 一种新型解决方案:将表征学习和分类器学习分开
一种新型解决方案:将表征学习和分类器学习分开
在图像分类任务中类别不均衡问题一直是个难点,在实际应用中大部分的分类样本很可能呈现长尾分布。新加坡国立大学和 Facebook AI 的研究者提出了一种新型解决方案:将表征学习和分类器学习分开,从而寻找合适的表征来最小化长尾样本分类的负面影响。该论文已被 ICLR 2020 接收。
图像分类一直是深度学习领域中非常基本且工业应用广泛的任务,然而如何处理待分类样本中存在的类别不均衡问题是长期困扰学界与工业界的一个难题。相对来说,学术研究提供的普通图像分类数据集维持了较为均衡的不同类别样本分布;然而在实际应用中,大部分的分类样本很可能呈现长尾分布(long-tail distribution),这很有可能导致分类模型效果偏差:对于尾部的类别分类准确率不高。 针对长尾分布的图像识别任务,目前的研究和实践提出了大致几种解决思路,比如分类损失权重重分配(loss re-weighting)、数据集重采样、尾部少量样本过采样、头部过多样本欠采样,或者迁移学习。 在 ICLR 2020 会议上,新加坡国立大学与 Facebook AI 合著了一篇论文《Decoupling Representation and classifier for long-tailed recognition》,提出了一个新颖的解决角度:在学习分类任务的过程中,将通常默认为联合起来学习的类别特征表征与分类器解耦(decoupling),寻求合适的表征来最小化长尾样本分类的负面影响。

