 图神经网络也急需一个全球学者公认的统一对比基准
图神经网络也急需一个全球学者公认的统一对比基准
图神经网络(GNN)是当下风头无两的热门研究话题。然而,正如计算机视觉的崛起有赖于 ImageNet 的诞生,图神经网络也急需一个全球学者公认的统一对比基准。
近日,Bengio 大神带领其团队发布了新的图神经网络对比基准测试框架以及附带的 6 个标准化数据集。大家可以开始尽情刷榜了!
时至今日,图神经网络已经成为了分析图数据并且进行学习的标准工具,被成功地应用到了各个领域(例如,化学、物理、社会科学、知识图谱、推荐系统,以及神经科学)。随着这个领域的兴起,识别出在不同的网络尺寸下都可以泛化的架构和关键机制就变得至关重要了,这让我们可以处理更大、更复杂的数据集和领域。
不幸的是,在缺乏具有统一的实验设置和大型数据集的标准化对比基准的情况下,衡量新型 GNN 的有效性以及对模型进行比较的难度越来越大。
在本文中,Bengio 团队提出了一种可复现的 GNN 对比基准框架,而且为研究人员添加新数据集和模型带来了便利。他们将这个对比基准框架应用于数学建模、计算机视觉、化学和组合问题等新颖的中型图形数据集,从而在设计有效的 GNN 时创建关键操作。与此同时,还精确地将图卷积,各向异性扩散,残差连接和归一化层作为通用构建模块,用于开发鲁棒且可扩展的 GNN。
一、引言
在许多前人的工作的努力下,近年来,图神经网络(GNN)已经成为了风口浪尖上的热门研究话题,研究人员陆续开发出了一系列具有发展前景的方法。
随着该领域的不断发展,如何构建强大的 GNN 成为了核心问题。什么样的架构、基本原则或机制是通用的、可泛化的,并且能扩展到大型图数据集和大型图之上呢?另一个重要的问题是:如何研究并量化理论发展对 GNN 的影响?
对比基准测试为解决这些基本的问题给出了一个强大的范例。这种方法已经被证明在推动科学进步、确定基本思想、解决特定领域的问题等方面对于一些科学领域大有助益。
近年来,大名鼎鼎的 2012 ImageNet 挑战赛提供了一个很好的对比基准测试数据集,它掀起了深度学习的革命。来自世界各国的研究团队争相开发出用于在大规模数据集上进行图像分类的最幽默型。
由于在 ImageNet 数据集上取得的重大进展,计算机视觉研究社区已经开辟出了一条光明的发展道路,朝着发现鲁棒的网络架构和训练深度神经网络的技术迈进。
然而,设计出成功的对比基准是一件极具挑战的事情,它需要:设计合适的数据集、鲁棒的编码接口,以及为了实现公平的比较而设立的通用实验环境,所有上述元素都需要时可复现的。
这样的需求面临着一些问题:
首先,如何定义合适的数据集?想要收集到具有代表性的、真实的大规模数据集可能是很困难的。而对于 GNN 来说,这却是最重要的问题之一。大多数已发表的论文关注的都是非常小的数据集(例如,CORA 和 TU 数据集),在这种情况下,从统计及意义上说,几乎所有的 GNN 的性能都是相同的。有些与直觉相悖的是,那些没有考虑图结构的对比基线模型性能与 GNN 相当,甚至还有时要优于 GNN。
这就对人们研发新的、更复杂的 GNN 架构的必要性提出了疑问,甚至对使用 GNN 的必要性也提出了疑问。例如,在 Hoang&Maehara 等人以及 Chen 等人于 2019 年发表的工作中,作者分析了 GNN 中的组件的能力,从而揭示了模型在小数据集上收到的限制。他们认为这些数据集不适合设计复杂的结构化归纳学习框架。
GNN 领域面临的另一个主要问题是如何定义通用的实验环境。正如 Errica 等人于 2019 年发表的论文《A fair comparison of graph neural networks for graph classifification》所述,最近基于 TU 数据集完成的论文在训练、验证和测试集的划分以及评估协议方面没有达成共识,这使得比较新思想和架构的性能变得不公平。
