 寒武纪历代深度学习处理器的各种参数信息
寒武纪历代深度学习处理器的各种参数信息

寒武纪神经网络处理器是中科院计算技术研究所发布的能运行深度神经网络实现人工智能算法的处理器硬件架构,下面是小编整理的寒武纪历代深度学习处理器的各种参数信息,大家不妨来看看。
1. 寒武纪1号:DianNao
陈天石等人提出的DianNao是寒武纪系列的第一个原型处理器结构,包含一个处理器核,主频为0.98GHz,峰值性能达每秒4520亿次神经网络基本运算(如加法、乘法等),65mm工艺下功耗为0.485W,面积3.02平方毫米。在若干代表性神经网络上的实验结果表明,DianNao的平均性能超过主流CPU核的100倍,面积和功耗仅为CPU核的1/30~1/5,效能提升达三个数量级;DianNao的平均性能与主流通用图形处理器(NVIDIA K20M)相当,但面积和功耗仅为后者的百分之一量级。
DianNao要解决的核心问题是如何使有限的内存带宽满足运算功能部件的需求,使运算和访存之间达到平衡,从而实现高效能比。其难点在于选取运算功能部件的数量、组织策略以及片上随机存储器(RAM)的结构参数。由于整个结构参数空间有上千万种选择,而模拟器运行速度不及真实芯片的十万分之一,我们不可能蛮力尝试各种可能的设计参数。为解决此问题,提出了一套基于机器学习的处理器性能建模方法,并基于该模型最终为DianNao选定了各项设计参数,在运算和访存间实现了平衡,显著提升了执行神经网络算法时的效能。
即使数据已经从内存移到了片上,搬运的能耗依然非常高。英伟达公司首席科学家史蒂夫·凯科勒(Steve Keckler)曾经出,在40m工艺下,将64位数据搬运20毫米的能耗是做64位浮点乘法的数倍。因此,要降低处理器功耗,仅仅降低运算功耗是不够的,必须对片上数据搬运进行优化。我们提出了对神经网络进行分块处理,将不同类型的数据块存放在不同的片上随机存储器中,并建立理论模型来刻画随机存储器与随机存储器、随机存储器与运算部件、随机存储器与内存之间的搬运次数,进而优化神经网络运算所需的数据搬运次数。相对于CPU/GPU上基于缓存层次的数据搬运,DianNao可将数据搬运次数减少至前者的1/30~1/10。
2. 寒武纪2号:DaDianNao
近年来兴起的深度神经网络在模式识别领域取得了很好的应用效果,但这类神经网络的隐层数量和突触数量远多于传统神经网络。例如,著名的谷歌大脑包括了100多亿个突触。百度采用的大规模深度学习神经网络包含200多亿个突触。急剧增长的神经网络规模给神经网络处理器带来了挑战。单个核已经难以满足不断增长的应用需求。将神经网络处理器扩展至多核成为自然之选。DaDianNao在DianNao的基础上进一步扩大了处理器的规模,包含16个处理器核和更大的片上存储,并支持多处理器芯片间直接高速互连,避免了高昂的内存访问开销。在28nm工艺下,DaDianNao的主频为606MHz,面积67.7平方毫米,功耗约16W。单芯片性能超过了主流GPU的21倍,而能耗仅为主流GPU的1/330。64芯片组成的计算系统的性能较主流GPU提升450倍,但总能耗仅为后者的1/150。
3. 寒武纪3号:PuDianNao
神经网络已成为模式识别等领域的主流算法,但用户很多时候可能更倾向于使用其他一些经典的机器学习算法。例如程序化交易中经常使用线性回归这类可解释性好、复杂度低的算法。在此背景下,我们研发了寒武纪3号多用途机器学习处理器---PuDianNao,可支持k-最近邻、k-均值、朴素贝叶斯、线性回归、支持向量机、决策树、神经网络等近10种代表性机器学习算法。在65nm工艺下,PuDianNao的主频为1GHz,峰值性能达每秒10560亿次基本操作,面积3.51平方毫米,功耗为0.596W。PuDianNao运行上述机器学习算法吋的平均性能与主流通用图形处理器相当,但面积和功耗仅为后者的百分之一量级。PuDianNao的结构设计主要有两个难点:运算单元设计和存储层次设计,分别对应于机器学习的运算特征和结构特征。其中运算单元设计的出发点是高效实现机器学习最频繁的运算操作,而存储层次设计则主要根据访存特征提高各机器学习算法中数据的片内重用,降低片外访存带宽的需求,充分发挥运算单元的计算能力,避免片外访存成为性能瓶颈。在运算单元设计方面,提出了一种机器学习运算单元(Machine Learning Unit, MLU)来支持各种机器学习方法中共有的核心运算,包括:点积(线性回归、支持向量机、神经网络)、距离计算(k-最近邻、k-均值)计数(决策树和朴素贝叶斯)、排序(k-最近邻、k-均值)和非线性函数计算(支持向量机和神经网络)等。机器学习运算单元被分成了计数器、加法器、乘法器、加法树、Acc和Misc6个流水线阶段。
在存储层次设计方面,设计了HotBuf(HB)、ColdBuf(CB)和OutputBuf(OB)3个片上数据缓存HotBuf存储输入数据,具有最短重用距离的数据。ColdBuf存放相对较长重用距离的输入数据。OutputBuf存储输出数据或者临时结果。这样设计的原因有两个:第一,在各种机器学习算法中,数据的重用距离通常可以分为两类或三类,因此设计了3个片上数据缓存;第二,机器学习算法中不同类型的数据读取宽度不同,因此设置了分开的缓存来降低不同的宽度带来的开销。
-
神经网络
+关注
关注
42文章
4845浏览量
108326 -
算法
+关注
关注
23文章
4816浏览量
98744 -
寒武纪
+关注
关注
13文章
222浏览量
75097
发布评论请先 登录
寒武纪Day 0适配商汤科技日日新SenseNova U1系列大模型
业绩大爆发!寒武纪Q1财报发布,国产AI芯片的历史性拐点?
寒武纪Day 0适配DeepSeek-V4模型
寒武纪2025年报解读:AI芯片的机遇与隐忧 营收64.97亿,同比暴涨453.21%
深入剖析STA2065:高性能信息娱乐应用处理器
深度解析ADSP - TS101S TigerSHARC嵌入式处理器
寒武纪去年营收增长超400% 净利润20.59亿同比扭亏 寒武纪首个盈利年度
寒武纪实现对GLM-5的Day 0适配
寒武纪引领AI芯片软件新生态

