 赋予机器自主设计模型“能力”,一文概览结构搜索的起源
赋予机器自主设计模型“能力”,一文概览结构搜索的起源
伴随着人工智能技术的飞速发展,语音识别、机器翻译等各项科技名词已不是传统意义上被企业家束之高阁的前景应用,更不是研究人员讳莫如深的复杂概念,它们已经伴随着大数据时代的来临走入了寻常人的身边。如今的生活中我们无处不在享受着人工智能技术带给我们的便利,从前在科幻电影《星际迷航》中使用的通用翻译器,已然成为了现在人们出行途中能够使用的小型翻译机。而拨开这些实际应用的面纱,它们背后所使用的技术往往是这些年来备受关注的神经网络模型。
通俗来讲,它是一种对外部输入信息进行学习的数学模型或计算模型。它能够通过对自身内部结构的调整来拟合输入数据,凭借着算法广泛的通用性,其在语音、图像、自然语言处理等众多领域得到了广泛的应用。
电影《星际迷航》里科克船长和老骨头所使用的实时翻译设备
而对于目前的基于神经网络技术的各项任务而言,主要的过程依旧是由研究人员手动地探索新的网络结构,比如我们常见的循环神经网络(Recurrent neural network; RNN)、卷积神经网络(Convolutional Neural Network; CNN)等。但这样做实际上是一个非常系统工程的方式,我们把研究人员束缚在岗位上不断地去“设计”所谓的更好的结构,而模型的好与坏则往往取决于人对任务的理解以及模型设计上的想象力,整个过程需要研究人员对相关领域有着充分的认知,间接提高了从业人员的入门门槛,与此同时通过人工不断地对模型结构进行改良也非常耗费时间。
随着近年来计算机设备的算力以及存储能力逐年递增,人们逐渐开始去思考是否我们可以让计算机像学网络参数一样学习神经网络模型的结构?希望能通过这种方式将研究人员从模型结构设计者的位置上“解救”出来,于是就有了这样一个机器学习领域的研究分支——网络结构搜索(Neural Architecture Search; NAS)。
实际上目前神经网络结构搜索技术已经在各个领域中崭露头角,如谷歌团队在Searching for Activation Functions【1】论文中通过对激活函数空间进行搜索发现了Swish函数,相对诸如Relu等传统人工设计的激活函数具有更快的收敛速度。而微软团队在WMT19机器翻译评测任务中同样也采用了其团队提出的NAO【2】方法来自动地对神经网络结构进行优化,在英语-芬兰语以及芬兰语-英语的任务上均取得了不俗的成绩。
可以看到网络结构搜索技术的使用已经为各项任务中模型结构的设计起到非常好的助力,那么其背后究竟使用了怎样的技术?如何能够让神经网络自动地对自身结构进行改良?虽然目前网络结构的搜索技术依旧方兴未艾,但已然存在很多来自工业界以及学术界的团队在不断努力探索更好的方法。
可以预计在不远的将来,随着科研人员的努力以及计算资源的进一步提升,网络结构搜索的技术将大幅降低模型结构的更迭所需要的时间周期,同时能够让研究人员有更多地精力去探索有趣的应用或讨论神经网络背后的可解释性。当然在这个过程中,我们需要审视这门技术的发展历史,同时对未来的发展趋势进行展望。

微软团队在WMT19机器翻译评测任务中英语-芬兰语任务的提交信息
从“人工”到“自动”的突围
人类对于自动化的追求从未停止,这一点从三次工业革命的目标即可看到端倪,它们无一不在为了将人们从繁复的工作中解放出来不懈努力。而对于机器学习任务而言,人们也依旧在不断地探索,希望能够让机器在无需人类过多干预的情况下,真正地替代人去完成更多的工作,而在这个过程中研究人员始终在不断尝试,努力做好这次从“人工”到“自动”的突围。
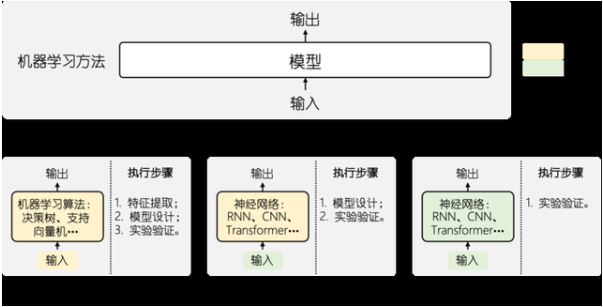
机器学习方法的演化与变迁
传统机器学习
如果我们将机器学习所处理的任务建模为一种从输入到输出的映射学习,那么在初代的机器学习算法中,我们不仅需要设计一种适用于当前任务的方法(如广泛使用的决策树、支持向量机等),同时还要为其提供人工设计的特征集合,在完成这些工作之后,才能使用数据对模型中的参数进行调优。
以情感分析为例,我们可以向模型中输入词性、词频及其情感属性等信息,然后通过支持向量机的模型来对情感分析任务进行建模,其中词性、词频以及情感属性即为我们从句子中提取出的人工设计的模型特征,支持向量机则是我们选择来解决当前问题的机器学习算法。
我们可以看到,不管是输入的特征还是模型自身,均为研究人员归纳总结而得,这个过程就很容易造成对有效特征的忽视以及模型设计上的不合理,因此基于这种传统机器学习算法的情感分析任务在IMDB Movie Reviews【3】集合上的准确率一般很难超过92%(如斯坦福大学的工作Baselines and Bigrams: Simple, Good Sentiment and Topic Classification【4】,通过使用朴素贝叶斯的方法在IMDB Movie Reviews数据集上也仅达到了91.22%的准确率)。可以看到在机器学习技术的初期,整个系统尚且处于对“人工”高度依赖的时代。
