 基于PCI Expres总线实现DMA控制逻辑的设计
基于PCI Expres总线实现DMA控制逻辑的设计

随着相控阵雷达、超宽带雷达、数字阵列雷达相继地出现,雷达的回波数据量在不断地增加,因此对高速采集和大容量数据传输提出了越来越高的要求。早期基于PCI总线的高速数据采集系统在带宽、流量控制和数据传送质量上存在一定缺陷,在某种程度上并不能完全适应高速大容量数据存储的要求。相比较而言,PCI Expres总线具有鲜明的技术优势,不仅完全兼容PCI总线,而且全面解决了PCI总线所面临的带宽、流量控制和数据传送质量方面问题,由于使用高速差分总线,时钟频率可以达到较高水平,其总线带宽较PCI总线也有大幅度提升,目前X16的PCI Express峰值带宽可以达到80 GT/s。PCI Express技术的逐步成熟,为高速数据数据传输提供了较好的解决方案。
1、 DMA控制逻辑设计
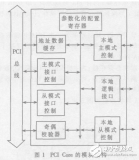
DMA控制逻辑设计如图1所示,主要有PCIExpress Core、接收引擎、发送引擎、DMA控制状态寄存器和中断控制等关键模块。
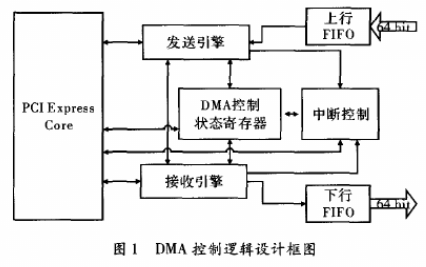
1.1 PCI Express Core
主要特点如下:(1)符合PCI Express Base Specification 2.0规范。(2)支持X1、X2、X4或X8模式。(3)片上GTP/GTX收发器实现PHY。(4)具有访问PCI Express配置空间和内部配置的管理接口。(5)支持最大的有效载荷(128~4 096 Byte)。(6)可针对存储器或I/O进行配置的基地址寄存器(BAR)。
1.2 接收引擎
在PCI Express系统逻辑结构中,接收引擎主要是在接口时钟的控制下,按照基本TLP接收时序,解析存储器读写请求并从TLP中提取所需信息并将其传送到存储器访问控制器,存储器访问控制器处理存储器写TLP中写入存储器的数据,并使用存储器中的数据读来响应存储器读TLP;此外接受引擎主要还负责处理存储器读完成TLP,响应板卡发起的DMA读操作。
1.3 发送引擎
在PCI Express系统逻辑结构中,发送引擎主要是在接口时钟的控制下,按照基本TLP发送时序,为接收到的存储器读TLP生成完成包,生成该完成包所需的信息会由存储控制器传送到发送引擎;此外发送引擎还负责发起存储器读写请求TLP,实现与PC之间数据的DMA读写。
1.4 DMA状态控制寄存器
在PCI Express系统逻辑结构中,DMA状态控制寄存器主要是实现PCI Express Core与Root Complex之间数据的传递。Windows GUI软件配置DMA控制状态寄存器控制DMA操作。DMA控制状态寄存器映射于PCI Express Memory BAR0空间,Windows GUI软件通过Memory Write和Read周期访问寄存器。Windows GUI软件初始化DMA控制寄存器发起DMA传输,而通过状态寄存器,以中断方式通知Root Complex DMA传输完成。
1.5 中断控制
当DMA传输结束时,为及时通知PC响应并处理中断,中断控制部分使用核的配置层接口信号产生中断。PCI Express支持两种中断:消息信号中断(MSI)和传统中断(Legacy INT)。在PCI Express设备枚举过程中,跟联合体会根据自身对中断支持的能力设置配置空间中的命令寄存器和消息信号中断能力寄存器,来决定使用何种中断。
2、 PCI Express Masfer DMA读写设计验证
2.1 DMA写设计验证
数据流向:上行FIFO数据→PCI Express Master DMA Write→PC内存→PC硬盘。
整个DMA写过程如下:(1)复位FPGA逻辑,延时1 ms;去除FPGA逻辑,延时1 ms。(2)检测硬件链路初始化。(3)开启DMA写完成中断。(4)设置DMA写目的地址寄存器,设置DMA写传输长度寄存器。(5)启动DMA写操作,选择记录路径。(6)等待DMA写完成中断。(7)清除中断,内存数据转到硬盘。(8)DMA写是否结束,是则转至步骤(9);否则转至步骤(4)。(9)终止DMA写,关闭DMA写完成中断,断开记录路径。
下面给出从PCI Express Core到系统内存的DMA写时序,图2是用ChipScope截取的时序图。

