 流数据是一个在机器学习领域蓬勃发展的概念
流数据是一个在机器学习领域蓬勃发展的概念
概述
流数据是一个在机器学习领域蓬勃发展的概念
学习如何使用PySpark来利用机器学习模型对流数据进行预测
我们将介绍流数据和Spark Streaming的基础知识,然后深入到实现部分
引言
想象一下——每一秒都有8,500多条推文发布,900多张照片被上传到Instagram,4,200多个Skype呼叫,78,000多次Google搜索,以及200多万封电子邮件被发送(数据来自InternetLive Stats)。
我们正在以前所未有的速度和规模生产数据。这是在数据科学领域工作的大好时候!但是有了大量的数据后,接踵而至的是复杂的挑战。
首要,如何收集大规模的数据?如何确保一旦生成并收集数据,机器学习管道就会继续产生结果?这些都是业界面临的重大挑战,以及为什么流数据的概念在企业中越来越受到关注。
增加处理流数据的能力将极大地扩展当前的数据科学产品投资组合。这是业界急需的技能,若能熟练掌握它,将帮助你担负起下一个数据科学角色。
因此,在本文中,我们将学习什么是流数据,了解Spark Streaming的基础知识,然后在一个业界相关的数据集上使用Spark实现流数据。
什么是流数据?
社交媒体产生的数据是惊人的。你敢于想象存储所有数据需要些什么吗?这是一个复杂的过程!因此,在深入探讨本文的Spark方面之前,先来理解什么是流数据。
流数据没有离散的开始或结束。这些数据是每秒从数千个数据源中生成的,它们需要尽快进行处理和分析。大量流数据需要实时处理,例如Google搜索结果。
我们知道,在事件刚发生时一些见解会更有价值,而随着时间的流逝它们会逐渐失去价值。以体育赛事为例——我们希望看到即时分析,即时统计见解,在那一刻真正享受比赛,对吧?
例如,假设你正在观看一场罗杰·费德勒(Roger Federer)对战诺瓦克·乔科维奇(Novak Djokovic)的激动人心的网球比赛。
这场比赛两局打平,你想了解与费德勒的职业平均水平相比,其反手发球的百分比。是在几天之后看到有意义,还是在决胜局开始前的那一刻看到有意义呢?
Spark Streaming的基础知识
Spark Streaming是核心Spark API的扩展,可实现实时数据流的可伸缩和容错流处理。
在转到实现部分之前,先了解一下Spark Streaming的不同组成部分。
离散流
离散流(Dstream)是一个连续的数据流。对于离散流,其数据流可以直接从数据源接收,也可以在对原始数据进行一些处理后接收。
构建流应用程序的第一步是定义要从中收集数据的数据资源的批处理持续时间。如果批处理持续时间为2秒,则将每2秒收集一次数据并将其存储在RDD中。这些RDD的连续序列链是一个DStream,它是不可变的,可以通过Spark用作一个分布式数据集。

