解决,这些计算方法可让处理引擎能够满足在网络边缘执行人工智能推断所需的更低的毫瓦到微瓦的功率要求。
云计算的挑战
当人工智能应用程序通过基于云的引擎提供服务时,用户必须上传一些数据到云中,由计算引擎处理数据,提供预测,并将预测发送到下游,供用户使用。
在这一进程中也有一些困难:
1.隐私和安全问题:对于始终在线的、感知的设备,人们担心个人数据在上传期间或在数据中心的存储期间被滥用。
2.不必要的功耗:如果每个数据位都被云计算占用,那么它就会消耗来自硬件、无线电、传输和云计算的能量。
3.小批量推理的延迟:如果数据来自边缘,则从基于云的系统获得响应可能需要一秒或更长的时间。对于人类的感官来说,任何超过100毫秒的延迟都是显而易见的。
4.数据经济:传感器无处不在,而且它们非常便宜;然而,他们产生了大量的数据。将所有数据上传到云端并进行处理似乎毫无经济可言。
通过使用本地处理引擎来解决这些挑战,执行推理操作的神经网络模型,首先要针对所需用例使用给定的数据集进行培训。通常,这需要高计算资源和浮点算术运算。因此,机器学习解决方案的训练部分仍然需要在公共或私有云(或本地GPU、CPU、FPGA场)上使用数据集完成,以生成最优的神经网络模型。一旦神经网络模型准备就绪,神经网络模型就不需要反向传播进行推理操作,因此该模型可以进一步针对具有小型计算引擎的本地硬件进行优化。一个推理引擎通常需要大量的多重累加(MAC)单元,然后是一个激活层,如整流线性单元(ReLU)、sigmoid或tanh,这取决于神经网络模型的复杂性和层之间的池化层。
大多数神经网络模型需要大量的MAC操作。例如,即使一个相对较小的“1.0 MobileNet-224”模型也有420万个参数(权重),需要5.69亿个MAC操作来执行推断。由于大多数模型由MAC操作主导,这里的重点将放在机器学习计算的这一部分,并探索创建更好的解决方案的机会。图2显示了简单的、完全连通的两层网络。
输入神经元(数据)使用第一层权值进行处理。第一层的输出神经元然后与第二层的权重进行处理,并提供预测(比如,该模型是否能够在给定的图像中找到一张猫脸)。这些神经网络模型使用“点积”来计算每一层的每一个神经元,如下式所示(为了简化,在方程中省略“偏差”项):
数字计算的内存瓶颈
在数字神经网络实现中,权值和输入的数据存储在DRAM/SRAM中。权重和输入数据需要移动到MAC引擎进行推理。如下图所示,这种方法在获取模型参数和将数据输入到实际MAC操作发生的算术逻辑单元(ALU)时消耗了大部分能量。
从能量的角度来看——一个典型的MAC操作使用数字逻辑门消耗大约250飞托焦耳(fJ,或10 - 15焦耳)的能量,但在数据传输过程中消耗的能量比计算本身要多两个数量级,大概在50皮焦耳(pJ,或10 - 12焦耳)到100pJ之间。
公平地说,有许多设计技术从内存到ALU的数据传输可以最小化;然而,整个数字方案仍然受到冯·诺依曼架构的限制——因此这为减少能源浪费提供了巨大的机会。如果执行MAC操作的能量可以从~100pJ降低到pJ的一个分数会是什么结果?
使用内存中的模拟计算消除内存瓶颈
当内存本身可以用来减少计算所需的功耗时,在边缘执行推理操作就变得非常省电。使用内存中的计算方法可以将必须移动的数据量最小化。这反过来又消除了数据传输过程中所浪费的能量。采用超低有功功率耗散、待机状态下几乎无能量耗散的闪速电池,也会进一步降低了系统的能量耗散。
这种方法的一个案例是来自Microchip公司的Silicon Storage Technology (SST) ——memBrain™技术。基于SST的SuperFlash®内存技术,解决方案包括一个内存计算架构,可以在存储推理模型的权重的地方进行计算。这消除了MAC计算中的内存瓶颈,因为权重没有数据移动——只有输入数据需要从输入传感器(如摄像头或麦克风)移动到内存阵列。
这个内存的概念基于两个因素:(a)模拟电流响应从一个晶体管是基于其阈值电压(Vt)和输入数据,和(b)基尔霍夫电流定律,即导体网络中在一点相接的电流的代数和为零。
