 神经网络技术在网络视频处理的应用探讨
神经网络技术在网络视频处理的应用探讨
一、背景:
是一家集产品数据、专业资讯、科技视频、互动行销为一体的复合型媒体网站。公司内部每天都要对网站大量的文字,图片,视频进行处理。给视频贴标签,给文章配图,分类等等。公司主要是依赖人工来处理这些信息的,但是人工处理存在着工作量大,成本高,效率低的问题。于是公司组建了大数据部门,希望通过科技的手段来缓解人工处理信息的压力。
那么什么样的科技才能帮到我们呢?首先把目光投向了机器学习,也就是所谓的machinelearning。机器学习简单的说就是要让电脑自己学习,就像老师教学生数学题一样,先给计算机展示一些例子,然后让计算机自己去做题。希望通过这个理念来训练计算机思考,代替人力。能够实现机器学习的算法多种多样,每种算法都有自己的特点和优劣势。而我想要重点介绍的一个比较先进的算法,人工神经网络(ArtificialNeuralNetworks,简写为ANNs)。它是一种应用类似于大脑神经突触联接的结构进行信息处理的数学模型。神经网络的是一个较为新的算法概念。其出现使得机器学习有了突飞猛进的进展。人工神经网络在模式识别、智能机器人、自动控制、预测估计、生物、医学、经济等领域已成功地解决了许多现代计算机难以解决的实际问题,表现出了良好的智能特性。而卷积神经网络(cnn)更是用途最广的神经网络之一。它具有一定的抽象能力,可以提取数据的特征,鲁棒性较强。也就是说如果同一组数据发生了变化,卷积神经网络也一样可以适应这些变化。例如时下流行的人脸识别,新款的iPhone8和iPhoneX应用的正是卷积神经网络来做到的人脸解锁。百度搜索引擎也利用了卷积神经网络实现了精准的黄色,垃圾,恐怖等非法图片,非法网址的识别。
二、问题的提出:
由于目前谷歌等大型网络公司对神经网络的深入研究。现在卷积神经网络已经能对文字和图片的进行识别高效而准确的识别。但是对于视频内容的识别还处于开始阶段。于是我想在卷积神经网络在视频信息处理的可行性方面做出一点探究。而这次我把目光投向了游戏视频。
游戏直播一直都是网络直播行业的主力军。而为了保留下精彩瞬间吸引更多观众,各大直播平台也纷纷推出了自己的录播平台,上传自己游戏主播的精彩视频。但是,将整段整段的录播内容上传十分耗费时间,保留这些视频也十分耗费内存。如果能对视频进行切割,只保留有游戏的部分,除掉其它与游戏无关部分,将会大大缓解这些问题,并且还能方便看录像的观众跳过等待时间。但是,对视频进行分段十分耗费人力。中国目前知名的直播平台douyuTV,仅游戏类主播每天就能产生上千个小时的录播视频。人力将无法有效地处理如此庞大的数据量,因此我想尝试卷积神经网络是否能对这些游戏视频做出高效的处理。本文将通过机器学习来建立“绝地大逃杀”这款游戏视频的卷积神经网络模型,使其对这款游戏开始,游戏中,和结束3各阶段进行识别。
三、问题的研究分析:
实验对象分析:
绝地大逃杀是一款第一人称视角射击类游戏。游戏本身采用了当下比较流行MOBA类游戏模式。既游戏分为一场又一场的比赛,比赛之间相互独立,且每局比赛有鲜明的开始和结束画面,便于识别。在这方面与之相类似的还有很多人气很高的游戏:LeagueofLegend,dota2,Overwatch,等等。如果我能通过机器学习对这款游戏的视频进行分段,那么说明对其他游戏这类游戏也同样可行。
算法分析:
现在存在着很多种卷积神经网络,而我下面想要重点介绍2D卷积神经网络,和3d卷积神经网络。这两类卷积神经网络擅长于捕捉数据的特点并对其进行分类,正是我需要的算法。
2D卷积神经网络:
2D卷积神经网络比传统神经网络多出的部分就是卷积层和采样层。比如我们想识别所有带有狗的图片,而现在输入层是就是一张带有狗的图片。想要让神经网络理解什么是狗,我们先要大致预测这张照片展现了多少狗的特征,这就是卷积的含义了。如上图所示,如果我预测狗有40个特征,那么这一张照片将被分成40份(c1层),分别做检测,每一份检测一个特征。但是由于机器的限制,第一次卷积每一个特征的大小都是相同的,也就是说第一次卷积可能只检测到5x5像素大小的狗的特征。而还有一些狗的更大的特征无法被检测。于是我们要降采样。保留c1层检测到的特征的位置,把没有特征的像素去掉。我们得到了一张更模糊的图片(s1层),然后对这张更模糊的图片再次卷积,然后再降采样,如此往复,直到图片的像素少到难以判断这是什么的时候。最后一步,把所有最后一层的小图片们中的像素展开,形成一列,这一过程就是上图的全连接。把它们输入传统人工神经网络分析,得到输出,这到底是不是狗。