考虑一个典型的数据科学项目。在数据预处理阶段,我们需要转换变量,包括将分类变量转换为数字变量,创建分箱,去除异常值和很多其他的事。Spark保留了在数据上定义的所有转换的历史记录。因此,无论何时发生故障,它都可以追溯转换的路径并重新生成计算结果。
我们希望Spark应用程序7 x 24小时持续运行。并且每当故障发生时,我们都希望它能尽快恢复。但是,在大规模处理数据的同时,Spark需要重新计算所有转换以防出现故障。可以想象,这样做的代价可能会非常昂贵。
缓存
这是应对该挑战的一种方法。我们可以暂时存储已计算(缓存)的结果,以维护在数据上定义的转换的结果。这样,当发生故障时,就不必一次又一次地重新计算这些转换。
DStreams允许将流数据保留在内存中。当我们要对同一数据执行多种运算时,这很有用。
检查点
高速缓存在正常使用时非常有用,但是它需要大量内存。并不是每个人都有数百台具有128 GB内存的计算机来缓存所有内容。
检查点的概念能够有所帮助。
检查点是另一种保留转换后的数据框结果的技术。它将不时地将正在运行的应用程序的状态保存在任何可靠的存储介质(如HDFS)上。但是,它比缓存慢,灵活性也更差。
在拥有流数据时可以使用检查点。转换结果取决于先前的转换结果,并且需要保存以供使用。此外,我们还存储检查点元数据信息,例如用于创建流数据的配置以及一系列DStream操作的结果等。
流数据的共享变量
有时候需要为必须在多个集群上执行的Spark应用程序定义诸如map,reduce或filter之类的函数。在函数中使用的变量会被复制到每台机器(集群)中。
在这种情况下,每个集群都有一个不同的执行器,我们想要一些可以赋予这些变量之间关系的东西。
例如:假设Spark应用程序在100个不同的集群上运行,它们捕获了来自不同国家的人发布的Instagram图片。
现在,每个集群的执行者将计算该特定集群上的数据的结果。但是我们需要一些帮助这些集群进行交流的东西,以便获得汇总结果。在Spark中,我们拥有共享变量,这些变量使此问题得以克服。
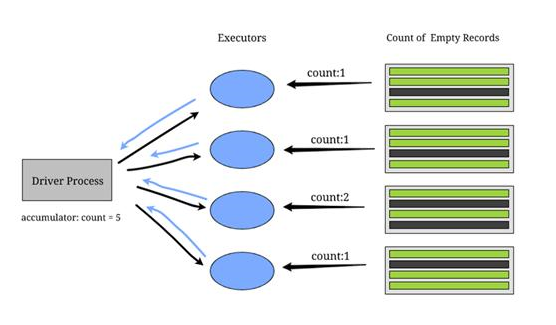
累加器变量
用例包括发生错误的次数,空白日志的数量,我们从特定国家收到请求的次数——所有这些都可以使用累加器解决。
每个集群上的执行程序将数据发送回驱动程序进程,以更新累加器变量的值。 累加器仅适用于关联和可交换的运算。例如,对求和和求最大值有用,而求平均值不起作用。
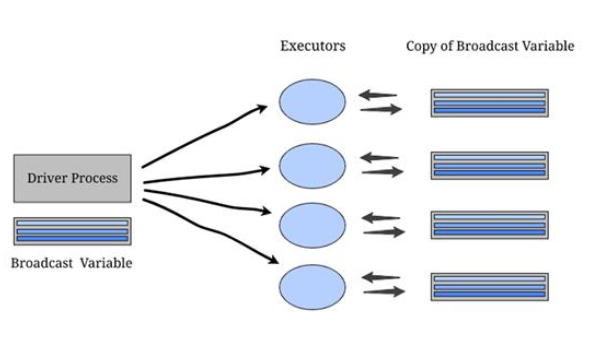
广播变量
当我们使用位置数据(例如城市名称和邮政编码的映射)时,这些是固定变量,是吧?现在,如果每次在任意集群上的特定转换都需要这种类型的数据,我们不需要向驱动程序发送请求,因为它会太昂贵。
相反,可以在每个集群上存储此数据的副本。这些类型的变量称为广播变量。
广播变量允许程序员在每台计算机上保留一个只读变量。通常,Spark使用高效的广播算法自动分配广播变量,但是如果有任务需要多个阶段的相同数据,也可以定义它们。
使用PySpark对流数据进行情感分析
是时候启动你最喜欢的IDE了!让我们在本节中进行编码,并以实践的方式理解流数据。
理解问题陈述
在本节我们将使用真实数据集。我们的目标是检测推文中的仇恨言论。为了简单起见,如果一条推文包含带有种族主义或性别歧视情绪的言论,我们就认为该推文包含仇恨言论。
因此,任务是将种族主义或性别歧视的推文从其他推文中区分出来。我们将使用包含推文和标签的训练样本,其中标签“1”表示推文是种族主义/性别歧视的,标签“0”则表示其他种类。
为什么这是一个与主题相关的项目?因为社交媒体平台以评论和状态更新的形式接收庞大的流数据。该项目将帮助我们审核公开发布的内容。
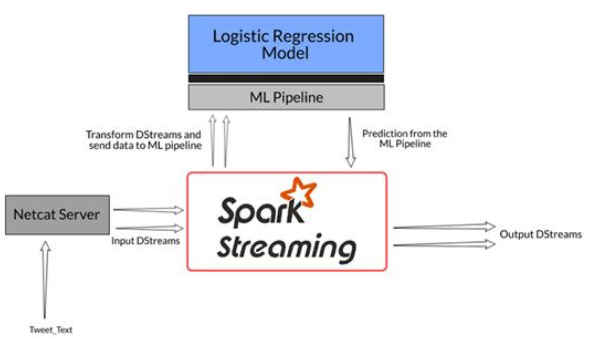
设置项目工作流程
1. 模型构建:构建逻辑回归模型管道,对推文中是否包含仇恨言论进行分类。在这里,我们的重点不是建立一个完全准确的分类模型,而是了解如何在流数据上使用任意模型并返回结果
2. 初始化Spark Streaming的环境:一旦模型构建完成,需要定义获取流数据的主机名和端口号
3. 流数据:接下来,从定义的端口添加来自netcat服务器的推文,SparkStreaming API将在指定的持续时间后接收数据
4. 预测并返回结果:一旦接收到推文,就将数据传递到创建的机器学习管道中,并从模型中返回预测的情绪
这是对工作流程的简洁说明:
训练数据以建立逻辑回归模型
我们在一个CSV文件中存储推文数据及其相应的标签。使用逻辑回归模型来预测推文是否包含仇恨言论。如果是,则模型预测标签为1(否则为0)。你可以参考“面向初学者的PySpark”来设置Spark环境。
可以在这里下载数据集和代码。
首先,需要定义CSV文件的模式。否则,Spark会将每列数据的类型都视为字符串。读取数据并检查模式是否符合定义:
# importing required libraries
from pyspark import SparkContext
from pyspark.sql.session import SparkSession
from pyspark.streaming import StreamingContext
import pyspark.sql.types as tp
from pyspark.ml import Pipeline
from pyspark.ml.feature import StringIndexer, OneHotEncoderEstimator, VectorAssembler
from pyspark.ml.feature import StopWordsRemover, Word2Vec, RegexTokenizer
from pyspark.ml.classification import LogisticRegression
from pyspark.sql import Row
# initializing spark session
sc = SparkContext(appName=“PySparkShell”)
spark = SparkSession(sc)
# define the schema
my_schema = tp.StructType([
tp.StructField(name=‘id’, dataType= tp.IntegerType(), nullable=True),
tp.StructField(name=‘label’, dataType= tp.IntegerType(), nullable=True),
tp.StructField(name=‘tweet’, dataType= tp.StringType(), nullable=True)
])
# read the dataset
my_data = spark.read.csv(‘twitter_sentiments.csv’,
schema=my_schema,
header=True)
# view the data
my_data.show(5)
# print the schema of the file
my_data.printSchema()