人们目前尚不明确如何进行良好的数据集划分(除了随机划分之外),已经证明这样会得到过于乐观的预测结果(Lohr,2009)。此外,不同的超参数、损失函数和学习率计划(learning rate schedules)使得评价架构的新进展变得困难。
本文主要的贡献如下:
发布了一个公开的 GNN 对比基准框架,它是基于 PyTorch 和 DGL 库开发的,并将其托管于 GitHub 上。
目标:超越目前流行的小型数据库 CORA 和 TU,引入了 12,000~70,000 张具有 9~500 个节点的图组成的中型数据集。数据集涉及数学建模(随机分块模型)、计算机视觉(超像素),组合优化(旅行商问题)以及化学(分子溶解度)
提出的对比基准框架确定了 GNN 的重要构建模块。图卷积、各向异性扩散、残差连接,以及归一化层等技术对于设计高效的 GNN 是最有用的。
作者目的并不是对已发布的 GNN 进行排名。对于一个特定的任务来说,找到最佳的模型的计算开销是非常高昂的(超出了相应资源限制),它需要使用较差验证对超参数的值进行穷举搜索。相反,作者为所有的模型设定了一个参数变化的实验计划,并且分析了性能的趋势,从而确定重要的 GNN 机制。
数值化的结果是可以完全被复现的。
二、对比基准框架
这项工作的目的之一就是给出一系列易于使用的中型数据集,在这些数据集上,过去几年提出的各种 GNN 架构在性能方面表现出明显且具有统计意义的差异。如表 1 所示,本文给出了 6 个数据集。对于其中的两个计算机视觉数据集,作者将经典的 MNIST 和 CIFAR10 数据集中的每张图片使用「super-pixel」技术转换为图的形式(详见原文第 5.2 节)。接下来的任务就是对这些图进行分类。
表1:已提出的基准数据集统计表

「PATTERN」和「CLUSTER」数据集是根据随机分块模型生成的(详见原文第 5.4 节)。对于 PATTERN 数据集,对应的任务是识别出预先定义好的子图;对于 CLUSTER 数据集,对应的任务是识别出簇。上述两个任务都是节点分类任务。
TSP 数据集是基于旅行商问题(给定一组城市,求访问每个城市并回到原点的可能的最短路径)构建的,详见原文第 5.5 节。作者将随机欧几里得图上的 TSP 作为一个边的分类/连接预测任务来处理,其中每条边的真实值都是由 Concorde 求解器给出的 TSP 路径确定的。
如原文第 5.3 节所述,ZINC 是一个已经存在的真实世界中的分子数据集。每个分子可以被转换成图的形式:每个原子作为一个节点,每个化学键作为一条边。这里对应的任务是对一种被称为受限溶解度(Constrained Solubility)的分子特性进行回归。
本文提出的每一个数据集都至少包含 12,000 个图。这与 CORA 和经常使用的 TU 数据集形成了鲜明的对比,这些之前的数据集往往只包含几百个图。
另一方面,本文提出的数据集大多数都是人造或半人造的(除了 ZINC 之外),而 CORA 和 TU 却并非如此。因此,可以认为这些对比基准是互为补充的。
这项工作的主要动机在于,提出足够大的数据集,从而使观察到的不同 GNN 架构之间的差异是具有统计意义的。
三、图神经网络简介
从最简单的形式上来说,图神经网络根据以下公式迭代式地从一层到另一层更新其中的节点表征:
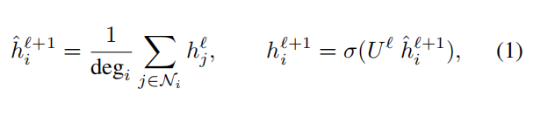
其中
是节点 i 在第 l+1 层中的 d 维嵌入表征,
是图中与节点 i 相连的节点集合,
则是节点 i 的度,σ 是一个非线性函数,
则是一个可学习的参数。我们将这个简单版本的图神经网络称为图卷积网络(GCN)。
GraphSage 和 GIN(图同构网络)提出了这种平均机制的简单变体。在采用平均聚合版本的 GraphSage 中,公式(1)可以被改写为:
