 Facebook为人工智能研究开放轻量级交互式可视化库/工具HiPlot
Facebook为人工智能研究开放轻量级交互式可视化库/工具HiPlot
不久前,Facebook为人工智能研究开放了自家的轻量级交互式可视化库/工具HiPlot。它使机器学习研究人员和数据科学家可以大量使用平行绘图来分析相关性并观察高维数据中的模式。

什么是平行图?
平行图是将高维或多元数据可视化的便捷方法之一。
· 对于n个维度,绘制n条平行线,垂直且等间隔。这些用作轴。
· 每个数据点由一条折线表示,在平行轴上具有顶点。
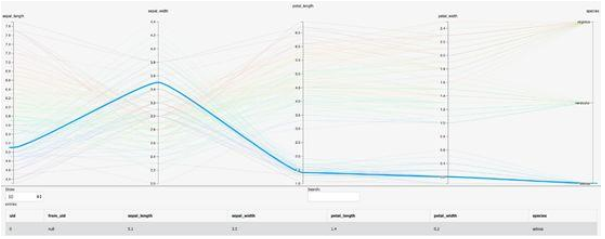
以下是使用ML 101 Iris数据集的直观示例。观察代表一个数据点的蓝色折线,并查看该数据点下面的表格记录。
为什么选择HiPlot?
机器学习的超参数调整
这就是Facebook构建HiPlot的目的。
由于神经网络需要调整从几个到数十个任意位置的超参数,因此可视化分析训练运行的能力对于进一步微调和构建性能模型至关重要。

