 深度学习又是从哪个层面深刻影响了NLP呢?
深度学习又是从哪个层面深刻影响了NLP呢?
深度学习正在给自然语言处理带来巨大的变革。但是,作为一个初学者,要从哪里起步才好呢?深度学习和自然语言处理都是很宽泛的领域。哪些方面才是最重要的,还有,深度学习又是从哪个层面深刻影响了 NLP 呢?
1. 关于这篇论文
这篇论文的标题是「基于神经网络模型的自然语言处理入门」(A Primer on Neural Network Models for Natural Language Processing)。
对应的论文 2015 年发表在 ArXiv 上。与其说是论文,不如说是一篇技术报告或者说是教程,面向研究员和学生,对基于深度学习方法的自然语言处理(NLP)作了综合性的介绍。
这篇教程审视了针对自然语言处理的研究的几个深度学习模型,以求自然语言的研究能加快神经网络技术的发展。
入门教程由曾是 Google Research 科学家和 NLP 研究员的 Yoav Goldberg (https://www.cs.bgu.ac.il/~yoavg/uni/) 编写。这是一篇技术报告,有大约 62 页以及 13 页的参考文献。
这对于初学者来说是很理想的教材,因为:
它对读者的基础要求不高,不需要对先了解机器学习和语言处理的相关知识;
涉及领域宽泛,包括了很多深度学习方法和自然语言处理的问题。
在这篇教程中,我希望能为 NLP 开发者和新手介绍一些基础背景知识,术语,实用工具以及方法论,从而明白其背后的神经网络模型的理论,应用到他们自己的工作中。.. 面向的是那些有志于利用已有的,有价值的技术,并创造新方法去解决他们最感兴趣的 NLP 的人。
通常情况下,在语言学和自然语言处理中,关键的深度学习方法需要翻模(重命名)以建立有用的沟通桥梁。
最后,这篇 2015 年的入门教程在 2017 年出书了,书名为「Neural Network Methods for Natural Language Processing (http://amzn.to/2tXn2dZ)」。
2. 神经网络结构
这一小节将介绍神经网络结构的不同类型,作为后面章节的参照。
全连接前馈神经网络是非线性学习器,因此在极大程度上可以随意取代线性学习器。
这里介绍 4 种类型的神经网络结构,这里着重介绍其应用案例和参考文献:
全连接前馈神经网络,例如多层感知网络;
带有卷积和池化层的网络,例如卷积神经网络;
循环神经网络,例如长短时记忆网络;
递归神经网络。
如果你只对应用感兴趣,以上内容将为你提供直接寻找更多资源的线索。
3. 特征表示
这一节着重介绍深度学习模型训练稀疏或者密集型表示的各种方法。
也许,从稀疏输入(sparse-input)线性模型到神经网络模型最大的飞跃,就是放弃将每一个特征作为一个维度的表示方式(所谓的 one-hot 表示),而使用密集型向量的表示方式。
NLP 分类系统的一般结构总结如下:
提取核心语言特征的集合;
为每一个向量检索关联向量;
组合特征向量;
将组合向量反馈给非线性分类器。
这个结构的关键在于使用密集型特征向量而不是稀疏特征向量,使用核心特征而不是特征组合。