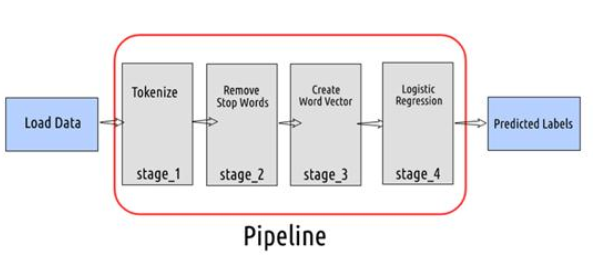
定义机器学习管道的各个阶段
现在已经将数据保存在Spark数据框中,需要定义转换数据的不同阶段,然后使用它从模型中获取预测的标签。
在第一阶段,使用RegexTokenizer将推特文本转换为单词列表。然后,从单词列表中删除停用词并创建词向量。在最后阶段,使用这些词向量来构建逻辑回归模型并获得预测的情绪。
记住——重点不是建立一个完全准确的分类模型,而是要看看如何在流数据上使用预测模型来获取结果。
# define stage 1: tokenize the tweet text
stage_1 = RegexTokenizer(inputCol=‘tweet’ , outputCol=‘tokens’, pattern=‘\\W’)
# define stage 2: remove the stop words
stage_2 = StopWordsRemover(inputCol=‘tokens’, outputCol=‘filtered_words’)
# define stage 3: create a word vector of the size 100
stage_3 = Word2Vec(inputCol=‘filtered_words’, outputCol=‘vector’, vectorSize=100)
# define stage 4: Logistic Regression Model
model = LogisticRegression(featuresCol=‘vector’, labelCol=‘label’)
设置机器学习管道
让我们在Pipeline对象中添加阶段,然后按顺序执行这些转换。用训练数据集拟合管道,现在,每当有了新的推文,只需要将其传递给管道对象并转换数据即可获取预测:
# setup the pipeline
pipeline = Pipeline(stages= [stage_1, stage_2, stage_3, model])
# fit the pipeline model with the training data
pipelineFit = pipeline.fit(my_data)
流数据和返回结果
假设每秒收到数百条评论,我们希望通过阻止用户发布仇恨言论来保持平台整洁。因此,每当我们收到新文本,都会将其传递到管道中并获得预测的情绪。
我们将定义一个函数get_prediction,该函数将删除空白句子并创建一个数据框,其中每一行都包含一条推文。
初始化Spark Streaming的环境并定义3秒的批处理持续时间。这意味着我们将对每3秒收到的数据进行预测:
# define a function to compute sentiments of the received tweets
defget_prediction(tweet_text):
try:
# filter the tweets whose length is greater than 0
tweet_text = tweet_text.filter(lambda x: len(x) 》0)
# create a dataframe with column name ‘tweet’ and each row will contain the tweet
rowRdd = tweet_text.map(lambda w: Row(tweet=w))
# create a spark dataframe
wordsDataFrame = spark.createDataFrame(rowRdd)
# transform the data using the pipeline and get the predicted sentiment
pipelineFit.transform(wordsDataFrame).select(‘tweet’,‘prediction’).show()
except :
print(‘No data’)
# initialize the streaming context
ssc = StreamingContext(sc, batchDuration=3)
# Create a DStream that will connect to hostname:port, like localhost:9991
lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2]))
# split the tweet text by a keyword ‘TWEET_APP’ so that we can identify which set of words is from a single tweet
words = lines.flatMap(lambda line : line.split(‘TWEET_APP’))
# get the predicted sentiments for the tweets received
words.foreachRDD(get_prediction)
# Start the computation
ssc.start()
# Wait for the computation to terminate
ssc.awaitTermination()
在一个终端上运行该程序,然后使用Netcat(用于将数据发送到定义的主机名和端口号的实用工具)。你可以使用以下命令启动TCP连接:
nc -lk port_number
最后,在第二个终端中键入文本,你将在另一个终端中实时获得预测。
完美!
结语
流数据在未来几年只会越来越热门,因此应该真正开始熟悉这一主题。请记住,数据科学不只是建立模型——整个流程都需要关注。
本文介绍了SparkStreaming的基础知识以及如何在真实的数据集上实现它。我鼓励大家使用另一个数据集或抓取实时数据来实现刚刚介绍的内容(你也可以尝试其他模型)。
-
数据
+关注
关注
8文章
6888浏览量
88824 -
机器学习
+关注
关注
66文章
8377浏览量
132405
发布评论请先 登录
相关推荐
海外储能市场蓬勃发展,储能配电表扮演关键角色