论文链接:https://openreview.net/pdf?id=r1gRTCVFvB
GitHub 链接:https://github.com/facebookresearch/classifier-balancing
该研究系统性地探究了不同的样本均衡策略对长尾型数据分类的影响,并进行了详实的实验,结果表明:a) 当学习到高质量的类别表征时,数据不均衡很可能不会成为问题;b) 在学得上述表征后,即便应用最简单的样本均衡采样方式,也一样有可能在仅调整分类器的情况下学习到非常鲁棒的长尾样本分类模型。 该研究将表征学习和分类器学习分离开来,分别进行了延伸探究。 表征学习 对于表征学习来说,理想情况下好的类别表征能够准确识别出各种待分类类别。目前针对长尾类型数据分类任务,不同的采样策略、损失权重重分配,以及边界正则化(margin regularization)都可用于改善类别不均。 假设 p_j 为样本来自类别 j 中的概率,则 p_j 可用如下公式表示:
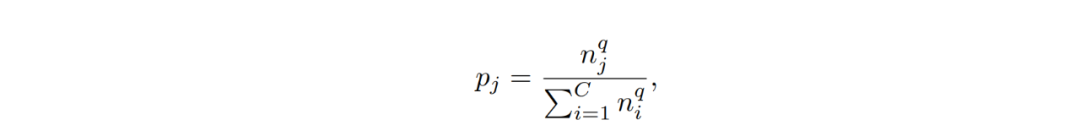
其中 n 为训练样本总数,C 为训练类别总数,而 q 为 [0,1] 其中一个值。 采样策略包含以下几种常用采样方式:
样本均衡采样(Instance-balanced sampling):该方法最为常见,即每一个训练样本都有均等的机会概率被选中,即上述公式中 q=1 的情况。
类别均衡采样(Class-balanced sampling):每个类别都有同等的概率被选中,即公平地选取每个类别,然后再从类别中进行样本选取,即上述公式中 q=0 的情况。
平方根采样(Square-root sampling):本质上是之前两种采样方式的变种,通常是将概率公式中的 q 定值为 0.5。
渐进式均衡采样(Progressively-balanced sampling):根据训练中的迭代次数 t(epoch)同时引入样本均衡(IB)与类别均衡(CB)采样并进行适当权重调整的一种新型采样模式,公式为
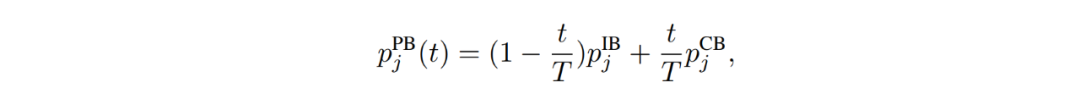
其中 T 为数据集训练迭代总数。 分类器学习 该研究也针对单独拆分出来的分类器训练进行了调研和分类概括:
重训练分类器(Classifier Re-training, cRT):保持表征固定不变,随机重新初始化分类器并进行训练。
最近类别平均分类器(Nereast Class Mean classifier, NCM):首先计算学习到的每个类别特征均值,然后执行最近邻搜索来确定类别。
τ-归一化分类器(τ-normalized classifier):作者提出使用该方法对分类器中的类别边界进行重新归一化,以取得均衡。
实验结果 通过以上观察和学习拆分,该研究在几个公开的长尾分类数据集上重新修改了头部类别和尾部类别的分类决策边界,并且搭配不同的采样策略进行交叉训练实验。训练出的不同分类器之间的对比结果如下图所示:
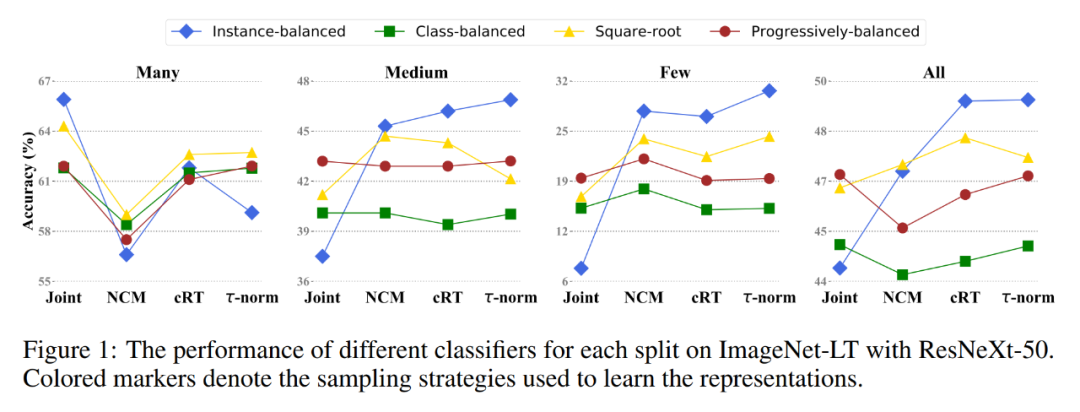
同时,在 Places-LT、Imagenet-LT 和 iNaturalist2018 三个公开标准数据集上,该研究提出的策略也获得了同比更高的分类准确率,实现了新的 SOTA 结果:
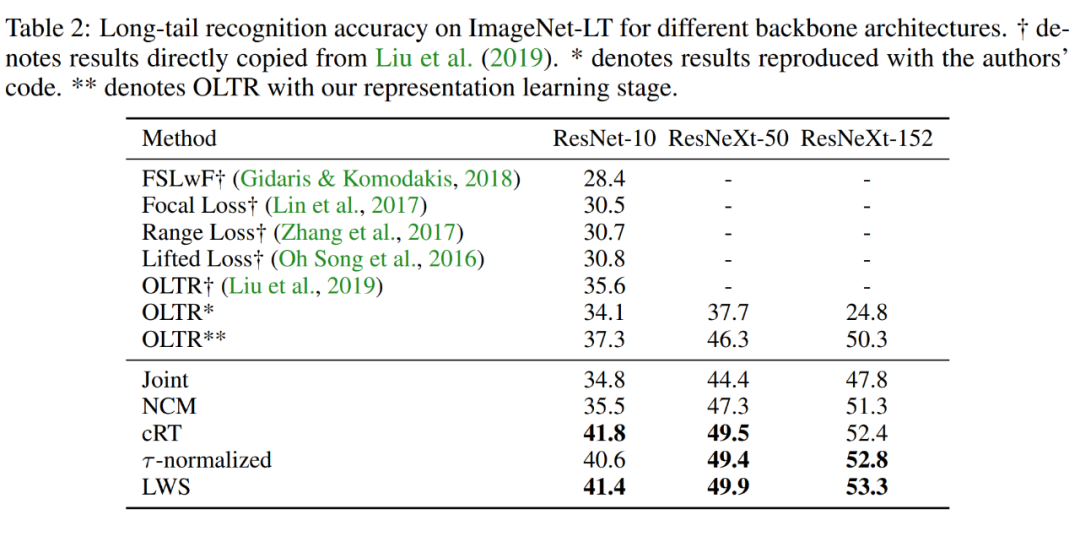