商汤科技与寒武纪达成战略合作
寒武纪成功适配DeepSeek-V3.2-Exp模型

寒武纪股价破1200大关创历史新高 DeepSeek适配国产芯片成直接原因
寒武纪85后创始人陈天石身价超1500亿
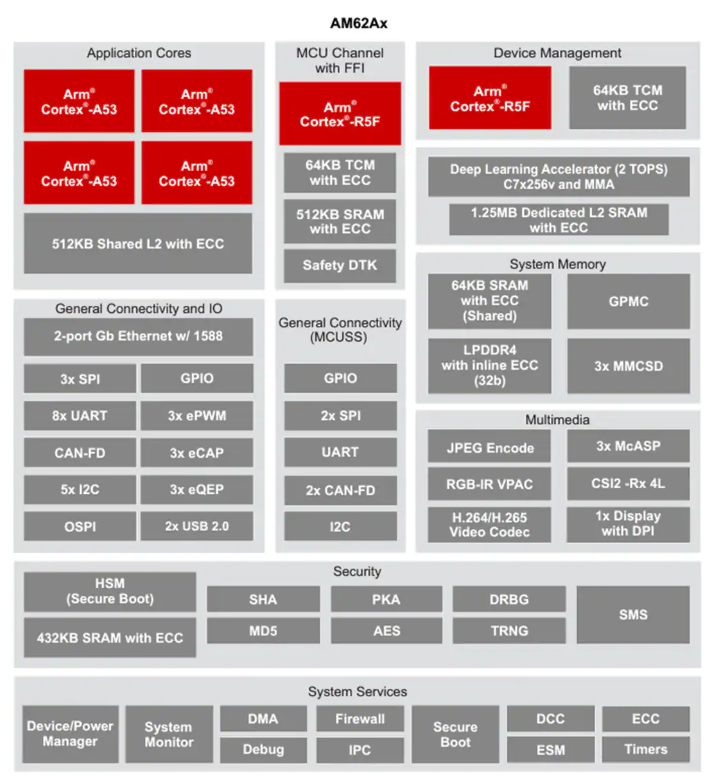
德州仪器AM62Ax Sitara™处理器技术解析



评论