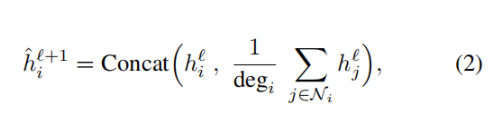
在嵌入向量被传给下一层之前,它会被投影到单位球之上。在 GIN 架构中,公式(1)可以被改写为:

其中
是可学习的参数,BN 是批归一化层。值得注意的是,为了最终的预测,GIN 在所有中间层都会使用特征。在上述所有的模型中,每个邻居对中央节点更新的贡献是均等的。我们将这种模型称为各向同性的,它们将所有的边的方向等同视之。
另一方面,高斯混合模型网络 MoNet,门控图卷积网络 GatedGCN,以及图注意力网络 GAT 提出了各向异性的更新方案:
其中,权重
和
是使用各种各样的机制计算得到的(例如,GAT 中的注意力机制或 GatedGCN 中的门控机制)。
最后,还可以考虑一个层次化的图神经网络,即差分池化 DiffPool。它在层次的每一个阶段以及池化的过程中都用到了 GraphSage 的公式(2)。
四、基准测试实验
在这里,我们来展示一下这篇文章所提出的开源对比基准测试框架的实验结果。
这篇工作中使用的大多数 GNN 网络(包括图卷积网络 GCN、图注意力网络 GAT、GraphSage、差分池化 DiffPool、图同构网络 GIN、高斯混合模型网络 MoNet),都来源于深度图代码库(DGL),并且使用 PyTorch 实现。作者使用残差链接、批归一化,以及图尺寸归一化对所有 DGL 版的 GNN 实现进行了改进。门控图卷积网络 GatedGCN 是其最终考虑使用的 GNN,并用「GatedGCN-E」代表使用了边属性/边特征的版本。
此外,作者还实现了一个简单的与具体图无关的对比基线,它以相同的方式将一个多层感知机应用于每个节点的特征向量,而与其它的节点无关。可以选择在后面接上一个门控机制,从而得到门控的多层感知机对比基线。
这篇文章中使用了英伟达 1080Ti 的 GPU,在 TU、MNIST、CIFAR10、ZINC 以及 TSP 数据集上进行了实验,并且使用英伟达 2080Ti 的 GPU 在 PATTERN 和 CLUSTER 数据集上进行了实验。
1、在 TU 数据集上进行图分类
第一个实验是在 TU 数据集上进行图分类。论文中选用了 3 个 TU 数据集,ENZYMES(训练集、验证集、测试集分别包含 480、60、60 个尺寸为 2-126 的图),DD(训练集、验证集、测试集分别包含 941、118、119 个尺寸为 30-5748 的图),以及 PROTEINS(训练集、验证集、测试集分别包含 889、112、112 个尺寸为 4-620 的图)。
实验的数值结果如表 2 所示,从统计意义上说,所有的神经网络都具有差不多的性能,然而标准差却非常大。
表 2:在标准 TU 测试数据集上的模型性能(数值越高越好)。给出了两次实验的结果,这两次实验所使用的超参数是相同的,但是使用的随机种子是不同的。作者分别展示了这两次实验的结果,从而说明排序和可复现性的差异。性能最好的结果用加粗的红色表示,性能第二的结果用加粗的蓝色表示,性能第三的结果用加粗的黑色表示。

2、使用超像素(SuperPixel) 的图分类
在第二个实验中,作者用到了计算机视觉领域流行的 MNIST 和 CIFAR10 图像分类数据集。他们使用 SuperPixel 将原始的 MNIST 和 CIFAR10 图像转换为图。
在 MNIST 数据集中,训练集、验证集、测试集分别包含 55,000、5,000、10,000 个尺寸为 40-75 个节点(即 SuperPixel 的数量)的图;在 CIFAR10 数据集中,训练集、验证集、测试集分别包含 45,000、5,000、10,000 个尺寸为 85-150 个节点的图。
对于每一个样本,作者构建了一个 k 最近邻邻接矩阵,权值
