 机器学习特征选择的三种方法
机器学习特征选择的三种方法
特征选择,这是一个在机器学习中非常重要的东西,那些好的特征可以从整体上来提升模型的性能,可以帮助我们更加清晰的理解真个数据的特点及底层结构,对于后面的模型,算法有着非常重要的作用。
备注:在很多情况下,特征选择并非必要的,业务特征的选择有很强烈的业务契合度在里面,代表着这些特征在业务中的重要性也是很高,如果去掉,很有可能会有一定的副作用,但是无法说清这个副作用,这个需要进入到训练中去训练数据来验证这个效果。
特征选择作用
这里有些同学可能是刚开始接触做特征选择,并不是很了解为什么要做特征选择,做了有什么作用?是否只是简单地减少特征?是否这样子做了,对结果有没有影响?
这里每个人都有自己的理解,小编根据自己的经验,总结有两个,参考一下:
1、减少特征的数量,降低维度,这样子可以在一定程度上加强模型的泛化能力,从而尽可能地减少过拟合,这里要注意一下:过拟合只能减少,无法消灭,好比这个世上,其实没有最优解的一样,拥有的只有不满足。
2、在一定程度上降低特征后,从直观上来看,很多时候可以一目了然看到特征与特征值之间的关联,这个场景,需要实际业务的支撑,生产上的业务数据更加明显,有兴趣的同学可以私信我加群,一起研究。
特征选择从何入手
这是一个非常重要的问题,有很多同学可能刚开始接触或者想往这方面发展,拿到了一组数组,很多时候就是直接拿了一个算法,直接做分类或者做回归或者做聚类,但是这样子正常情况下,数据会存在很多噪音(科普:噪音可以理解为一些垃圾数据,对我们的结果或者期望造成了干扰),这样子的数据不会很好。
那如果我要特征选择呢,又不知从何入手?
这里有两个方法,可以作为参考:
1、从业务范围分析,直接观察特征与业务的相关性,这点非常重要,那些对业务有着直接指标的数据,建议保留,否则,可以考虑手动删除掉。
2、从发散特性分析,这个很多同学毕业后,就忘了这个东西,简单用成语一个成语来理解一下:一成不变。如果这个特征满足这种条件,那证明不发散,其实在数学中,用方差来计算的,这种不发散的特征,基本就没有什么差异性了,例如某一项特征都是0,怎么有影响呢,这样子的特征其实就没什么用。
特征选择的三种方法
进行特征选择的时候,其实有一定的方法或者规律可言,总结起来有三个
1、过滤法:目前这是小编用的最普遍的方法,因为最简单,与业务契合度最高,操作过程就是我可以设定某一个阈值,然后根据数据的发散情况或者与业务是否相关来打分,一般都是当低于这个阈值的时候,就可以考虑过滤掉。
2、嵌入法:这个方法无法直接从字面来理解,但是其实也是很好的东西,小编把它叫做过滤法的进化版。如何理解这个进化版,原先我们采用过滤法的时候,很多时候是人肉直接撸一撸,但是这时候特征多呢,给你200个特征,然后我就可能瞎了或者手废掉了,此时的做法是此案用机器学习的算法或者模型来训练,然后可以得到各个特征的权重值,做个排序,干掉那些排序地的,例如树的特征选择,这些算法,后面会逐一介绍。
3、包装法:听这个名字,是不是也是很迷糊,其实这个也比较好理解,不断循环训练模型,进行目标函数的计算,一般我们是采用预测的效果来评分,逐一选择一定量的特征来做,不断循环,得到结果进行对比,这样就可以看到哪些特征不好。不过这个小编比较少用,计算上比较费时费力,后面的具体算法也会介绍到。
-
算法
+关注
关注
23文章
4608浏览量
92845 -
机器学习
+关注
关注
66文章
8408浏览量
132580
发布评论请先 登录
相关推荐
光纤测试方法有哪三种
MCUXpresso IDE下在线联合调试双核MCU工程的三种方法
数字示波器的测量方法有哪三种
机器学习中的数据预处理与特征工程
人脸检测的五种方法各有什么特征和优缺点
abb工业机器人手动操作有哪三种模式?