3D卷积神经网络:
3D卷积神经网络和2D卷积神经网络的思路相似,都是通过不断卷积,再降采样来识别输入数据的特征。但是与2D-cnn不同的是,3D-cnn侧重于识别连续样本中特征连续变化的特征。也就是说3D-cnn比较擅长处理连续变化的数据。所以3D-cnn多用于视频识别。如上图所示的是3D-cnn的卷积过程。首先把视频按照帧数输入到一个3维矩阵中。由于输入层是一个3维矩阵,那么卷积所要捕捉的特征也会是3维的。假设我想捕捉在连续五帧里5x5像素大小的特征,那么卷积核就的大小就是一个5x5x5的三维矩阵。最后的输出是上图的“输出特征图”,对应2D-cnn的C1层中的某一层。
四、问题的解决及验证:
目前看来比较主流的处理视频的算法是3d卷积神经网络,这次我采用的是传统的2d卷积神经网络,以下是我的分析。
虽然说3d卷积神经网络在能更好的识别视频中连续帧所包含的信息。然而,游戏视频有自己的一些特性。在游戏开始,进行,和结束阶段,视频画面往往会有很大的差异,例如“绝地大逃杀”这款游戏,游戏开始时玩家屏幕中会有一架飞机:
而游戏结束时显示的是计分板:
大部分游戏都会有这种鲜明的画面对比来告知玩家游戏开始,或结束了。所以用2d神经网络俩对这些帧做识别较为合适。3d卷积神逐帧会对视频逐帧分析,捕捉到视频的动态特点,但这些特点对视频截取没有额外的帮助。权衡之下我采用了传统2d卷积神经网络。通过对游戏中这些关键帧的识别来达到对游戏内容分段的效果。
然而2d神经网络也存在自己的问题。我第一次训练的时候从两个游戏视频中截取了532张图片做训练,结果损失函数很快地就收敛了,准确率也一直高地惊人,仅仅10次训练就达到了100%。但是当我用该模型测试一段全新的视频时,准确率确只有65%左右。经过反复思考,我发现问题产生在我用于做训练的视频太少,而我截取的样本容量却太多。虽然通过密集地截取视频帧数可以获得大量的训练样本,但是这些样本存在很大问题。邻近帧数的图片往往差异比较小,将这些差异极小的图片大量地输入神经网络会导致训练的准确率虚高,且模型容易训练过度。因此,这次我在训练时特别注意了这个细节,找到了12段不一样的视频,只截取了1000张左右的图片。
搭建神经网络:
所有激活函数均采用了ReLU函数来作为激活函数,以便加速收敛。卷积神经模型,分3层卷积网络。每层提取8x8大小的特征40个,每次卷积完后用2x2大小的filter进行maxpool。最后展开层有5400个神经元,算上输入层一共有7层。
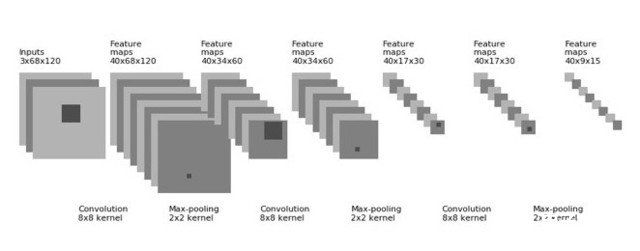
Input:(3,68,120)float32
layer0:cnn1/Relu:0(68,120,40)float32
layer1:pool1:0(34,60,40)float32
layer2:cnn2/Relu:0(34,60,40)float32
layer3:pool2:0(17,30,40)float32
layer4:cnn3/Relu:0(17,30,40)float32
layer5:pool3:0(9,15,40)float32
layer6:flatten:0(5400,)float32
接下来对有5400个神经元的展开层后面加一个50%dropout率的Dropout层。接下来第8,10,12层为全连接层,9,11层又是Dropout层,Dropout率均为50%。12层为输出层,输出3个值为某一帧是游戏开始,游戏中,游戏结束可能性的参数。
layer7:drop1/mul:0(5400,)float32
layer8:relu1/Relu:0(5000,)float32
layer9:drop2/mul:0(5000,)float32
layer10:relu2/Relu:0(1024,)float32
layer11:drop3/mul:0(1024,)float32