通过各类对比实验,该研究得到了如下观察: 1. 解耦表征学习与分类为两个过程均取得了非常好的效果,并且打破了人们对长尾分类固有的「样本均衡采样学习效果最好,拥有最具泛化性的特征表示」这一经验之谈。 2. 重新调整分类边界对于长尾分布的物体识别来说是非常有效的。 3. 将该研究提出的解耦学习规则应用到传统网络(如 ResNeXt)中,仍能取得很好的效果,这说明该策略确实对长尾分类具备一定指导意义。 该研究针对业界和学界频繁遇到的长尾样本分类难题,提出解构传统的「分类器表征联合学习」范式,从另一个角度提供了新思路:调整它们在表征空间的分类边界或许是更加高效的方法。 该研究思路比较新颖,实验结果也具有一定的代表性。对于研究长尾分类的学者或者业界工程师而言,这在传统采样方式下「面多了加水,水多了加面」的经验之外,提供了额外思路。目前该研究的相关代码已在 GitHub 上开源,感兴趣的读者可以下载进行更多的尝试。 代码实现 研究者在 GitHub 项目中提供了对应的训练代码和必要的训练步骤。代码整体是相对基本的分类训练代码,比较容易实现。具体到复现模型训练,作者也给出了几点注意事项。 1. 表征学习阶段
学习过程中保持网络结构(比如 global pooling 之后不需要增加额外的全连接层)、超参数选择、学习率和 batch size 的关系和正常分类问题一致(比如 ImageNet),以确保表征学习的质量。
类别均衡采样:采用多 GPU 实现的时候,需要考虑使得每块设备上都有较为均衡的类别样本,避免出现样本种类在卡上过于单一,从而使得 BN 的参数估计不准。
渐进式均衡采样:为提升采样速度,该采样方式可以分两步进行。第一步先从类别中选择所需类别,第二步从对应类别中随机选择样本。
2. 分类器学习阶段
重新学习分类器(cRT):重新随机初始化分类器或者继承特征表示学习阶段的分类器,重点在于保证学习率重置到起始大小并选择 cosine 学习率。
τ-归一化(tau-normalization):τ 的选取在验证集上进行,如果没有验证集可以从训练集模仿平衡验证集,可参考原论文附录 B.5。
可学习参数放缩(LWS):学习率的选择与 cRT 一致,学习过程中要保证分类器参数固定不变,只学习放缩因子。
-
图像分类
+关注
关注
0文章
90浏览量
11914 -
深度学习
+关注
关注
73文章
5497浏览量
121068
原文标题:ICLR 2020 | 如何解决图像分类中的类别不均衡问题?不妨试试分开学习表征和分类器
文章出处:【微信号:tyutcsplab,微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
一种使用LDO简单电源电路解决方案
NPU在深度学习中的应用
一种基于深度学习的二维拉曼光谱算法

灵活多元的EMC学习方案


深度学习中的时间序列分类方法
深度学习与nlp的区别在哪
cnn卷积神经网络分类有哪些
人工智能数据中心的新型连接解决方案

一种利用光电容积描记(PPG)信号和深度学习模型对高血压分类的新方法
深度学习与度量学习融合的综述
FPGA在深度学习应用中或将取代GPU
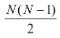
一种基于表征工程的生成式语言大模型人类偏好对齐策略





 工商网监
工商网监
评论