,其中 x_i,x_j 是超像素 i,j 的二维坐标,σ_x 是放缩参数(通过计算每个节点的 k 个最近邻的平均距离 x_k 得到)。MNIST 和 CIFAR10 的超像素图的可视化结果如图 1 所示。

图 1:示例图及其超像素图。通过 SLIC 得到的超像素图(MNIST 最多有 75 个节点,CIFAR10 中最多有 150 个节点)是欧氏空间中得到的 8-最近邻图,图中节点的颜色表示平均的像素强度。
在 MNIST 和 CIFAR 10 数据集上的图分类结果如表 3 所示。
表 3:在标准的 MNIST 和 CIFAR10 测试数据集上的模型性能(数值越高越好)。实验结果是根据四次使用不同的种子进行的实验求平均得到的。红色代表最优的模型,紫色代表较优模型,加粗黑色代表具有残差连接和不具有残差连接的模型之中的最优模型(如果二者性能相同,则都是加粗黑色字体)。

3、在分子数据集上进行图回归
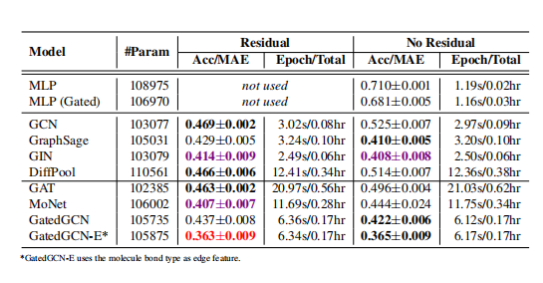
作者将 ZINC 分子图数据集用于对被称为「受限溶解度」(constrained solubility)的分子性质进行回归。在 ZINC 数据集中,训练集、验证集、测试集分别包含 10,000、1,000、1,000 个尺寸为 9-37 个节点/原子。对于每个分子图来说,节点特征是原子的种类,边的特征是边的种类。实验结果如表 4 所示。
表 4:在标准的 ZINC 测试数据集上的模型性能(数值越低越好)。实验结果是根据四次使用不同的种子进行的实验求平均得到的。红色代表最优的模型,紫色代表较优模型,加粗黑色代表具有残差连接和不具有残差连接的模型之中的最优模型(如果二者性能相同,则都是加粗黑色字体)。
4、在随机分块模型(SBM)数据集上进行节点分类
在这里,作者考虑节点级的图模式识别任务,以及半监督图聚类任务。图模式识别任务旨在找出一种嵌入在各种尺寸的大型图 G 中的固定图模式 P。对于 GNN 来说,识别出不同的图中的模式是最基本的任务之一。模式和嵌入后的图是通过随机分块模型(SBM)生成的。SBM 是一种随机图,它为每个节点按照以下的规则分配所属社区:对于任意两个节点来说,如果它们从属于同一个社区则它们被连接在一起的概率为 p,如果它们从属于不同的社区则它们被连接在一起的概率为 q(q 的值作为噪声水平)。
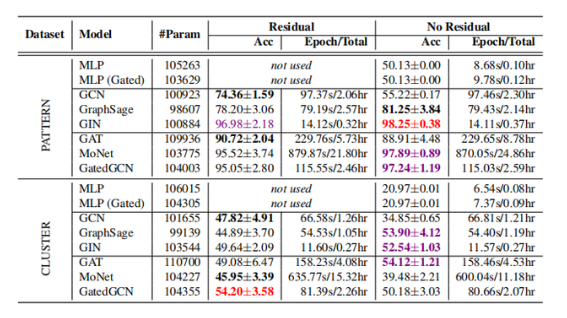
在所有的实验中,作者生成了包含 5 个社区的图 G,每个社区的规模在 [5, 35] 之间随机生成。每个社区的 SBM 规则为 p = 0.5,q = 0.2,G 上的信号是通过在 3 个变量(即{0,1,2})的均匀随机分布上采样得到的。作者随机生成了由 20 个节点组成的 100 个模式 P,内部概率为 p_P = 0.5,且外部概率 q_P = 0.5(即 P 中 50% 的节点与 G 中非 P 部分相连)。P 上的信号也是在{0,1,2}中生成的随机信号。在 PATTERN 数据集中,训练集、验证集、测试集分别包括 10,000、2,000、2,000 个尺寸为 50-180 个节点的图。当节点从属于 P 时输出信号的值为 1,节点在 G 中且不从属于 P 时输出信号的值为 0。
半监督聚类任务是网络科学中的另一类基本任务。作者生成了 6 个 SBM 簇,其尺寸为 [5, 35] 之间随机生成的值,概率 p = 0.55,q = 0.25。在 CLUSTER 数据集中,训练集、验证集、测试集分别包括 10,000、1,000、1,000 个尺寸为 40-190 个节点的图。作者仅仅为每个社区给出了随机选取的单一标签。输出信号被定义为聚类类别的标签。
