 Spark结构化流中的加水位线方法
Spark结构化流中的加水位线方法
对于流处理引擎来说,处理延迟到达的事件是至关重要的功能。 解决这个问题的方法是加水位线的概念。 从Spark 2.1开始,结构化流API就支持它。
什么是水位线?
加水位线是一种有用的方法,可帮助流处理引擎处理延迟。 基本上,水印是一个阈值,用于指定系统等待延迟事件的时间。 如果到达事件位于水位线之内,它将用于更新查询。 否则,如果它早于水位线,它将被丢弃,并且流引擎不会对其进行进一步处理。
> Flooding watermarks
如何使用它?
自Spark 2.1起,水位线被引入到结构化流API中。 您可以通过将withWatermark-Operator添加到查询中来启用它:
withWatermark(eventTime:String,delayThreshold:String):数据集[T]
它需要两个参数,a)一个事件时间列(必须与聚合正在处理的列相同)和b)一个阈值,用于指定应处理多长时间的延迟数据(以事件时间为单位)。 然后,Spark将维持聚合状态,直到max eventTime — delayThreshold> T,其中max eventTime是引擎看到的最新事件时间,T是窗口的开始时间。 如果后期数据落入此阈值之内,则查询将最终得到更新(下图中的右图)。 否则,它将被丢弃,并且不会触发任何重新处理(下图中的左图)。
> Late donkey in structured word count: event dropped (left), event within watermark updates Window
值得一提的是,查询的输出模式必须设置为"追加"(默认)或"更新"。完全模式不能与设计中的水印结合使用,因为它需要所有 要保存的数据,用于将整个结果表输出到接收器。
可以在这里找到如何在简单的Spark结构化流应用程序中使用该概念的快速演示-它是字数统计(对NLP进行了一些小的增强),还有其他:D
但是,为什么我要关心?
在分布式和联网的系统中,总会有中断的机会-节点故障,传感器丢失连接等等。 因此,不能保证数据将按创建顺序到达流处理引擎。 为了容错,因此有必要处理此类乱序数据。
为了解决此问题,必须保留聚合状态。 如果发生延迟事件,则可以重新处理查询。 但这意味着所有聚合的状态必须无限期地保持,这也导致内存使用量也无限期地增长。 除非系统具有无限的资源(即无限的预算),否则在现实世界中这是不切实际的。 因此,加水位线是一个有用的概念,可以通过设计约束系统并防止其在运行时爆炸。
-
API
+关注
关注
2文章
1502浏览量
62050 -
SPARK
+关注
关注
1文章
105浏览量
19918
发布评论请先 登录
相关推荐
结构化布线在AI数据中心的关键作用
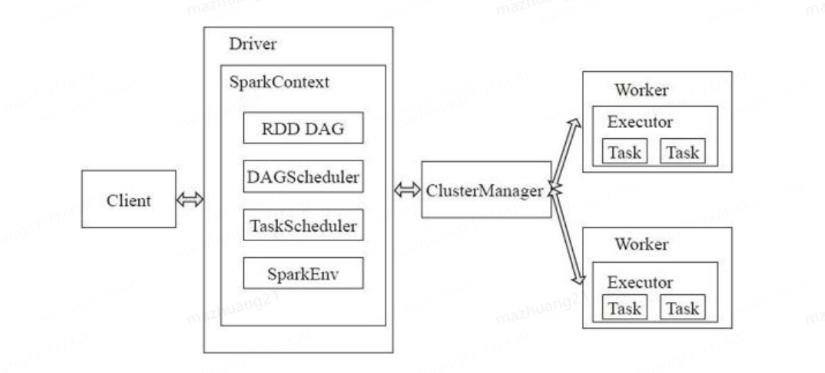
spark运行的基本流程
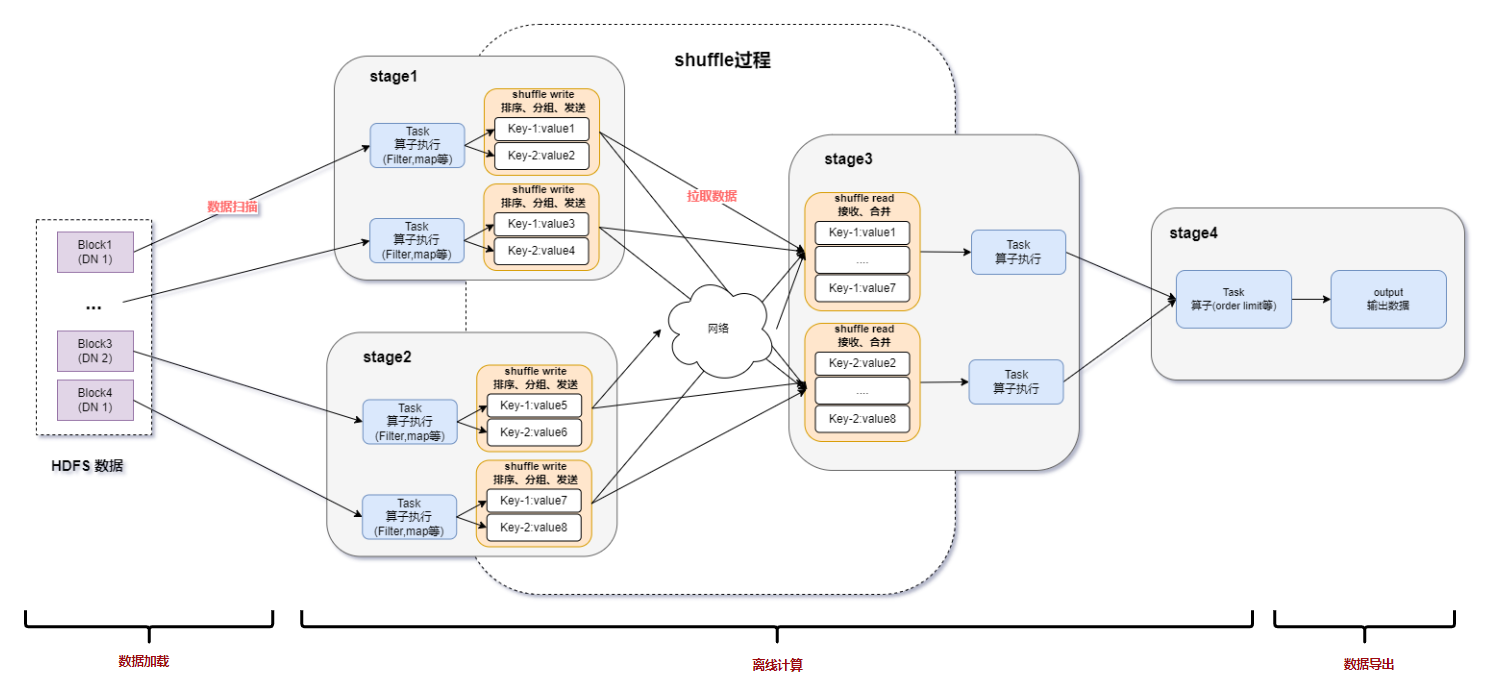
Spark基于DPU的Native引擎算子卸载方案