理解基本的非易失性内存(NVM)位元组(bitcell)同等很重要,它被用在这种多层内存架构中。下图(图4)是两个ESF3(嵌入式SuperFlash第三代)位元的横截面,它们具有共享擦除门(EG)和源线(SL)。每个位元有五个终端:控制门(CG)、工作线(WL)、擦除门(EG)、源线(SL)和位线(BL)。擦除操作是通过在EG上施加高压来完成的。对WL、CG、BL、SL施加高/低电压偏置信号进行编程操作,对WL、CG、BL、SL施加低电压偏置信号进行读操作。
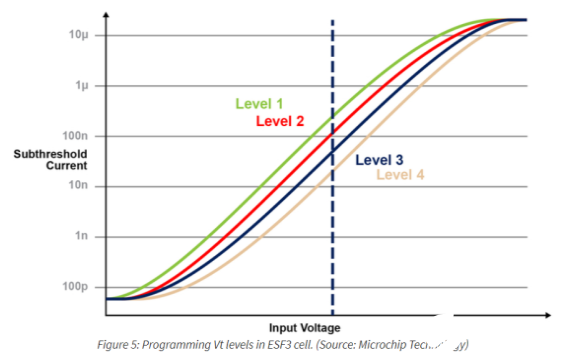
使用这种内存架构,用户可以通过细粒度的编程操作在不同的Vt级别上对内存位单元进行编程。该存储技术利用一种智能算法来调整存储单元的浮动门(FG) Vt,以实现输入电压的一定电流响应。根据最终应用的需要,我们可以在线性或阈下工作区域对单元进行编程。
下图演示了在内存单元上存储和读取多个级别的功能。假设我们试图在内存单元中存储一个2位整数值。对于这个场景,我们需要用2位整数值(00、01、10、11)的四个可能值中的一个对内存数组中的每个单元进行编程。下面的四条曲线是四种可能状态的IV曲线,电池的电流响应取决于施加在CG上的电压。
使用内存计算的乘法累加操作
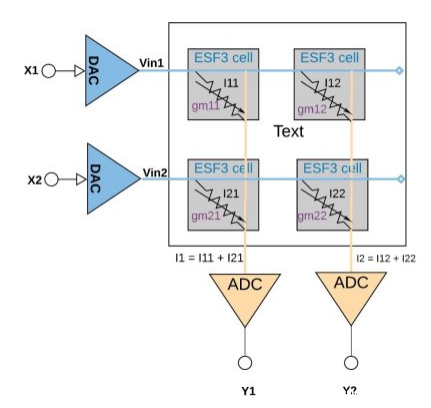
每个ESF3单元都可以建模为可变电导(gm)。电导的ESF3细胞取决于浮动栅Vt的编程细胞。将训练模型的权值编程为记忆单元的浮动门Vt,因此,单元的gm表示训练模型的权值。当输入电压(Vin)作用于ESF3电池时,输出电流(Iout)由公式Iout = gm * Vin给出,它是输入电压与储存在ESF3电池上的重量之间的乘法运算。
图6演示了一个小数组配置(2×2数组)中的乘法累加概念,其中累加操作是通过添加连接到同一列(例如I1 = I11 + I21)的输出电流来执行的。激活功能可以在ADC块内执行,也可以在内存块外的数字实现中执行,具体取决于应用程序。
我们在更高的层次上进一步阐明这一概念——来自训练模型的单个权值被编程为内存单元的浮动门Vt,因此来自训练模型的每一层(假设是一个全连接层)的所有权值都可以在一个物理上看起来像权值矩阵的内存阵列上编程。
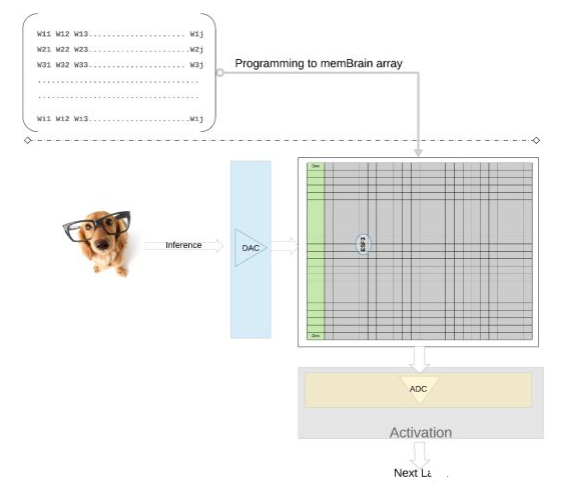
对于推理操作,我们首先使用数模转换器(DAC)将数字输入(比如图像像素)转换为模拟信号,并应用于内存阵列。然后,该阵列对给定的输入向量并行执行数千次MAC操作,并产生可进入相应神经元激活阶段的输出,然后使用模数转换器(ADC)将其转换回数字信号。数字信号在进入下一层之前被处理成池。
这种类型的内存架构非常模块化和灵活。许多memBrain块可以被拼接在一起,用混合权重矩阵和神经元构建各种大型模型,如下图所示。在本例中,一个3×4的拼接配置是与各个拼接之间的模拟和数字结构缝合在一起的,数据可以通过共享总线从一个tile移动到另一个tile。
到目前为止,我们主要讨论了该体系结构的硅实现过程。软件开发工具包(SDK)的可用性(图9)有助于解决方案的部署。除了硅之外,SDK还促进了推理引擎的部署。
SDK与培训框架无关。用户可以在任何可用的框架(如TensorFlow、PyTorch或其他框架)中使用浮点计算创建神经网络模型。一旦创建,SDK帮助量化训练过的神经网络模型,并将其映射到内存数组中,在内存数组中,向量-矩阵乘法可以用来自传感器或计算机的输入向量进行。
结论
这种具有内存计算能力的多级内存方法的优点:
1.超低功耗:该技术专为低功耗应用而设计。
第一级的功耗优势来自于内存计算,因此在计算期间不会在数据和从SRAM/DRAM传输的权值中浪费能量。
第二个能量优势来自于闪存单元在亚阈值模式下运行,电流值非常低,所以有源功耗非常低。
第三个优点,由于非易失性存储单元不需要任何能量来保存数据,所以在待机模式下几乎没有能量消耗。该方法也非常适合于利用权值和输入数据的稀疏性。如果输入数据或权值为零,则不会激活内存位单元。
2.更低的封装引脚
该技术使用分裂门(1.5T)单元架构,而数字实现中的SRAM单元基于6T架构。此外,与6T SRAM单元相比,该单元要小得多。另外,一个电池可以存储4位整数值,而SRAM电池需要4*6 = 24个晶体管才能存储整数值。这提供了更小的芯片占用空间。