表 5:在标准的 PATTERN 和 CLUSTER SBM 图测试集上的模型性能(数值越高越好)。红色代表最优的模型,紫色代表较优模型,加粗黑色代表具有残差连接和不具有残差连接的模型之中的最优模型。
5、在 TSP 数据集上进行边的分类
近年来,将机器学习用于求解 NP-hard 的组合优化问题(COP)成为了备受关注的研究热点。最近提出的 COP 深度学习求解器将 GNN 与经典的图搜索方法结合了起来,用于直接根据问题实例(表征为图)预测近似解。在这里,作者考虑被广泛研究的旅行商问题(TSP):给定一个二维的欧氏图,我们需要找到一个最优的节点顺序(路径),遍历所有节点一次,并且边的权重之和(路径长度)最小。TSP 的多尺度特性使其成为了一个极具挑战的图任务,它要求我们同时做到局部节点邻居和全局图结构的推理。
在这里的 TSP 实验中,作者遵循了 Li 等人于 2018 年发表的论文「Combinatorial optimization
with graph convolutional networks and guided tree search」中所描述的基于学习的 COP 求解方法,其中 GNN 是为每条边赋予属于/部署于某个预测解集的概率的主干架构。接着,作者会通过图搜索技术将概率转换为离散决策。训练集、验证集、测试集分别包含 10,000、1,000、1,000 个 TSP 实例,其中每个实例都是一个在单位正方形
中均匀采样得到的 n 个节点位置组成的图(
)。作者通过为每个实例均匀地采样得到 n 个节点(
),从而生成尺寸和复杂度不一的多个 TSP 问题。
为了将主干 GNN 架构和搜索部分的影响独立开来,作者将 TSP 作为了一个边的二分类任务,TSP 路径中每条边的真实值是由 Concorde 求解器得到的。为了拓展到大的实例上,作者使用了稀疏的 k = 25 的最近邻图,而并非使用完全图。采样得到的各种各样尺寸的 TSP 实例请参阅图 2。

图 2:TSP 数据集中采样得到的图。节点用蓝色表示,TSP 路径中的真实边用红色表示。
五、给我们的启示
1、在小型数据集上,与图无关的神经网络(多层感知机)的性能与 GNN 相近
表 2 和表 3 说明对于小型的 TU 数据集和简单的 MNIST 数据集来说,将 GNN 用在与图无关的 MLP 对比基线上没有明显的性能提升。此外,MLP 有时比 GNN 的性能还要好(例如在 DD数据集上)。
2、在大型数据集上,GNN 可以提升与图无关的神经网络性能
表 4 和表 5 显示出,在 ZINC、PATTERN 以及 CLUSTER 数据集上,所有的 GNN 都相较于两个 MLP 对比基线模型有很大的性能提升。表 6 说明使用了残差连接的 GNN 模型在 TSP 数据集上的性能要优于 MLP 对比基线。表 3 中的实验结果说明,在 CIFAR10 数据集上差异较小,尽管最佳的 GNN 模型性能显著优于 MLP 模型。
3、原始的 GCN 性能较差
GCN 是最简单的 GNN 形式。它们对节点表征的更新依赖于一个如公式(1)所述的在邻居节点上的各向同性平均操作。Chen 等人于 2019 年发表的论文《Are Powerful Graph Neural Nets Necessary? A Dissection on Graph Classification》中对这种各向同性的性质进行了分析,结果表明这种方法无法区分简单的图结构,这也解释了 GCN 在所有的数据集上为什么性能较差。
4、在 GCN 上进行改进的新型各向同性 GNN 架构
GraphSage 通过图卷积层的公式(2)说明了使用中心节点信息的重要性。GIN 也在公式(3)中利用了中心节点的特征,并采用了一个与所有中间层的卷积特征相连的新的分类器层。DiffPool 考虑了一种可学习的图池化操作,其中在每一个分辨率的层级上使用了 GraphSage。这三种各向同性的 GNN 在除了 CLUSTER 的所有数据集上都极大提升了 GCN 的性能。