layer12:output/Identity:0(3,)float32
增加dropout层可以大大减少模型对样本容量的需求,而且也可以防止过度训练。
最后,训练将采用minibatch来提高训练的速度。每十组数据分为一个batch。所以真正训练时的神经网络比上述的神经网络每一层都多一维度,且该维度一直为10,例如输入层大小为(10,3,68,120)。
训练:
本次实验在本人自己的工作电脑本上进行。Intel(R)Core(TM)i7-6700HQCPU@2.6Hz,英伟达GTX970显卡。12个游戏视频作为训练样本,这些视频全部来自于www.bilibili.com,从视频中以游戏开始,游戏进行,游戏结束这3个阶段较为平均地抽取了1013张截图作为训练样本。这些图片又被以7:3的比例分为训练组和验证组。取帧软件为Windows自带的ffmpeg,截取下的图片大小为1280*720,为了减少内存的压力,用numpy把图片转换成120*68的大小。搭建神经网络时使用python作为编程语言,主要应用tensorflow和tensorlayer来进行神经网络的搭建。
由于邻近帧数的画面可能会彼此之间十分相似,当这相似的两张图片分别被分进了训练组和验证组便会导致验证组的准确率虚高。所以为了减少这种情况干扰模型的准确率,验证组中的画面全部来自于与训练组不同的游戏视频。训练时将对这1013张图片反复训练200次,每过10次,输出一次训练组和验证组的损失参数和准确率。
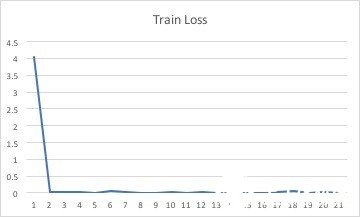
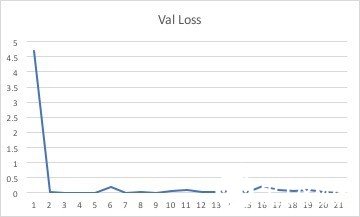
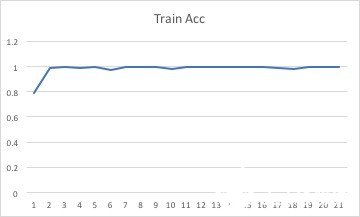
结果:
训练结果由下图看可见。横轴坐标中从2到21,每个数据代表着10次运算后的平均值。只有横坐标为1时,代表了训练了一次之后所得的结果。
损失函数:
准确率:
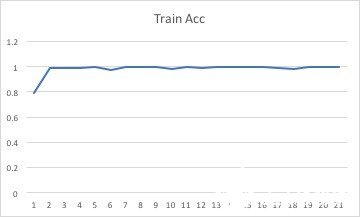
除去第一组数据后的损失函数:
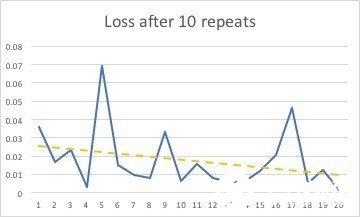
除去第一组数据后的准确率函数:
在200次循环计算过程中平均每次循环花费3.292319秒,整个程序大约耗时12分钟。
五、总结:
对比验证组数据和训练组数据,可以发现两者之间存在的差异较小,说明搭建的模型比较真实的捕捉到了游戏中3个阶段的特点,说明该2D-cnn模型克服了邻近帧相似的问题。
从200次循环得到的数据来看,损失函数和准确率函数均有收敛的趋势。但是在训练样本只有12个视频的情况下再进行更多的重复训练也不会更加提高模型的准确率,反而有可能过度训练。由于一个人力量有限,无法提供更多的训练样本。如若能有更多的训练样本和更好的硬件设备,相信可以训练出更加准确的模型来模仿这款游戏的进程从而对其进行分段。由此可见,通过2d卷积神经网络来对游戏视频进行分段是完全可行的。
如果以后这个算法被改良后用于视频分段和视频截取,将大大节省人工处理视频的时间。目前我的程序处理1000左右帧的图片需要话费约3.2秒,1000/3.2也就是312.5帧每秒。而一般人眼可有效识别的帧数的频率大概是24帧每秒。由此可见神经网络的运算速度远远高于人工的速度,约为人工的13倍。如果这种视频分段方法被加以利用,可以大大减少人工时间。
此外除了对视频进行简单的分类,截取。对于特定游戏视频加入对某些特点画面的识别,例如许多游戏都有计分板,记录玩家得分,对它们进行识别可以大致判断玩家在这段视频中的表现。又或者一些低概率发生的事件,发生时游戏画面也会发生特定的变化。神经网络完全可以识别这些细节,然后再对整个视频的精彩程度加以判断,把精彩的游戏视频推送给感兴趣的人。我们甚至还可以加入声音的识别,对截取的视频配上字幕,方便听力不好的观众观看。
-
神经网络
+关注
关注
42文章
4769浏览量
100685 -
函数
+关注
关注
3文章
4325浏览量
62552 -
机器学习
+关注
关注
66文章
8401浏览量
132534
发布评论请先 登录
相关推荐
详解深度学习、神经网络与卷积神经网络的应用






 工商网监
工商网监
评论