 图嵌入的用处和方法
图嵌入的用处和方法
导读
这篇文章描述了什么是图嵌入,图嵌入的用处,并对比了常用的几种图嵌入方法。
图常用在现实世界的不同场景中。社交网络是人们相互联系的大型图,生物学家使用蛋白质相互作用的图,而通信网络本身就是图。他们在文本挖掘领域使用词共现图。对在图形上使用机器学习的兴趣正在增长。他们试图在社交媒体上预测新的联系,而生物学家预测蛋白质的功能标签。图上的数学和统计操作是有限的,将机器学习方法直接应用到图上是很有挑战性的。在这种情况下,嵌入似乎是一个合理的解决方案。
什么是图嵌入?
图嵌入是将属性图转换为一个或一组向量。嵌入应该捕获图的拓扑结构、顶点到顶点的关系以及关于图、子图和顶点的其他相关信息。更多的属性嵌入编码可以在以后的任务中获得更好的结果。我们大致可以将嵌入分为两组:
顶点嵌入:我们用每个顶点(节点)自己的向量表示对其进行编码。当我们想要在顶点层次上执行可视化或预测时,我们会使用这种嵌入,例如在二维平面上对顶点进行可视化,或者基于顶点相似性预测新的连接。
图嵌入:这里我们用一个向量表示整个图。当我们想要在图的层次上做出预测时,以及当我们想要比较或可视化整个图时,例如比较化学结构时,就会用到这些嵌入。
稍后,我们将介绍来自第一组的一些常用方法(DeepWalk、node2vec、SDNE)和来自第二组的graph2vec方法。
我们为什么要用到图嵌入?
图是一种有意义的、可理解的数据表示,但是需要使用图嵌入的原因如下:
机器学习在图上的应用是有限的。图由边和节点组成。这些网络关系只能使用数学、统计和机器学习的特定子集,而向量空间有更丰富的方法工具集。
嵌入是压缩的表示。邻接矩阵描述图中节点之间的连接。它是一个|V| x |V|矩阵,其中|V|是图中的一些节点。矩阵中的每一列和每一行都表示一个节点。矩阵中的非零值表示两个节点连接。对于大型图,使用邻接矩阵作为特征空间几乎是不可能的。假设一个图有1M个节点和一个1M x 1M的邻接矩阵。嵌入比邻接矩阵更实用,因为它们将节点属性打包到一个维度更小的向量中。
向量运算比图上的运算更简单、更快。
挑战
嵌入方法需要满足更多的需求。这里我们描述了嵌入方法面临的三个挑战:
我们需要确保嵌入能够很好地描述图的属性。它们需要表示图拓扑、节点连接和节点邻居。预测或可视化的性能取决于嵌入的质量。
网络的大小不应降低嵌入过程的速度。图通常很大。想象一下拥有数百万人的社交网络。好的嵌入方法需要在大型图上有效。
一个基本的挑战是决定嵌入维数。较长的嵌入保存了更多的信息,同时它们比排序器嵌入带来更高的时间和空间复杂度。用户需要根据需求做出权衡。在文章中,他们通常报告说,嵌入大小在128到256之间就足够完成大多数任务。在Word2vec方法中,他们选择了嵌入长度300。
Word2vec
在介绍嵌入图的方法之前,我将讨论Word2vec方法和skip-gram神经网络。它们是图形嵌入方法的基础。
Word2vec是一种将单词转换为嵌入向量的嵌入方法。相似的单词应该有相似的嵌入。Word2vec采用skip-gram网络,skip-gram网络具有一个隐含层的神经网络。skip-gram被训练来预测句子中的相邻单词。这个任务被称为伪任务,因为它只是在训练阶段使用。网络在输入端接受单词,并对其进行优化,使其能够以较高的概率预测句子中的相邻单词。下图显示了输入单词(用绿色标记)和预测单词的示例。通过这个任务,作者实现了两个相似的单词具有相似的嵌入,因为具有相似含义的两个单词很可能具有相似的邻域单词。
用绿色表示网络。优化后的算法能较好地预测邻域内的词,具有较高的预测概率。在本例中,我们考虑距离所选单词最远的两个位置的单词。
下图所示的skip-gram神经网络有输入层、隐藏层和输出层。网络接受one -hot编码。one -hot编码是一个长度与单词字典数量相同的向量,只有一个1其他都是0。这个1出现的位置是字典中出现编码单词的地方。隐藏层没有激活函数,它的输出是一个单词的嵌入。输出层是一个预测邻域单词的softmax分类器。
我将介绍四种图形嵌入方法。其中三个节点嵌入节点,而一个节点用一个向量嵌入整个图。他们将Word2vec中的嵌入原则应用于三种方法中。
顶点嵌入方法
我将介绍在图中嵌入节点的三种方法。之所以选择它们,是因为它们在实践中经常使用,并且通常提供最好的结果。在深入讨论之前,我可能会提到节点嵌入的方法可以分为三大类:因子分解方法、随机游走方法和深度方法。
