 大数据时代,冯·诺依曼架构捉襟见肘
大数据时代,冯·诺依曼架构捉襟见肘
大数据让传统计算机架构捉襟见肘,真实忆阻器的发现改变了这一局面。其元件特性适合模拟神经元突触的部分运作,使得电脑神经网络制作上更能接近人脑。目前,一些科技巨头、创业和研究机构已在探索利用忆阻器强化计算机学习能力甚至取代普通晶体管计算机的路径。
我们可以谈论人工智能掌握一些人类本领,比如开车或者玩扑克。但是,当需要让海量、无序信息变得有意义时,人类还无法打造一个哪怕是接近大脑的 AI。部分原因在于大脑未解之谜,以及已有半世纪历史的计算机架构,制约了这一目标的实现。
如今,一种新的计算范式为突破瓶颈带来曙光。这种激进方案使用了一种同时存储、处理信息的硬件,与大脑神经元网络的差别不是很大。充分发挥这一新范式的潜力,我们就能创造出可以实时分析数据流、识别模式,或许还能独立自学的机器心智(mind)。
大数据时代,冯·诺依曼架构捉襟见肘
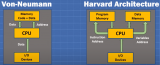
笔记本,智能手机,平板电脑,只要你说上来的,几乎都遵循着冯·诺依曼结构。70 多年前,他主张计算机处理器与存储单元应该彼此独立。听起来不像是什么伟大的提议,但这意味着每运行一个新程序,没必要再重新连接计算机。这种劳动分工的设计很凑效,人类制造出更快的计算机,办法就是串联处理器与内存。
但是,这一架构也有短处。
处理器需要数据信息,必须先从存储单元读取。这就要求电子在两个元件之间穿梭,因此,处理器经常觉得很无聊,因为要等数据。你的笔记本为什么会有「多核」,这就是其中一个原因;多个处理器单元——每一个都与内存连接——意味着,它们可以同时请求数据,从整体上加快计算。
如今,这一局限性真的开始妨碍到人类进步。
数据比以往任何时候都要多,特别是「大数据」革命正在临近。我们已经可以瞥见未来的样子:预测心脏病,数据预测分析比传统医学方法更快、更准。英国诺丁汉大学研究人员设计了一种算法,可以处理近 400,000 病人的电子病历,多么庞大的数据分析任务。随着物联网范围延伸到我们身边的日常事物,从交通灯到冰箱,机器会为我们提供更多的生活洞见。
应用得当,前景无限。然而,如此庞大的数据量已经让计算机过热。美国能源部的一份报告显示,世界 5% 到 15% 的能源都被用于计算,许多浪费在了数据的传输中。这正是我们需要突破冯·诺依曼瓶颈的原因。
人们为此进行了许多尝试。上世纪 80 年代,科学家开始考虑利用光子而不是电子来编译信息。因为光子在光纤中的传播速度更快,所需传播时间更少。其他人想要坚持使用电子,不过希望将电子编码进量子力学特性(自旋)中,让电子携带更多信息。但是,到目前为止,这些办法都没有很大进展,主要原因在于实施起来很复杂,以至于投入产出不成比例。
总而言之,多年来,这个问题一直挑战着人类智慧,之所以很讽刺,是因为大脑本身就是一台超级计算机,但所需能耗与一只 20 瓦的电灯泡差不多。它们不会存在类似冯·诺依曼结构的瓶颈,因为同一个神经网络既可以存储信息还可以处理信息。
大脑三大关键特征与传统模拟方法的弊病
那么,如何模拟人类神经网络呢?这也是麻烦所在。我们不可能完全知晓大脑如何工作,不过,至少要模拟大脑的三个关键特征。
首先,大脑由大量的神经元以及神经元之间的突触组成。其次,这些连接具有突触弹性,也就是说它们可强可弱。学习,其实就是强化某组神经元之间连接。
第三个特征,脉冲时间相关的突触可塑性 (spike-time-dependent plasticity)。相对前两个特征,这个特征没有得到很好的理解。该特征表明,如果两个神经元几乎同时放电,那么,神经元就会被加强;如果放电不同步,就会变弱。经过这一漫长过程,协同工作的神经元的关系会得到加强,以传递信息,不重要的联系会被削弱。这就是大脑独立学习的重要手段。绿灯时,你会立刻反应到「可以走了」,因为经过多年训练,相关神经元之间的联系得到了强化。
事实上,长期以来,我们一直在试图模仿大脑计算方式。这个研究领域被称之为神经形态计算,如今已取得一些进步。