HiPlot:过滤20个“历元”后获得的数据点,然后通过“有效ppl”轴进行切片。它表明,更高的学习率可以带来更好的表现。
多元数据探索性分析
以探索房屋数据这一熟悉场景为例。
· 可以使用HiPlot的交互式绘图对图表进行过滤和切片,从而快速查看昂贵的属性是否聚集在特定的邮政编码或城市内。
· 可以分析各种属性与房价之间的关系。
由于具有挖掘和分析高维数据点的能力,这些图比静态2D热力图或相关系数表具有更高的透明度和灵活性。
简单性和可扩展性
能够选择将HiPlot用作notebook中的python库或网络应用程序,就可以马上开始对其进行使用。有了支持自定义解析器、过滤和切片可视化内容的可共享URL之类的功能,HiPlot会优先考虑灵活性和协作性,还与Facebook的其他开源AI库的日志兼容。
入门
安装
pip install hiplot
安装后,可以通过两种方式使用Hiplot。
· 作为Jupyter Notebooks中的python库
import hiplot as hip
· 通过在终端/ 命令行中启动Web服务器,作为Flask Web应用程序:
(To launch as localhost)
》》》 hiplot(To enable sharing plot URLs)
》》》 hiplot --host 0.0.0.0
注意:要使用网络应用程序,必须实现附带实验提取器,这将在后文的“高级功能”部分中概述。
Notebook中的日常简单场景
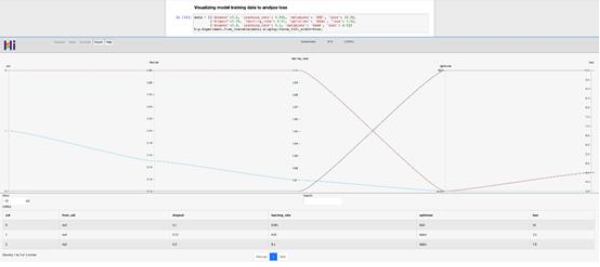
以下是利用HiPlot分析各种学习率,辍学率和优化器如何影响训练损失的日常使用案例。
import hiplot as hip
data = [
{‘dropout’:0.1,
‘learning_rate’: 0.001,
‘optimizer’: ‘SGD’,
‘loss’: 10.0
},
{‘dropout’:0.15,
‘learning_rate’: 0.01,
‘optimizer’: ‘Adam’,
‘loss’: 3.5
},
{‘dropout’:0.3,
‘learning_rate’: 0.1,
‘optimizer’: ‘Adam’,
‘loss’: 4.5
}]hip.Experiment.from_iterable(data).display(force_full_width=True)
图表及表格呈现如下。
是的,就是这么简单。
进阶能力
树与关系
看一个示例,这个例子希望通过指定后代关系来关联相关数据点。由于正在处理高维数据点,这使得可视化突然变得复杂。但是HiPlot帮你搞定了。
观察以下基于人口的训练示例,这是一种遗传算法,其中可以使用不同的超参数将训练任务多次分叉。属于同一训练代的数据点被连接起来。
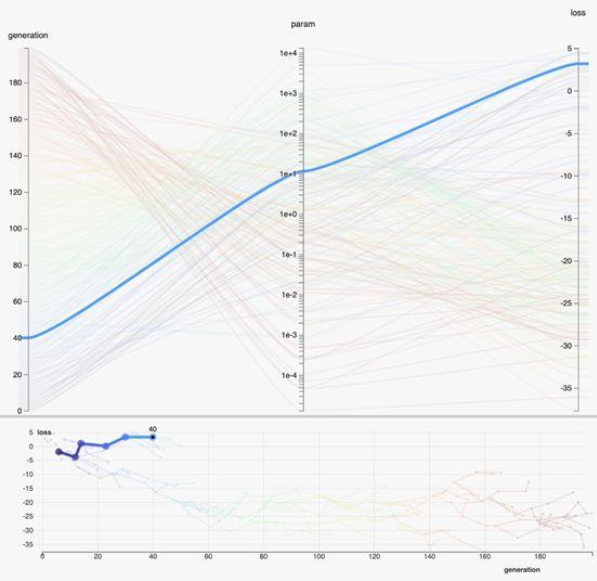
在上面的示例中,平行图下方的关系图显示了数据点之间的关系。在关系图中,每条折线代表一组连接的数据点,而折线中的每个顶点代表一个数据点。是的,它仍然是交互式的!因此,当鼠标悬停在关系图中的顶点上时,平行图中将突出显示相应的数据点。
下面是生成上面曲线的代码。关系随机分配,但要点很好把握。
exp = hip.Experiment()
exp.display_data(hip.Displays.XY).update({
‘axis_x’: ‘generation’,
‘axis_y’: ‘loss’,
})
for i in range(200):
dp = hip.Datapoint(
uid=str(i),
values={
‘generation’: i,
‘param’: 10 ** random.uniform(-1, 1),
‘loss’: random.uniform(-5, 5)
})
if i 》 10:
from_parent = random.choice(exp.datapoints[-10:])
# Connecting the parent to the child
dp.from_uid = from_parent.uid dp.values[‘loss’] += from_parent.values[‘loss’]
dp.values[‘param’] *= from_parent.values[‘param’]
exp.datapoints.append(dp)
实验提取器
将实验提取器视为美化的解析器,允许以可迭代和可绘制的形式提取,转换和加载数据。
如打算在网络应用程序模式下使用HiPlot,则必须实现实验提取器。如果是在notebook操作,只要对可视化数据采用表格形式或可迭代形式,就可不用读取器。
下面是一个实现实验提取器的示例。
提取程序:fetch_local_csv_experiment
提取程序前缀:localcsvxp://
目的:从本地文件系统加载CSV数据文件以进行可视化
import hiplot as hip
deffetch_local_csv_experiment(uri):
# Only apply this fetcher if the URI starts with webxp://
PREFIX=“localcsvxp://”
ifnot uri.startswith(PREFIX):
# Let other fetchers handle this one
raise hip.ExperimentFetcherDoesntApply()
# Parse out the local file path from the uri
local_path = uri[len(PREFIX):] # Remove the prefix
# Return the hiplot experiment to render
return hip.Experiment.from_csv(local_path)
使用网络应用程序
一旦实现了如上所述的实验提取器,就可以启动网络应用程序。
在示例中,fetch_local_csv_experiment提取程序(前缀localcsvxp://)存储在fetchers.py文件中。
可以在终端/命令行中以如下方式启动HiplotWeb服务器:
》》》 hiplotfetchers.fetch_local_csv_experiment --host 0.0.0.0
服务器将在一秒钟内启动。将URL复制到Web浏览器。
在突出显示的输入框中,用以下格式输入文件路径:
《fetcher_prefix》《file path》
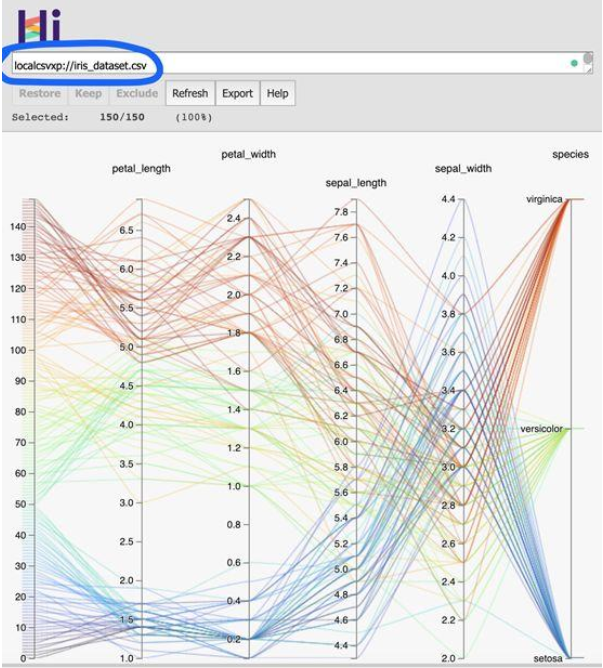
可以与其他人共享过滤后的视图的URL。为此,需要使用“--host 0.0.0.0”标志启动Web服务器。
-
神经网络
+关注
关注
42文章
4774浏览量
100899 -
Facebook
+关注
关注
3文章
1429浏览量
54812 -
人工智能
+关注
关注
1792文章
47432浏览量
238975
发布评论请先 登录
相关推荐
嵌入式和人工智能究竟是什么关系?
AI for Science:人工智能驱动科学创新》第4章-AI与生命科学读后感
《AI for Science:人工智能驱动科学创新》第一章人工智能驱动的科学创新学习心得
如何实现三维地图可视化交互系统
大屏数据可视化 开源





 工商网监
工商网监
评论