需要注意在特征提取阶段中,神经网络只有提取核心特征。这和传统的基于线性模型的 NLP 不同,传统的 NLP 的特征设计必须手动设置以明确规定核心特征和其中的相互作用。
4. 前馈神经网络
这一节将提供前馈人工神经网络的速成课程。
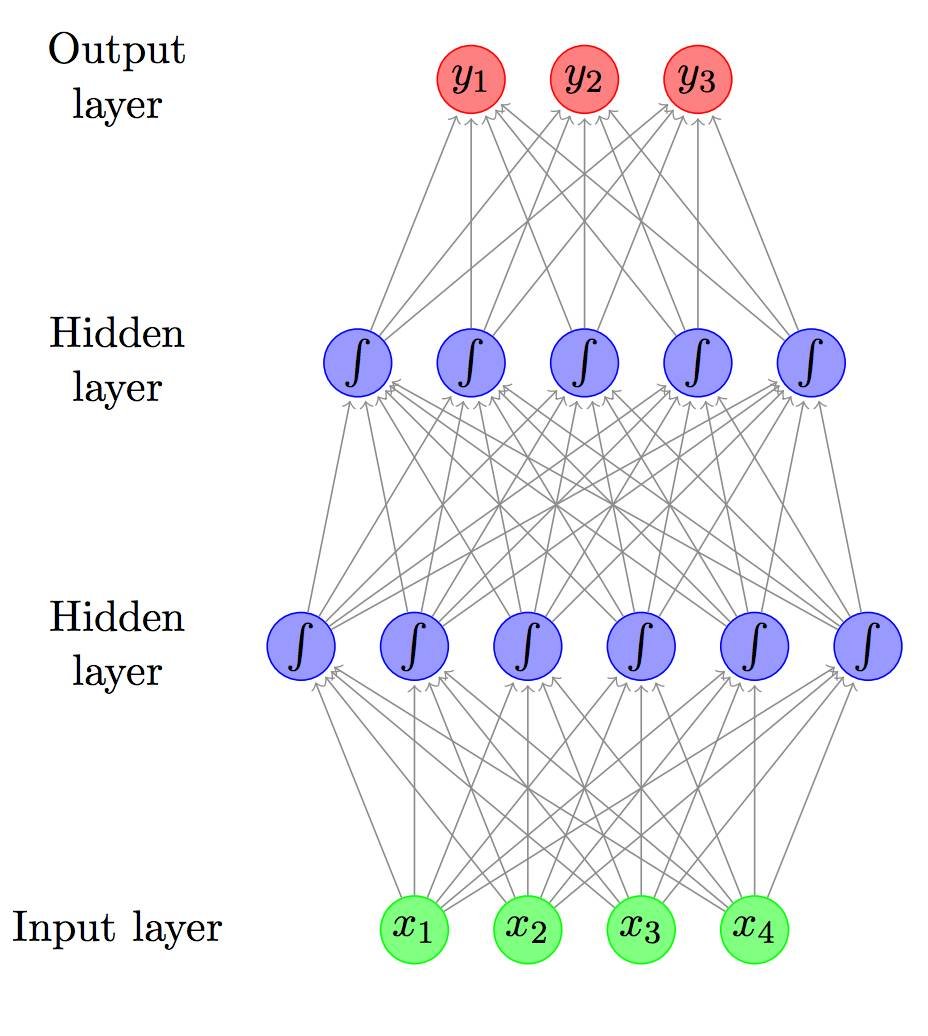
以「A Primer on Neural Network Models for Natural Language Processing」中含两个隐藏层的前馈神经网络为例。这些神经网络都是使用数学概念和脑启发的形式而表示出来的。通常神经网络的研究论题包括如下几个:
表示能力(e.g. 一般近似);
一般非线性特征(e.g. 变换函数);
输出的变换(e.g. softmax);
词汇嵌入(e.g. 嵌入式学习的密集型表征);
损失函数(e.g. 折叶(ReLU)和对数损失函数)。
5. 词嵌入
对于自然语言处理的神经网络方法来说,词嵌入表征是很重要的论题。这一节将展开这一论题并举几个关键方法的例子。神经网络在 NLP 中的流行一个重要原因是嵌入方法的使用,在低维空间中将每一个特征表征为一个向量。我们将回顾以下几个关于嵌入的论题:
随机初始化(e.g. 以统一的随机向量启动);
有监督特定任务的预训练(e.g. 迁移学习);
无监督预训练(e.g. 统计方法,如 word2vec 和 GloVe);
训练目标(e.g. 目标对输出向量的影响);
上下文的选择(e.g. 每一个词受到的周围的词的影响)。
神经词嵌入方法源于语言模型化方法,即训练网络以通过上文序列预测下一个词。
6. 神经网络训练
这一节篇幅较大,着重介绍神经网络的训练方式,面向对神经网络范式不熟悉的读者。神经网络的训练是通过梯度方法,尝试在一个训练数据集内最小化损失函数的过程。
这一节重点关注随机梯度下降(以及类似的 mini-batch)以及训练过程中的正则化方法。
有趣的是,神经网络的计算图观点的提出为一些实现深度学习模型的符号化数值程序库(symbolic numerical libraries),如 Theano 和 TensorFlow 提供了很好的入门方法。
只要图被建立起来,就能很直观的理解前向计算(计算输出结果)或者方向计算(计算梯度)。
7. 级联(Cascading)和多任务学习
这一节将在前一节的基础上,我们将总结级联 NLP 模型和多语言任务的学习模型。
级联模型:利用神经网络模型的计算图定义加入中间表征(编码)以建立更加复杂的模型。例如,我们可以通过近邻词汇,以及/或者其组成特征建立一个前馈网络来预测词汇。
多任务学习:各种相关的语言预测任务,并不互相反馈,但会在任务中分享信息。
预测命名实体的边界,以及语句的下一个词汇,都依赖于一些潜在的句法-语义表征上。这些高级概念都是在神经网络语境中描述的,以在模型之间建立关联的理解,或者在训练过程(误差反向传播)和预测过程中,共享信息。
8. 结构化输出的预测
这一节关注使用深度学习方法进行结构化预测的几个自然语言处理任务的例子,比如,序列、决策树和计算图。
典型例子有序列标注(e.g. 词性标注)的序列分割(分组,NER(命名实体识别)),以及句法分析。本节内容包括基于贪婪算法的和以搜索为核心的结构化预测,而主要集中讨论后者。
