 NPU时代来临,瑞芯微AI芯片与Paddle Lite完成适配
NPU时代来临,瑞芯微AI芯片与Paddle Lite完成适配
5月13日,百度飞桨开源深度学习平台与瑞芯微Rockchip旗下AI芯片RK1808、RK1806正式完成适配,充分兼容飞桨轻量化推理引擎Paddle Lite。此次百度与瑞芯微的合作,旨在为AI行业赋能更多应用场景,加速AI产品落地进程。
在AI时代,深度学习框架和操作系统类似,起着承上启下的作用,连接芯片与应用。拥有强大算力的AI芯片加持,AI技术将得到更广泛普及。
NPU时代来临软硬结合性能优化
飞桨产业级深度学习开源平台以百度多年的深度学习技术研究和产业应用为基础,集深度学习核心训练和预测框架、基础模型库、端到端开发套件、工具组件和服务平台于一体,2016年正式开源,是中国极具影响力的全面开源开放、技术领先、功能完备的产业级深度学习平台。Paddle Lite是飞桨推出的一套功能完善、易用性强且性能卓越的轻量化推理引擎,支持多种硬件、多种平台,具备轻量化部署、高性能实现等重要特性。
瑞芯微RK18xx系列芯片适配Paddle Lite
瑞芯微AI芯片RK1808及RK1806,内置独立NPU神经计算单元,INT8 算力高达3.0TOPs;采用22nm FD-SOI工艺,相同性能下的功耗相比主流28nm工艺产品降低约30%,在算力、性能、功耗等指标上均有优异的表现。经实测,瑞芯微AI芯片在Paddle Lite中运行MobileNet V1耗时仅为6.5 ms,帧率高达153.8 FPS,二者充分兼容并高效稳定运行。
如下图所示的实测結果可以看出,与手机等移动端常用的国内外主流CPU相比,RK18系列NPU在MobileNET_v1的耗时表现出色,由此证明在AI相关领域,如图像分类、目标检测、语音交互上,专用的AI芯片将带来更出色的效果。
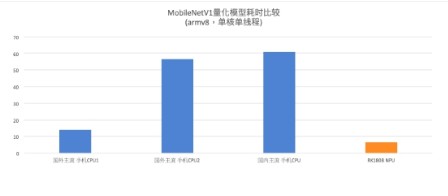
瑞芯微RK18xx系列芯片在 MobileNETV1上对比主流CPU 性能卓越
通过适配飞桨开源深度学习平台,瑞芯微芯片将能更好地赋能国内用户的业务需求,为端侧AI提供强劲算力;二者的融合,将充分发挥软硬件结合的优势,加快开发部署速度,推动更多AI应用的落地。
国产芯合作升级实操教程详解
在飞桨上,瑞芯微AI芯片的详细操作方法可参考Paddle Lite文档,内容涵盖支持的芯片、设备列表、Paddle模型与算子及参考示例演示等等。
测试设备
此外,除RK1808及RK1806芯片解决方案外,瑞芯微旗下搭载NPU的AI系列芯片也将陆续升级适配百度飞桨,进一步深化双方合作关系,携手助力我国自主可控AI生态的构建。
责任编辑:pj
-
芯片
+关注
关注
453文章
50387浏览量
421781 -
AI
+关注
关注
87文章
30106浏览量
268394 -
深度学习
+关注
关注
73文章
5492浏览量
120975
发布评论请先 登录
相关推荐
什么是NPU芯片及其功能
迅为瑞芯微RK3588与3588S如何选型硬件区别

探索AI时代“芯”路径 软通动力子公司鸿湖万联助阵第八届瑞芯微开发者大会

RKDC2024 |亿晟科技亮相第八届瑞芯微开发者大会,共赢AI未来!






 工商网监
工商网监
评论