T0~T1之间核接收事务接口上m_axis_rx_tvalid与m_axis_rx_tlast共同有效了8次,即执行了8次PIO内存读写操作。其中第6次为PIO读操作,相应的发送事务接口上s_axis_tx_tvalid与s_axis_tx_tlast有效,产生Cpld完成包以回应PIO读操作。从图中可以看出,DMA状态控制寄存器配置完成后,dma_wr_start信号有效,即启动DMA写操作。此后PCI Express Core开始在发送事务接口上发送存储器写事物包,事物包的地址、大小已经在DMA状态控制寄存器中配置。
2.2 DMA读设计验证
数据流向:PC硬盘→PC内存→PCI Express Master DMA Read→下行FIFO数据。
整个DMA读过程如下:(1)复位FPGA逻辑,延时1 ms;去除FPGA逻辑,延时1 ms。(2)检测硬件链路初始化。(3)开启DMA读完成中断。(4)设置DMA读目的地址寄存器,设置DMA读传输长度寄存器。(5)PC硬盘数据转到内存。(6)启动DMA读操作,选择回放路径。(7)等待DMA读完成中断。(8)清除中断,硬盘数据转到内存。(9)DMA读是否结束,是则转至步骤(10);否则转至步骤(4)。(10)终止DMA读,关闭DMA读完成中断,断开回放路径。
下面给出从系统内存到PCI Express Core的DMA读时序,图3是用ChipScope截取的时序图。

T1~T2之间核接收事务接口上m_axis_rx_tvalid与m_axis_rx_tlast共同有效了3次。此处需要说明的是DMA读操作在配置完寄存器后需要先从PC硬盘将数据转到内存开辟的数据缓冲区,此后才能开始DMA读操作,故T1~T2之间核接收事务接口上m_axis_rx_tvalid与m_axis_rx_ tlast有效为配置DMA读地址和启动DMA读操作。当DMA读操作启动后,核的发送事务接口上s_axis_tx_tvalid与s_axis_tx_tlast有效,发送存储器读请求包,当PC收到PCI Express Core发出的存储器读请求包后会根据TLP中的信息回复相应的Cpld完成包。根据PCIExpress总线规范中对PCI Express序的规定,允许接收事务接口在接收Cpld完成包的同时发送事务接口在发送存储器读请求包,见图中T1~T2之间所示。
2.3 PCI Express中断控制
当DMA写结束,即dma_wr_done或dma_rd_done其中之一有效时,用户应该通过配置接口cfg_interrupt和cfg_interrupt_assert来提交中断,当核接收到有效中断时将cfg_interrupt_rdy置为有效,表示中断请求被接受。PC通过读DMA中断寄存器从而认领中断事务,响应处理中断后清除中断。用ChipScope捕获的DMA读写完成中断时序,如图4所示。

3、 系统性能测试
系统性能测试结果如表1所示。存储器读写DMA数据有效带宽测试为DMA启动到最后一个存储器写TLP或最后一个存储器读完成包,测试数据总量为8 GB。
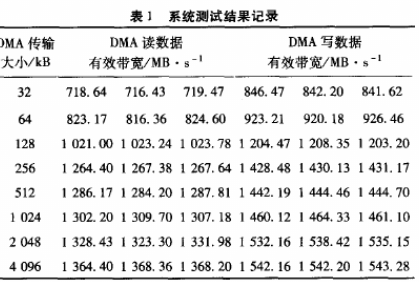
测试平台:Xilinx ML605开发板(Virtex-6 FPGA);Windows7 64位操作系统,Windriver驱动;PCIExpress链路宽度:X8,PCI Express Core版本:V2.5;MaxPayload Size:128 Bytes;Max Read Request Size:512 Byte;Root Complex Read Completion Boundary:64 Byte。
4 、结束语
研究了基于Xilinx PCI Express Core的高速DMA读写设计,适用于现代雷达系统和高速数据采集系统的要求,并具有良好的移植和扩展性。文中给出了DMA设计框图,并对系统各部分进行了分析。系统设计中主要研究了PCI Express Master DMA读写设计及中断控制,并给出了DMA读写和中断控制的采样时序,通过系统性能测试数据,可以看出本文所设计的基于Xilinx PCI Express Core的高速DMA读写可以满足高速信号处理的要求。
责任编辑:gt
-
寄存器
+关注
关注
31文章
5622浏览量
130577 -
存储器
+关注
关注
39文章
7768浏览量
172387 -
总线
+关注
关注
10文章
3065浏览量
91945
发布评论请先 登录
基于IP核的PCI总线接口设计与实现
PCI总线接口芯片9054及其应用
基于PCI总线的CPLD实现
ISA总线的标准DMA技术在Linux中的实现
总线接口控制器PCI9052资料推荐
利用S5935实现DMA传输的研究
基于PCI Express总线高速数据采集卡的设计与实现
PCI总线至UTOPIA接口控制的CPLD设计实现

PCI Express总线介绍与光纤通道HBA卡DMA引擎的设计与实现
S5935如何实现DMA传输的设计与研究
基于PCI Core的链式DMA控制器设计



评论