3.更低的开发成本
由于内存性能瓶颈和冯诺依曼架构的限制,许多专用设备(如Nvidia的Jetsen或谷歌的TPU)倾向于使用更小的几何图形来获得每瓦的性能,这是解决边缘AI计算挑战的一种昂贵方式。随着多级存储器方法使用模拟存储器上的计算方法,计算在闪存芯片上完成,因此可以使用更大的几何图形,并减少掩模成本和前置时间。
由此可看,边缘计算应用程序显示了巨大的潜力。然而,在边缘计算能够腾飞之前,还有一些功率和成本方面的挑战需要解决。通过使用在闪存单元中执行芯片上计算的内存方法,可以消除其中的主要障碍。这种方法利用了经过生产验证的、事实上标准类型的多级内存技术解决方案,该解决方案针对机器学习应用程序进行了优化。
Vipin Tiwari
延伸阅读——Microchip-SST神经形态存储解决方案memBrain
Microchip公司通过其硅存储技术(SST)子公司,通过其模拟存储器技术memBrain神经形态存储器解决方案降低功耗,从而应对这一挑战。
该公司的模拟闪存解决方案基于其Superflash技术并针对神经网络进行了优化以执行矢量矩阵乘法(VMM),通过模拟内存计算方法改善了VMM的系统架构实现,增强了边缘的AI推理。
由于当前的神经网络模型可能需要50M或更多的突触(权重)进行处理,因此为片外DRAM提供足够的带宽变得具有挑战性,从而造成神经网络计算的瓶颈和整体计算能力的提高。相比之下,memBrain解决方案将突触权重存储在片上浮动门中,从而显着改善系统延迟。与传统的基于数字DSP和SRAM / DRAM的方法相比,它可以降低10到20倍的功耗并降低整体BOM。
“ 随着汽车,工业和消费者市场的技术提供商继续为神经网络实施VMM,我们的架构可帮助这些前向解决方案实现功耗,成本和延迟优势, ”SST许可部门副总裁Mark Reiten表示。“ Microchip将继续为AI应用提供高度可靠和多功能的Superflash内存解决方案。“
今天的公司正在采用memBrain解决方案来提高边缘设备的ML容量。由于具有降低功耗的能力,这种模拟内存计算解决方案非常适合任何AI应用。
“ Microchip的memBrain解决方案为我们即将推出的模拟神经网络处理器提供超低功耗的内存计算, ” Syntiant公司首席执行官Kurt Busch 说道。 “ 我们与Microchip的合作继续为Syntiant提供许多关键优势,因为我们支持普遍的ML边缘设备中语音,图像和其他传感器模式的永远在线应用。“
SST展示了这种模拟存储器解决方案,并在FMS上展示了Microchip的基于memBrain产品区块阵列的架构。
池化层理解
池化层夹在连续的卷积层中间, 用于压缩数据和参数的量,减小过拟合。简而言之,如果输入是图像的话,那么池化层的最主要作用就是压缩图像。
池化层的作用:
1. invariance(不变性),这种不变性包括translation(平移),rotation(旋转),scale(尺度)
2. 保留主要的特征同时减少参数(降维,效果类似PCA)和计算量,防止过拟合,提高模型泛化能力
-
内存
+关注
关注
8文章
3030浏览量
74117 -
AI
+关注
关注
87文章
31008浏览量
269355 -
机器学习
+关注
关注
66文章
8423浏览量
132744
发布评论请先 登录
相关推荐
研华科技边缘AI平台荣获2024年IoT边缘计算卓越奖
罗克韦尔自动化助您向可持续性生产目标迈进
NVIDIA IGX平台加速实时边缘AI应用

平衡创新与伦理:AI时代的隐私保护和算法公平
边缘AI需求爆发,边缘计算网关亟待革新
边缘AI网关,将具备更强大的计算和学习能力
如何基于OrangePi AIpro开发AI推理应用

ai边缘盒子有哪些用途?ai视频分析边缘计算盒子详解

边缘侧AI芯片提供商超星未来完成数亿元 Pre-B轮融资
三星电子瞄准边缘计算市场,计划2025年推出AI加速器芯片Mach-1
英特尔发布全新边缘计算平台,解决AI边缘落地难题






 工商网监
工商网监
评论