 CEVA推出全新DSP架构Gen4 CEVA-XC,在7nm下实现1.8GHz主频
CEVA推出全新DSP架构Gen4 CEVA-XC,在7nm下实现1.8GHz主频

3月12日消息,CEVA,全球领先的智能和互联设备信号处理平台和人工智能处理器IP 的授权许可厂商 (纳斯达克股票交易所代码:CEVA) 宣布推出世界上功能最强大的DSP架构Gen4 CEVA-XC。这款全新架构瞄准 5G 端点和无线接入网络(RAN)、企业接入点以及其他数千兆数据处理、且低延迟应用,针对这些应用所需的最复杂并行处理工作负载提供了无与伦比的性能。
- 第四代 CEVA-XC架构可提供1,600 GOPS的最高性能、创新的动态多线程和先进流水线,并且在7nm下实现1.8GHz主频
- CEVA-XC16 DSP是首个基于第四代 CEVA-XC架构的处理器,瞄准5G智能无线电接入网络(RAN)和企业接入点应用,可将峰值性能提高2.5倍
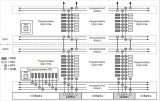
第四代 CEVA-XC 的强大架构统一了标量和矢量运算处理,可实现两次 8 路 VLIW 和前所未有的 14,000 位数据级并行。它采用的先进深层流水线架构使得在 7nm 工艺节点下可实现 1.8 GHz 主频,并使用了独特的物理设计架构来实现完全可综合的设计流程,以及创新的多线程设计,允许处理器动态地配置为宽 SIMD机或划分为较小的同时 SIMD 线程。第四代 CEVA-XC 架构还具有一个使用 2048 位内存带宽的新颖内存子系统,具有连贯一致的、紧耦合的内存,以支持高效的并发多线程和内存接入。
Linley Group 高级分析师 Mike Demler 表示:“ 第四代 CEVA-XC 架构是 CEVA 致力以行业领先的力度进行 DSP 并行处理的创新。这款架构具有动态可重配置的多线程和高速设计,以及用于控制和运算处理的全面功能,为用于 5G 基础架构和端点的 ASIC 和 ASSP 器件的普及发展奠定了基础。”
第一个基于第四代 CEVA-XC 架构的处理器是多核 CEVA-XC16,这是有史以来运行速度最快的 DSP 内核,瞄准各种形式的 5G RAN 体系结构的快速部署,包括开放式 RAN(O-RAN)、基带单元(BBU)聚合以及 Wi-Fi 和 5G 企业接入点。CEVA-XC16 还适用于与基站运作相关的海量信号处理和 AI 工作负载。
CEVA-XC16 在设计时充分考虑了最新的 3GPP 规范,并且基于 CEVA 与领先的无线基础架构供应商合作开发其蜂窝基础架构 ASIC 的丰富经验。CEVA 前代 CEVA-XC4500 和 CEVA-XC12 DSP 现在助力 4G 和 5G 蜂窝网络,并且一家领先的无线设备供应商已将新型 CEVA-XC16 用于其下一代 5G ASIC 设计。
CEVA-XC16 提供高达每秒 1600 GOPS 的高并行度性能,可以重新配置为两个单独的并行线程,两者可以同时运行,共享具有高速一致性缓存的 L1 数据存储器,从而直接提升 PHY 控制处理的延迟和性能效率,而无需使用额外的 CPU。相比在拥挤区域连接大量用户的单核 / 单线程架构,这些全新概念设计将每平方毫米的性能提高了 50%。这对于定制 5G 基站芯片普遍采用的大型内核集群而言,可节省 35%的芯片面积。
CEVA-XC16 的其他主要功能包括:
最新一代双 CEVA-BX 标量处理器单元——支持真正的并发多线程运行
可将矢量单位资源动态分配给处理线程——最好地利用矢量单位资源,并减少复杂流程的开销
先进的标量控制架构和工具,通过使用最新的动态分支预测和循环优化,以及基于 LLVM 的编译器,相比前代产品,可将代码大小减少 30%
用于 FFT 和 FIR 的全新指令集架构——可将性能提高两倍
增强的多用户功能,支持大带宽分配给单一用户也支持精细的用户分配
上代 CEVA-XC4500 和 CEVA-XC12 DSP 的软件可简单迁移
CEVA 副总裁兼移动宽带业务部门总经理 Aviv Malinovitch 表示:“5G 是一项具有跨越消费者、工业、电信和 AI 领域的多种增长矢量的技术,应对这些零散而复杂的用例需要全新的处理器思维和实践,而我们的第四代 CEVA-XC 架构采用了这一全新方法,通过突破性创新和设计实现了前所未有的 DSP 内核性能。CEVA-XC16 DSP 是这项成就的例证,并且为希望从不断增长的 5G 资产开支和 Open RAN 网络架构中获益的 OEM 厂商和半导体供应商大幅降低了进入门槛。”
责任编辑:gt
-
处理器
+关注
关注
68文章
20339浏览量
255328 -
dsp
+关注
关注
561文章
8277浏览量
368425 -
5G
+关注
关注
1368文章
49229浏览量
641125
发布评论请先 登录
3nm大规模导入光模块:Credo推出二代1.6T光DSP
Ceva NeuPro-Nano NPU 在 2026 年嵌入式世界大会上 荣获人工智能奖

Ceva新一代UWB IP具有更远的传输距离和更高的吞吐量

Ceva推出PentaG-NTN™ 5G高级调制解调器IP,助力卫星原生创新者快速部署差异化低地球轨道用户终端

XC7Z020-2CLG484I 双核异构架构 全能型 SoC
Ceva Wi-Fi 6 和蓝牙 IP 为瑞萨电子首款面向物联网和 智能家居的组合式 MCU 提供支持

BOS Semiconductors 选择 Ceva 的 AI DSP 用于下一代 ADAS 平台

Ceva 添加 Sensory 的 TrulyHandsfree 语音激活功能, 增强 NeuPro-Nano NPU 生态系统

Ceva在恩智浦的软件定义车辆处理器上实现 实时人工智能加速

钛金PCIe Gen4控制器的核心特性与技术细节

端侧AI赋能千行百业 2025 Ceva技术研讨会助力产业升级

Ceva推WiFi7 1x1客户端IP 助力打造更智能、更敏捷的人工智能物联网设备及新兴物理人工智能系统

Ceva引领下一代定位技术,率先推出带有信道探测功能之 蓝牙6.0认证IP,已经与十多家客户紧密合作

AMD 7nm Versal系列器件NoC的使用及注意事项



评论