5、各向异性 GNN 更加精确
诸如 GAT、MoNet、GatedGCN 等各向异性模型在除了 PATTERN 之外的所有数据集上都取得了最佳的性能。同时,作者也注意到 GatedGCN 在所有的数据集上都展现出了很好的性能。
与主要依赖于对邻居节点特征的简单求和的各向同性 GNN 不同,各向异性 GNN 采用了复杂的机制(GAT 用到了稀疏注意力机制,GatedGCN 用到了边的门控机制),这使得它们更难得以高效地实现。
此外,这种 GNN 还有一个优点,那就是它们可以显式地使用边的特征(例如,分子中两个原子之间的化学键类型)如表 4 所示,对于 ZINC 分子数据集而言,GatedGCN-E 使用化学键的边特征,相较于不使用化学键的 GatedGCN 极大地提升了 MAE 性能。
6、残差连接可以提升性能
残差连接在计算机视觉领域的深度学习架构中已经成为了一种通用的组成部分。使用残差连接可以从两方面帮助 GNN 提升性能:
一方面,它在深度网络中限制了反向传播过程中的梯度弥散的问题。另一方面,它使得在 GCN 和 GAT 这样的模型中可以在卷积阶段包含自节点信息,而这些模型本身并没有显式地使用这些信息。
表 7:对于带有残差连接/不带有残差连接的深度 GNN(最多 32 层),在 TSP 测试数据集上的模型性能(数值越高越好)。L 代表层数,加粗的黑色字体代表带有残差连接和不带有残差连接的模型中最优的一方(如果性能相同则都是加粗的黑色字体)。

图 3:带有残差连接(实线)和不带有残差连接(虚线)的深度 GNN(最多 32 层)在 ZINC 和 CLUSTER 测试数据集上的模型性能。实验结果是根据四次使用不同的种子进行的实验求平均得到的。
7、归一化层可以提升学习性能
大多数现实世界中的图数据集是具有不同图大小的不规则图的集合。将大小不同的图当做一批处理,可能会导致节点表征处于不同的尺度。因此,对激活值进行归一化处理可能会有助于提升学习和泛化的性能。
在试验中,作者使用了两个归一化层:批量归一化(BN)以及图尺寸归一化(GN)。图尺寸归一化是一种简单的操作,其产生的节点特征 h_i 是根据图的尺寸进行归一化之后的结果,即
,其中 V 是节点的个数。这种归一化层被应用在卷积层之后、激活层之前。

表 8:有/没有经过批量归一化(BN)和图归一化(GN)的模型在 ZINC、CIFAR10、CLUSTER 测试数据集上的性能。
实验结果是根据四次使用不同的种子进行的实验求平均得到的,表示为(均值±标准差),对于 ZINC 数据集来说数值越低越好,对于 CIFAR10 和 CLUSTER 数据集来说数值越高越好。加粗的黑色字体代表使用和不使用归一化层的模型之中最优的一方(当二者性能相同时则都为加粗黑色字体)。
六、结语
在本文中,Begio等人提出了一种促进图神经网络研究的对比基准测试框架,并解决了实验中的不一致性问题。他们证明了被广为使用的小型 TU 数据集对于检验该领域的创新性是不合适的,并介绍了框架内的 6 个中型数据集。
在多个针对图的任务上进行的实验表明:
1)当我们使用更大的数据集时,图结构是很重要的;
2)作为最简单的各向同性 GNN,图卷积网络 GCN 并不能学习到复杂的图结构;
3)自节点信息、层次、注意力机制、边门控以及更好的读取函数(Readout Function)是改进 GCN 的关键;
4)GNN 可以使用残差连接被扩展地更深,模型性能也可以使用归一化层得到提升。
-
神经网络
+关注
关注
42文章
4762浏览量
100534 -
GNN
+关注
关注
1文章
31浏览量
6328
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论