DeepWalk使用随机游走来生成嵌入。从选定的节点开始随机游走,然后我们从当前节点随机移动到邻居,执行一定数量的步骤。
该方法主要包括三个步骤:
抽样:通过随机游走对图进行采样。从选到的节点执行的随机游走很少。作者证明,从每个节点执行32到64步随机游走就足够了。它们还表明,良好的随机游走的长度约为40步。
训练skip-gram:随机游走相当于word2vec方法中的句子。skip-gram网络接受随机游走中的一个节点作为one hot向量作为输入,最大限度地提高了预测相邻节点的概率。它通常被训练来预测大约20个邻居节点——左边10个节点和右边10个节点。
计算嵌入:嵌入是网络隐含层的输出,DeepWalk计算图中每个节点的嵌入。
DeepWalk方法执行随机遍历,这意味着嵌入不能很好地保留节点的局部邻域。Node2vec方法解决了这个问题。
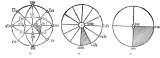
Node2vec是DeepWalk的一个改进,只是随机游动的差异很小。它有参数P和Q。参数Q定义了random walk发现图中未发现部分的概率,而参数P定义了random walk返回到前一个节点的概率。参数P控制发现节点周围的微观视图。参数Q控制较大邻域的发现。它推断出社区和复杂的依赖关系。
图中显示了Node2vec中随机行走步长的概率。我们只是从红结点到绿结点跨了一步。返回到红色节点的概率为1/P,而返回到与前一个(红色)节点没有连接的节点的概率为1/Q。到红结点相邻结点的概率是1。
嵌入的其他步骤与DeepWalk方法相同。
结构深度网络嵌入(SDNE)与前两种方法没有任何共同之处,因为它不执行随机游走。我之所以提到它,是因为它在不同任务上的表现非常稳定。
它的设计使得嵌入保持了一阶和二阶的接近性。一阶近似是由边连接的节点之间的局部成对相似性。它描述了局部网络结构。如果网络中的两个节点与边缘连接,则它们是相似的。当一篇论文引用了另一篇论文,这意味着它们涉及了类似的主题。二阶邻近度表示节点邻域结构的相似性。它捕获了全球网络结构。如果两个节点共享许多邻居,它们往往是相似的。
作者提出了一个自动编码器神经网络,它有两个部分。自编码器(左、右网络)接受节点邻接向量,训练自编码器重构节点邻接。这些自动编码器被称为vanilla自动编码器,它们学习二阶近似。邻接向量(邻接矩阵中的一行)在表示连接到所选节点的节点的位置上具有正值。
还有一个网络的监督部分——左翼和右翼之间的联系。它计算从左到右的嵌入距离,并将其包含在网络的共同损失中。网络经过这样的训练,左、右自动编码器得到所有由输入边连接的节点对。距离部分的损失有助于保持一阶近似。
网络的总损失是由左右自编码器的损失和中间部分的损失之和来计算的。
图嵌入方法
最后一种方法对整个图进行了嵌入。它计算一个描述图形的向量。我选择graph2vec方法,因为据我所知,它是图形嵌入的最佳方法。
Graph2vec基于doc2vec方法的思想,该方法使用了skip-gram网络。它在输入上获取文档的ID,并经过训练得到最大化从文档中预测随机单词的概率。
Graph2vec方法包括三个步骤:
从图中采样并重新标记所有子图。子图是出现在所选节点周围的一组节点。子图中的节点距离不超过所选边数。
训练跳跃图模型。图类似于文档。由于文档是一组单词,所以图是一组子图。在此阶段,对skip-gram模型进行训练。它被训练来最大限度地预测存在于输入图中的子图的概率。输入图作为独热向量。
计算嵌入提供一个图形ID作为独热向量作为输入。嵌入是隐藏层的结果。
由于任务是预测子图,具有相似子图和相似结构的图具有相似的嵌入。
其他的嵌入方法
我提出了四种文献中常用的方法。由于这个主题目前非常流行,所以可以使用更多的方法。这里我列出了其他可用的方法:
顶点嵌入方法:LLE,拉普拉斯特征映射,图分解,GraRep, HOPE, DNGR, GCN, LINE
图嵌入方法:Patchy-san, sub2vec (embed subgraphs), WL kernel和deep WL kernel
-
机器学习
+关注
关注
66文章
8420浏览量
132689
发布评论请先 登录
相关推荐
DAC1282的正弦波模式有什么用处?
LDO在嵌入式系统中的应用 常见LDO故障及解决方法
嵌入式系统开发中的测试方法 嵌入式系统开发与AI结合应用
反极图实验数据的分析方法

晶体取向反极图实验数据的采集方法







 工商网监
工商网监
评论