随着深度学习技术的广泛普及,人们开始尝试将提取特征的过程交由模型来自动完成,通过数据驱动的方式减少传统方法中特征遗漏的问题。比如说对于图像处理任务而言,我们无需根据人工经验对图像中的局部特征进行设计,只需要直接将画面完整地送入模型中进行训练即可。
下图中为人脸识别任务中不同层的神经网络对图像信息的抽取,我们可以看到在学习过程中底层网络主要是对图像中局部纹理进行捕捉,而随着层数的递增,模型开始根据下层中收集到的纹理信息对人脸中的局部结构(如眼睛、耳朵等)进行建模,而顶层将综合上述局部特征对人脸在图像中的位置进行确定,最终达成人脸识别的目的。
人脸识别任务中不同层对图像信息的提取差异
此外,对于前文提到的情感分析任务而言,同样是可以使用深度学习的方式对语言进行建模。相对基于传统机器学习算法的模型而言,深度学习的方式直接接收文本的输入,将词汇以高维向量的方式建模为词嵌入(word embedding)。这种方法利用高维空间对词汇中语义信息进行捕获,从而为下一步的情感分析提供了非常充足的信息。
基于深度学习的情感分析模型在IMDB Movie Reviews数据集上远远超越了传统的机器学习方法,在卡内基梅隆大学与谷歌团队在NIPS 2019上合作发表的论文XLNet: Generalized Autoregressive Pretraining for Language Understanding【5】中,准确率达到了96.8%。
从上述例子中可以看到,深度学习技术在如今的机器学习领域已然达成诸多优异成绩,其中非常重要的一个贡献在于通过使用自动提取的方式对初始输入信息中的有效资讯进行捕获,大幅度降低了手动设计特征所带来的信息折损,为下游任务提供了更坚实的基础。
深度学习&网络结构搜索
深度学习技术的到来使得原本由人工进行的特征提取过程交由机器自动完成,允许模型根据自身需求从原始数据中进行特征的捕获,通过这种数据驱动的方式有效降低了人工抽取所带来的信息丢失风险。但当我们回顾整个深度学习系统,实际上其依旧并非我们期望的完全自动化的过程,在模型结构的设计上仍然非常依赖行业专家面向任务对模型结构进行设计。
以机器翻译任务为例,研究人员在模型结构上的探索脚步从未停止,从最初基于RNN【6】对文本序列进行表示发展到之后注意力机制【7】的引入,乃至更近一段时间的基于CNN【8】的翻译系统以及目前备受关注的Transformer【9】系统,科研人员始终在不断地针对任务进行模型结构的设计与改良。但有了深度学习初期的发展,研究人员也期望着有朝一日能够让模型结构设计的过程同样不再过分依赖人工设计,能够采用同特征选择类似的方式自动进行学习,因此在深度学习方法的基础上,人们开始尝试网络结构搜索的方式来自动得到模型结构。
实际上网络结构搜索的任务并非起源于近些年,早在上世纪80年代,斯坦福大学的Miller, Geoffrey F.等人在Designing Neural Networks using Genetic Algorithms【10】论文中就提出使用进化算法对神经网络结构进行学习的方式,在此之后也有很多研究人员沿着该思路进行了相关的探索(如Representation and evolution of neural networks【11】一文对进化算法的编码格式进行改良,J. R. Koza等人在Genetic generation of both the weights and architecture for a neural network【12】中提出要同时对网络中的结构和参数进行学习等)。
但受限于当时计算资源,针对神经网络的结构搜索的应用场景较少,因此这方面的工作并没有受到很多研究者的关注。而随着近些年来神经网络以及深度学习的技术的广泛应用,对于网络结构自学习的需求也越来越大,与此同时发展迅猛的半导体技术也使得设备的算力、存储能力大大提升,为网络结构搜索任务提供了必要的支持。
纵观整个机器学习算法的发展过程,网络结构搜索任务的出现可以看作是历史的必然。无论是数据资源的累积还是计算能力的提升,无一不在催生着数据驱动下的网络结构设计。虽然目前的网络结构搜索技术尚且处于比较初级的阶段,其高资源消耗、模型结构不稳定等问题始终困扰着研究人员,但是其发展势头迅猛,在图像、自然语言处理等领域均开始崭露头角。
可以预见的是,深度学习&网络结构搜索的组合将是把研究人员从模型工程的泥淖中救起的稻草,我们也相信网络结构搜索技术会终将为机器学习完成这场从“人工”到“自动”的终局突围。
-
神经网络
+关注
关注
42文章
4767浏览量
100662 -
机器翻译
+关注
关注
0文章
139浏览量
14880 -
自然语言处理
+关注
关注
1文章
618浏览量
13541
发布评论请先 登录
相关推荐
【书籍评测活动NO.51】具身智能机器人系统 | 了解AI的下一个浪潮!
AI大模型与传统机器学习的区别
【「时间序列与机器学习」阅读体验】全书概览与时间序列概述
【《大语言模型应用指南》阅读体验】+ 基础篇
【《大语言模型应用指南》阅读体验】+ 俯瞰全书
多层感知机模型结构
Al大模型机器人
智能制造能力成熟度模型是什么?





 工商网监
工商网监
评论