最早突破之一,来自研究人员 Frank Rosenblatt。1958 年,他将研究成果 Mark 1 感知机公布于众。Rosenblatt 对着机器的摄像头展示了圆圈或三角型卡片,让机器进行识别,他来修正错误。50 次尝试之内,机器已经学会输入代表圆圈或者三角的信号。
不过,当时的电子工程技术限制了感知机的发展。但是,情况已今非昔比。谷歌的 DeepMind 神经网络的成绩令人惊呼,比如去年 AlphaGo 战胜顶尖人类围棋手。
TMark 1 感知机
然而,DeepMind 神经网络完全是软件层面的模拟,在标准硅电子元件上运行。所以,尽管和神经元网络学习方式类似,但并未突破冯·诺依曼结构瓶颈。
2014 年问世的 IBM TrueNorth 芯片走的更远。该芯片有 55 亿个硅晶体管,按照人脑 100 万个「神经元」的结构进行排列。有了这枚芯片,手机可以实时识别视频物体,比如汽车还是自行车,但是所需电量很少,仅为手机睡眠模式所需量。听起来很赞,但是,如果将规模扩展到大脑神经元级别,其能耗将是人脑能耗的 1 万倍。「这个办法实际上是一种浪费。」瑞士苏黎世大学神经形态工程师 Giacomo Indiveri 说。
简言之,尽管想方设法模仿大脑某些特征,但是,我们从来未曾实现将这三大特征集中在一个物理系统上。比如,TrueNorth 芯片拥有许多高度连接的「神经元」,但是,如果不借助软件,根本无法调节连接强度。
忆阻器,机器独立学习的未来
失败要归结于这样一个事实:传统电子产品还没能力真去模拟神经突触。但现在,我们有办法了,这要感谢半个世纪前的思想。
1971 年,加州大学伯克利分校的电子工程师 Leon Chua 正在看一道连接基本电路元件的方程式,这些元件包括电阻、电容和电感。他突然注意到,可以用另外一种方式安排这些术语,结果得到一个关于第四个元件的方程式,这第四个元件的抗阻性会根据电流情况发生变化。Chua 将之称为「忆阻器」,因为它的阻抗性似乎展示出一种记忆能力。但当时并没有以这种原理工作的材料或者设备,人们几乎忘记了这个发现。
约十年前,惠普公司的一个由 Stan Williams 带领的团队正在研究一种新型内存,与台式电脑不同,在关掉电源后,新内存仍然保留数据。研究人员研究着使用了极薄钛膜的设备,他们发现其阻抗性会随着经过电流而发生奇怪的变化。最终,他们意识到薄膜中活动的不仅仅是电子,也有原子,它们以微妙的方式反转变化了材料结构及其抗阻性。易言之,这个团队无意间创造出 Chua 忆阻器。
Williams 的研究有助于解释以前为什么从未发现过忆阻性;因为只能在微观尺度上自证存在。如今,人们相继发现一系列可充当忆阻器的物质,包括一些聚合物。
真实忆阻器的出现鼓舞了研究人员,原因有几个,比如有可能开发出新的计算方式,其技术更成熟、所用语言也比现在的更有效。
但不久后,有人动真格了。
紧跟 Williams 的发现,密歇根大学的工程师 Wei Lu 迈出关键一步。他向人们展现了这一事实:忆阻器可充当具有弹性的突触。他拿出了一个由几层薄硅打造的设备(其中一层带有少量银离子),它可以模拟上述大脑的第二个特征。后来,Lu 展示忆阻器也可以模拟大脑的第三个特征;应用电脉冲确切时点不同(exact timing of applied electrical spikes),忆阻器做成的突触也会有强弱变化。
这项研究表明,「对于神经形态工程学来说,这真是激动人心的时刻,」Indiveri 说。「目前应该放弃硅晶体管,」荷兰格罗宁根大学物理学家 Beatriz Noheda 说,聚焦研发成熟的、使用忆阻器的神经网络。
看起来,这只是扩展 Lu 研究成果的一个简单案例。尽管他的研究只有一个单独的突触(带有一个输入和输出神经元),但是,结果已经表明忆阻器可以实现三大重要大脑功能。接下来的研究会考虑搭建多层忆阻器神经元网络;每增加一层,网络就能进行更加复杂的「思考」。
没那么快,位于加州的 IBM Almaden 研究实验室的 Geoffrey Burr 说。他说,Lu 所证实的脉冲时间依存的可塑性,只是在小规模上可行,但是,神经科学家并不确定在人脑大规模学习上表现如何。「在某种程度上,肯定会发生,」他说,「但是,我们还搞不清状况。」也就是说,部署在大型人工神经网络,并不意味着可以带来近似大脑的计算能力。