以搜索为核心是自然语言结构化预测的一般方法。
9. 卷积层
这一节提供了卷积神经网络的速成课程,以及讨论卷积网络对自然语言处理研究带来的变革。CNN 被证明在自然语言处理的分类任务上表现出色,比如情绪分析,e.g. 在文中寻找特定的子序列或者结构进行预测。
卷积神经网络一般被设计成在大型结构中用以识别 indicative local predictors,并将其组合以生成结构的固定大小的向量表征,捕捉这些 local aspects 对于预测任务来说是很有用的。
10. 循环神经网络
正如前一节一样,这一节也将介绍一种特定的网络和其在 NLP 中的应用。比如,应用 RNN 的序列建模。
循环神经网络允许在一个固定大小的向量中表示任意大小的结构化输入,而只关心输入的结构化性质。
由于 RNNs 在 NLP 中很受欢迎,尤其是 LSTM,这一节将讨论如下几个关于循环的论题和模型:
RNN 抽象概念(e.g. 网络图中的循环连接);
RNN 训练过程(e.g. 沿时间的反向传播);
多层(堆叠)RNN(e.g. 深度学习的「深」的解释);
BI-RNN(e.g. 前向和反向序列作为输入);
用于表示的 RNN 堆叠。
我们将集中讨论 RNN 模型结构或者结构元素中,特别是:
接收器(acceptor):在完整输入序列之后的输出的损失计算;
编码器(encoder):最后的向量作为输入序列的编码器;
变换器(transducer):在输入序列中,每一次观测生成一个输出;
编码器-译码器(encoder-decoder):输入序列在被译码成输出序列之前,编码成一个固定长度的向量。
11. 具体的 RNN 结构
这一节将在上一节的基础上讨论特定的 RNN 算法。比如:
简单 RNN(SRNN);
长短时记忆(LSTM);
门控循环单元(GRU)。
12. 模型建模
最后一节着重讨论一种更加复杂的网络,学习树型建模的递归神经网络。所谓的树包括了句法树,话语树,甚至是表示(由一句话的几个部分表达的)情绪的树。我们希望在特定的树节点上预测价值,价值预测以根节点为基础,或者为整棵树或者部分树指定一个预测值。
正如循环神经网络保持输入序列的状态,递归神经网络保持树节点的状态。
这里有一个递归神经网络的例子,取自「A Primer on Neural Network Models for Natural Language Processing.」
![]()
-
深度学习
+关注
关注
73文章
5492浏览量
120969 -
自然语言处理
+关注
关注
1文章
612浏览量
13504 -
nlp
+关注
关注
1文章
487浏览量
22010
发布评论请先 登录
相关推荐
NPU在深度学习中的应用
GPU深度学习应用案例
AI大模型与深度学习的关系
FPGA做深度学习能走多远?
GPT的定义和演进历程
深度学习中的时间序列分类方法
nlp自然语言处理模型怎么做
深度学习与卷积神经网络的应用
深度解析深度学习下的语义SLAM

什么是元宇宙,AR/VR和它又是什么关系呢?
为什么深度学习的效果更好?







 工商网监
工商网监
评论