水位传感器怎么测好坏
定期维护结构化布线对于办公室得重要性
什么是结构化网络布线?结构化网络布线有哪些好处?
结构化布线的好处多吗
什么是网络系统中的结构化布线?
Spark基于DPU Snappy压缩算法的异构加速方案
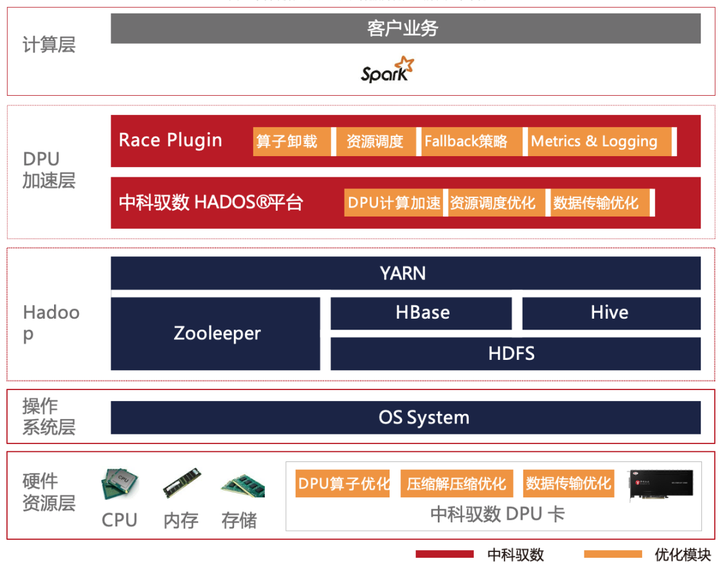
RDMA技术在Apache Spark中的应用

基于DPU和HADOS-RACE加速Spark 3.x
水位传感器怎么调水位高低
科通技术推出基于FPGA的应用设计结构化技术
从记录的传感器数据中获取驾驶场景





 工商网监
工商网监
评论