 解决机器学习中有关学习率的常见问题
解决机器学习中有关学习率的常见问题
什么是学习率?它的用途是什么?
神经网络计算其输入的加权和,并通过一个激活函数得到输出。为了获得准确的预测,一种称为梯度下降的学习算法会在从输出向输入后退的同时更新权重。
梯度下降优化器通过最小化一个损失函数(L)来估计模型权重在多次迭代中的良好值,这就是学习率发挥作用的地方。它控制模型学习的速度,换句话说,控制权重更新到l最小点的速度。新(更新后)和旧(更新前)权重值之间的关系如下:

学习率是否为负值?
梯度L/w是损失函数递增方向上的向量。L/w是L递减方向上的向量。由于η大于0,因此是正值,所以-ηL/w朝L的减小方向向其最小值迈进。如果η为负值,则您正在远离最小值,这是它正在改变梯度下降的作用,甚至使神经网络无法学习。如果您考虑一个负学习率值,则必须对上述方程式做一个小更改,以使损失函数保持最小:

学习率的典型值是多少?
学习率的典型值范围为10 E-6和1。
梯度学习率选择错误的问题是什么?
达到最小梯度所需的步长直接影响机器学习模型的性能:
小的学习率会消耗大量的时间来收敛,或者由于梯度的消失而无法收敛,即梯度趋近于0。
大的学习率使模型有超过最小值的风险,因此它将无法收敛:这就是所谓的爆炸梯度。

梯度消失(左)和梯度爆炸(右)
因此,您的目标是调整学习率,以使梯度下降优化器以最少的步数达到L的最小点。通常,您应该选择理想的学习率,该速率应足够小,以便网络能够收敛但不会导致梯度消失,还应足够大,以便可以在合理的时间内训练模型而不会引起爆炸梯度。
除了对学习率的选择之外,损失函数的形状以及对优化器的选择还决定了收敛速度和是否可以收敛到目标最小值。
错误的权重学习率有什么问题?
当我们的输入是图像时,低设置的学习率会导致如下图所示的噪声特征。平滑、干净和多样化的特征是良好调优学习率的结果。是否适当地设置学习率决定了机器学习模型的预测质量:要么是进行良好的训练,要么是不收敛的网络。
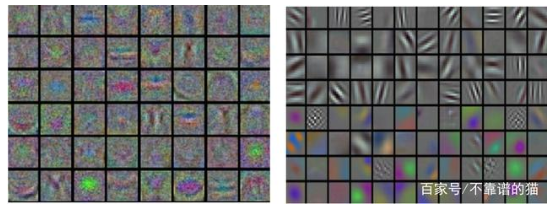
绘制神经网络第一层产生的特征:不正确(左)和正确(右)设置学习率的情况
我们可以事先计算出最佳学习率吗?
通过理论推导,不可能计算出导致最准确的预测的最佳学习率。为了发现给定数据集上给定模型的最佳学习率值,必须进行观察和体验。
我们如何设置学习率?
以下是配置η值所需了解的所有内容。
使用固定学习率:
您确定将在所有学习过程中使用的学习率的值。这里有两种可能的方法。第一个很简单的。它由实践中常用的常用值组成,即0.1或0.01。第二种方法,您必须寻找适合您的特定问题和神经网络架构的正确学习率。如前所述,学习率的典型值范围是10 E-6和1。因此,你粗略地在这个范围内搜索10的各种阶数,为你的学习率找到一个最优的子范围。然后,您可以在粗略搜索所找到的子范围内以较小的增量细化搜索。你在实践中可能看到的一种启发式方法是在训练时观察损失,以找到最佳的学习率。
学习率时间schedule的使用:
与固定学习率不同,此替代方法要求根据schedule在训练epochs内改变η值。在这里,您将从较高的学习率开始,然后在模型训练期间逐渐降低学习率。在学习过程的开始,权重是随机初始化的,远远没有优化,因此较大的更改就足够了。随着学习过程的结束,需要更完善的权重更新。通常每隔几个epochs减少一次学习Learning step。学习率也可以在固定数量的训练epochs内衰减,然后对于其余的训练epochs保持较小的恒定值。
常见的两种方案。第一种方案,对于固定数量的训练epochs,每次损失平稳(即停滞)时,学习率都会降低。第二种方案,降低学习率,直到达到接近0的较小值为止。三种衰减学习率的方法,即阶跃衰减、指数衰减和1/t衰减。
在SGD中添加Momentum:
它是在经典的SGD方程中加入一项:

这个附加项考虑了由于Vt-1而带来的权重更新的历史,Vt-1是过去梯度的指数移动平均值的累积。这就平滑了SGD的进程,减少了SGD的振荡,从而加速了收敛。然而,这需要设置新的超参数γ。除了学习率η的挑战性调整外,还必须考虑动量γ的选择。γ设置为大于0且小于1的值。其常用值为0.5、0.9和0.99。
自适应学习率的使用:
与上述方法不同,不需要手动调整学习率。根据权重的重要性,优化器可以调整η来执行更大或更小的更新。此外,对于模型中的每个权重值,都确保了一个学习率。Adagrad,Adadelta,RMSProp和Adam是自适应梯度下降变体的例子。您应该知道,没有哪个算法可以最好地解决所有问题。

学习率配置主要方法概述
学习率的实际经验法则是什么?
学习率是机器学习模型所依赖的最重要的超参数。因此,如果您不得不设置一个且只有一个超参数,则必须优先考虑学习率。
机器学习模型学习率的调整非常耗时。因此,没有必要执行网格搜索来找到最佳学习率。为了得到一个成功的模型,找到一个足够大的学习率使梯度下降法有效收敛就足够了,但又不能大到永远不收敛。
如果您选择一种非自适应学习率设置方法,则应注意该模型将具有数百个权重(或者数千个权重),每个权重都有自己的损失曲线。因此,您必须设置一个适合所有的学习率。此外,损失函数在实际中往往不是凸的,而是清晰的u形。他们往往有更复杂的非凸形状局部最小值。
自适应方法极大地简化了具有挑战性的学习率配置任务,这使得它们变得更加常用。此外,它的收敛速度通常更快,并且优于通过非自适应方法不正确地调整其学习率的模型。
SGD with Momentum,RMSProp和Adam是最常用的算法,因为它们对多种神经网络架构和问题类型具有鲁棒性。
-
神经网络
+关注
关注
42文章
4785浏览量
101279 -
函数
+关注
关注
3文章
4350浏览量
63056 -
机器学习
+关注
关注
66文章
8453浏览量
133167
发布评论请先 登录
相关推荐
嵌入式机器学习的应用特性与软件开发环境
传统机器学习方法和应用指导

如何选择云原生机器学习平台
zeta在机器学习中的应用 zeta的优缺点分析
什么是机器学习?通过机器学习方法能解决哪些问题?

NPU与机器学习算法的关系
电路设计常见问题解答
人工智能、机器学习和深度学习存在什么区别

【「时间序列与机器学习」阅读体验】+ 简单建议
机器学习中的数据分割方法
人工智能、机器学习和深度学习是什么
机器学习算法原理详解
深度学习与传统机器学习的对比
傅里叶变换基本原理及在机器学习应用





 工商网监
工商网监
评论