 Google发布新API,支持训练更小更快的AI模型
Google发布新API,支持训练更小更快的AI模型
(文章来源:雷锋网)
Google发布了 Quantification Aware Training(QAT)API,使开发人员可以利用量化的优势来训练和部署模型AI模型。通过这个API,可以将输入值从大集合映射到较小集合的输出,同时,保持接近原始状态的准确性。
新的API的目标是支持开发更小、更快、更高效的机器学习(ML)模型,这些模型非常适合在现有的设备上运行,例如那些计算资源非常宝贵的中小型企业环境中的设备。
通常,从较高精度到较低精度的过程有很多噪声。因为量化把小范围的浮点数压缩为固定数量的信息存储区中,这导致信息损失,类似于将小数值表示为整数时的舍入误差(例如,在范围[2.0,2.3]中的所有值都可以在相同的存储中表示。)。问题在于,当在多个计算中使用有损数时,精度损失就会累积,这就需要为下一次计算重新标度。
谷歌新发布的QAT API通过在AI模型训练过程中模拟低精度计算来解决此问题。在整个训练过程中,将量化误差作为噪声引入,QAT API的算法会尝试将误差最小化,以便它学习这个过程中的变量,让量化有更强的鲁棒性。训练图是利用了将浮点对象转换为低精度值,然后再将低精度值转换回浮点的操作,从而确保了在计算中引入了量化损失,并确保了进一步的计算也可以模拟低精度。
谷歌在报告中给出的测试结果显示,在开源Imagenet数据集的图像分类模型(MobilenetV1 224)上进行测试,结果显示未经量化的精度为71.03%,量化后的精度达到了71.06%。
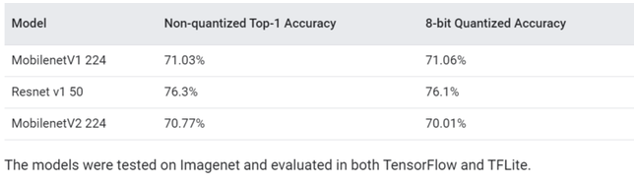
针对相同数据集测试的另一种分类模型(Nasnet-Mobile)中测试,在量化后仅有1%的精度损失(74%至73%)。除了模拟精度降低的计算外,QAT API还负责记录必要的统计信息,以量化训练整个模型或模型的一部分。比如,这可以使开发人员能够通过调用模型训练API将模型转换为量化的TensorFlow Lite模型。或者,开发人员可以在模拟量化如何影响不同硬件后端的准确性的同时尝试各种量化策略。

Google表示,在默认情况下,作为TensorFlow模型优化工具包一部分的QAT API配置为与TensorFlow Lite中提供的量化执行支持一起使用,TensorFlow Lite是Google的工具集,旨在将其TensorFlow机器学习框架上构建的模型能够适应于移动设备,嵌入式和物联网设备。“我们很高兴看到QAT API如何进一步使TensorFlow用户在其支持TensorFlow Lite的产品中突破有效执行的界限,以及它如何为研究新的量化算法和进一步开发具有不同精度特性的新硬件平台打开大门”,Google在博客中写道。
QAT API的正式发布是在TensorFlow Dev Summit上,也是在发布了用于训练量子模型的机器学习框架TensorFlow Quantum之后发布。谷歌也在会议的会话中预览了QAT API。
(责任编辑:fqj)
-
谷歌
+关注
关注
27文章
6209浏览量
106192 -
API
+关注
关注
2文章
1523浏览量
62518
发布评论请先 登录
相关推荐
Google两款先进生成式AI模型登陆Vertex AI平台
GPU是如何训练AI大模型的
使用英特尔AI PC为YOLO模型训练加速

在设备上利用AI Edge Torch生成式API部署自定义大语言模型

Google AI Edge Torch的特性详解






 工商网监
工商网监
评论