Burr 更喜欢坚持没有脉冲时间依存的可塑性的网络。他使用的一个网络类似驱动 DeepMind 的神经网络,软件控制着弹性突触。但是,通过在忆阻器上运行这些网络(而不是晶体管),他能够节省很多能源。
2014 年,Burr 搭建了一个这样的网络,用了差不多 165000 个突触。经过手写书信数据集训练后,该网络能够准确识别这些手写书信。Burr 的忆阻器由一种硫系玻璃(a chalcogenide glass)制成,这种材料能够在原子有序或无序的两相之间来回切换,改变材料导性。这种相变忆阻器正变得越来越可靠,芯片制造商们,比如英特尔开始出售使用忆阻器的内存设备。
其他人认为,忆阻器可以帮助实现完全独立学习的机器。
英国南安普顿大学纳米电子学研究人员 Themis Prodromakis 就是其中一员。去年,他搭建了一个神经网络,有四个输入,两个输出神经元,用忆阻器突触将它们连接起来。他可以输入电子信号,比如「1001」或「0110」,这与 20 世纪 50 年代向感知机展示圆圈或三角形类似。不过,感知机需要人类告诉机器有没有猜对图形形状,但 Prodromakis 的网络完全自学,看到 1001 就发送(fire off)一个输出神经元,看到 0110 就发送另外一个。即使是带有噪音的信号输入,它也能正常运行。鉴于真实生活数据充满噪音,这是一个非常重要的优势。
最后,我们似乎正利用忆阻器重新创造大脑真实状态(比如,当你望向窗外时)的精华部分:不存在瓶颈的独立学习。
适当加以扩展,这类自我学习系统就能实时筛查数据,比如,监测自动驾驶汽车行为、桥梁完整性或者核电站,对庞大数据存储中心(比如,为社交网络存储数据的中心)的需求也会减少。由于需要冷却,这些中心有时会建在北极附近。但是,如果忆阻器网络能够实时解析数据,那么,可能就不需要存储数据。
由忆阻器制成的电脑还有一个潜在的优势:因为运行原理类似大脑,因此,与人类连接或许会更容易些。现在已有一些使用硅芯片的设备,它们可以获取大脑运动进而将其转交给现实世界的东西,比如,瘫痪人控制体外骨骼,或者在睡梦中控制电脑。
但是,挑战依然不少。大脑神经元行为极为复杂,现有的神经接口很难处理所有那样的信息。「要电子元件处理如此丰富、高宽带的数据,会让它不堪重负。」Prodromakis 说道。忆阻器,是一个完美解决方案,因为它们只记录表现脉冲显著的信号,忽略嘈杂的背景。这让 Prodromakis 兴奋不已,最近,他开始与 Galvani Bioelectronics 合作研发基于忆阻器的神经接口。Galvani Bioelectronics,一家去年成立的英国公司,源自 GlaxoSmithKline 和谷歌子公司一个 5.4 亿英镑合作项目。
困扰忆阻器网络的最大问题之一,是能否高效量产。运行良好的工厂可量产硅芯片,但也同样适用于忆阻器吗?
想找到答案,首先需要挑选最佳制造原料。Noheda 已在 Groningen 建立了一个研究中心从事这方面的研究。如果她和其他忆阻器先驱们获得成功,那么,未来计算机可能会由那些四十年来、我们一度认为不存在的材料打造而成。
-
神经网络
+关注
关注
42文章
4762浏览量
100535 -
机器
+关注
关注
0文章
779浏览量
40687 -
神经元
+关注
关注
1文章
363浏览量
18438
发布评论请先 登录
相关推荐
AI时代的存储墙,哪种存算方案才能打破?
智芯科AI算力芯片的应用场景
【「大模型时代的基础架构」阅读体验】+ 未知领域的感受
高效能计算机公司立誓一年构建全新技术栈,以全新架构改变计算方式
高性能计算的原理与实践:从基本概念到架构解析

嵌入式微处理器体系结构 嵌入式微处理器原理与应用

FPGA、ASIC、GPU谁是最合适的AI芯片?

冯诺依曼和哈佛架构有哪些异同点呢?
mcu的分类方式有哪些?





 工商网监
工商网监
评论