制造商利用云技术优化深度学习机器视觉的运行效率
LEM国产替代:芯森传感器助力中国机器人行业蓬勃发展
音圈电机无人机蓬勃发展

光伏技术蓬勃发展,安富利助力全球能源发展
多样性算力产业峰会2024成功举办,得瑞领新助力推动产业生态蓬勃发展

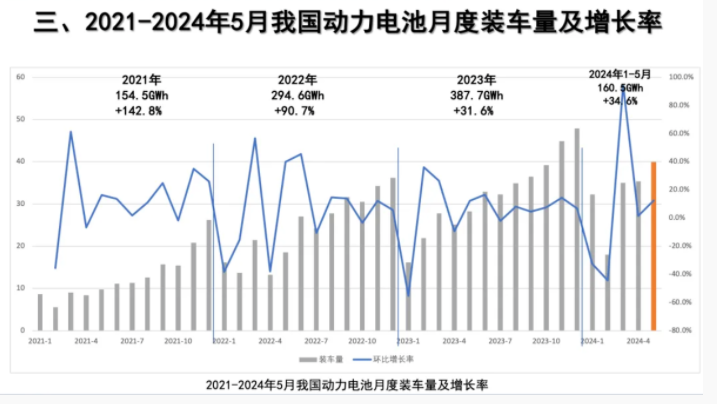
我国动力电池产业蓬勃发展,装车量持续增长
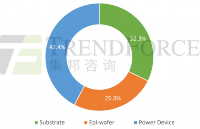
中国SiC功率半导体产业蓬勃发展
浅谈AI技术在SSD控制器中的应用
我国 IPv6 蓬勃发展,网络“高速公路”全面建成

华为云 FunctionGraph 函数工作流:打破 AIGC 部署困局,释放企业无限潜能





 工商网监
工商网监
评论