信号调制的三种基本方法
三种常见的光纤光缆链接方法
放大电路有哪三种基本分析方法?举例说明
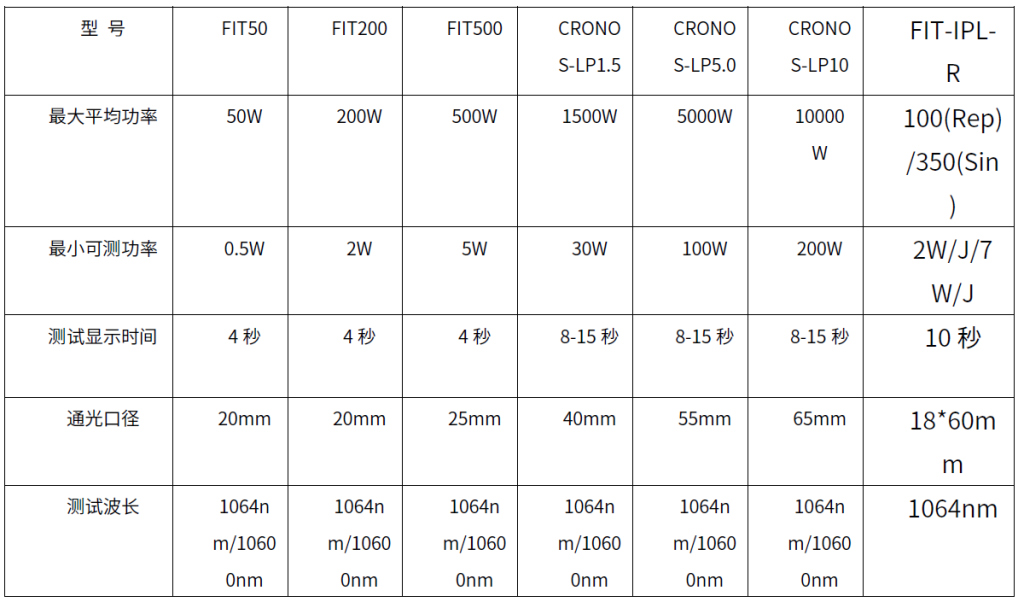

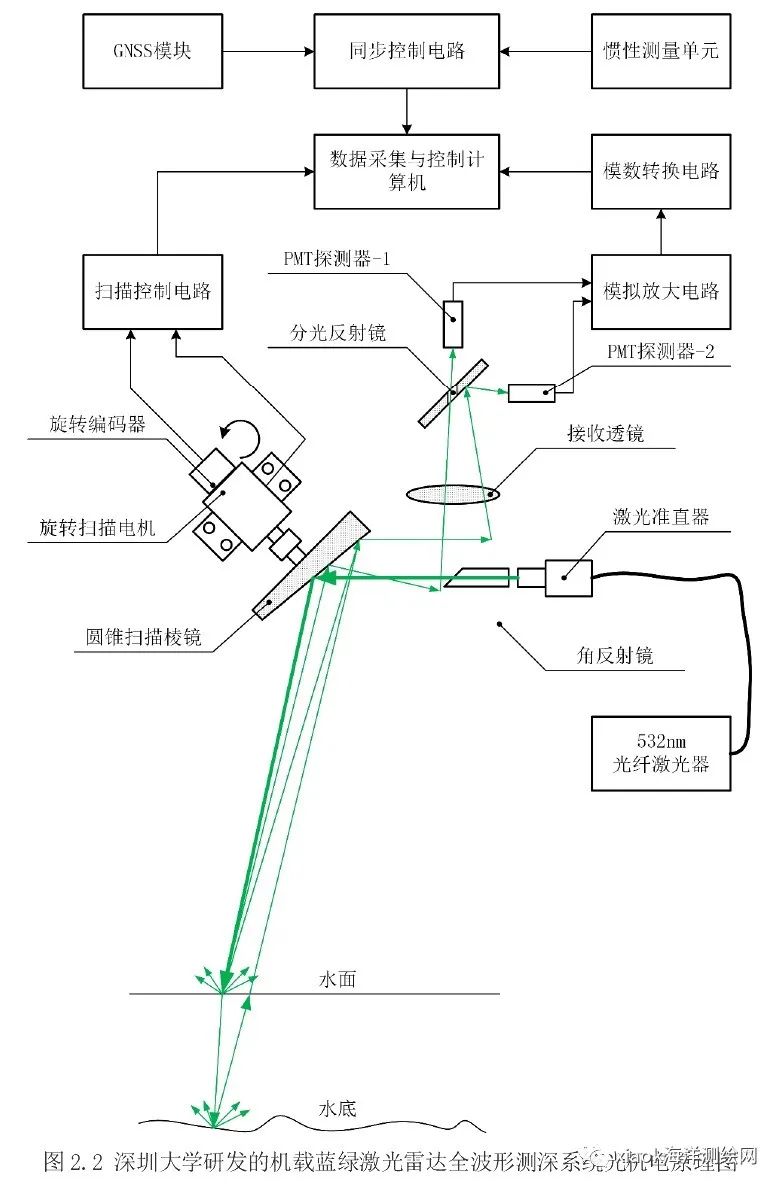
无人机测深的三种方法总结





 工商网监
工商网监
评论