 详谈分布式系统的定义及属性
详谈分布式系统的定义及属性
分布式系统经常让人觉得云山雾罩,主要是因为相关知识点比较零散不成体系。但别担心,我很清楚这个有点尴尬的情况。我自学分布式计算的时候,就有很多次完全摸不着头脑。现在,经历过很多次尝试和死磕之后,我终于有信心可以跟大家分享一下有关分布式系统的基础知识了。
我还想讨论一下区块链技术给分布式相关的学术界和工业界已然带来的深远影响。区块链促使工程师和科学家们重新审视和反思那些在分布式计算领域已经根深蒂固的范式。也许在对这个领域的研究发展推动作用上,没有什么比区块链技术更强有力的了。
分布式系统肯定不能算新技术了。科学家和工程师们过去数十年中一直在研究这个课题。那么区块链跟分布式系统有什么关系呢?简单地说,如果没有分布式系统,也就不可能有区块链带来的技术贡献。
本质上,一条区块链就是一种新型的分布式系统。区块链自起源于比特币以来就一直对分布式计算领域持续产生影响。所以想真正搞明白区块链的运行原理,深入理解分布式系统的原理就至关重要。
但不幸的是,大部分关于分布式计算的文献资料,要么太晦涩艰深,要么散布在不计其数的学术论文中。更麻烦的是,分布式系统为了满足不同的需求,可能有多达上百种不同的架构。要把这些都归纳成一个统一且易于理解的框架的确很困难。
因为这个领域涉及知识点太广,我必须很专注在我力所能及可以讲明白的部分。而且我需要一些概括性的描述以便对系统复杂性进行简化。请注意,我不会帮你成为这个领域的专家。但我会帮你快速入门分布式系统及其共识机制。
读完这篇长文之后,你应该会对以下内容有更深刻的认识:
什么是分布式系统,
分布式系统的特性,
分布式系统中的共识意味着什么,
基础共识算法(比如 DLS 和 PBFT)以及
为什么中本聪共识非常重要。
嗯,不作过多解释了,快上车。
什么是分布式系统?
一个分布式系统包括一组相互独立的进程(比如计算机),它们互相传递消息并进行协作以完成一个共同的任务(比如解决一个计算问题)。
简单的说,一个分布式系统就是一组计算机,它们互相协作以完成一个共同的任务。虽然组成分布式系统的进程是相互独立的,但整个系统对于终端用户而言可以看成只是一台计算机。
像我之前提到的,分布式系统可以有上百种架构。比如,一台普通的计算机也可以看成是一个分布式系统:中央处理器,内存,输入输出都是独立的进程,互相协作以完成共同的任务。
又比如飞机,下图中的不同组件协同工作,载你从A点飞到B点:
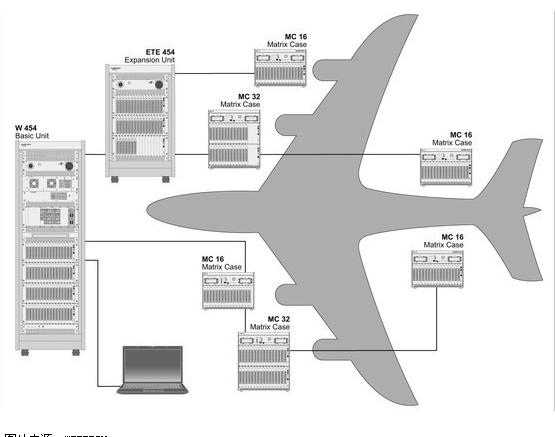
-图片来源:WEETECH -
在这篇文章中,我们将重点看看那些由空间上隔离的计算机组成的分布式系统。
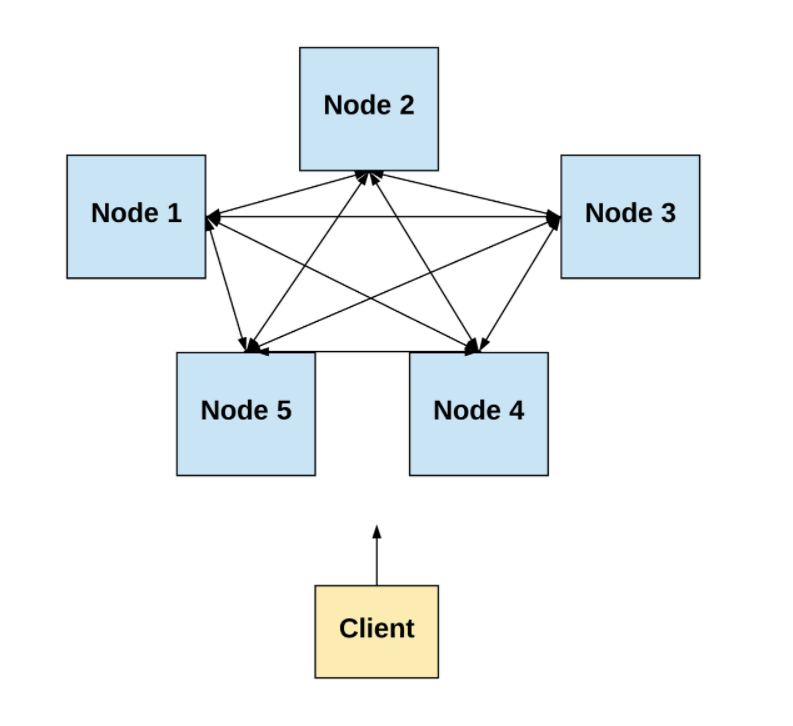
-作者制图-
请注意:我可能会使用若干术语表达与“”进程”相同的含义:“节点”(node、peer),“计算机”(computer),“组件”(component)。在这篇文章里它们都是同义词。类似地,“网络”(network)和“系统”(system)在本文中也是同义词。
分布式系统的特性
每个分布式系统都有一组特性,如下:
A) 并发性
进程在系统中是并发运行的,即同一时刻有多个事件发生。换句话说,任一时刻,系统中每个节点的事件执行都是相互独立的。
这就需要协作。
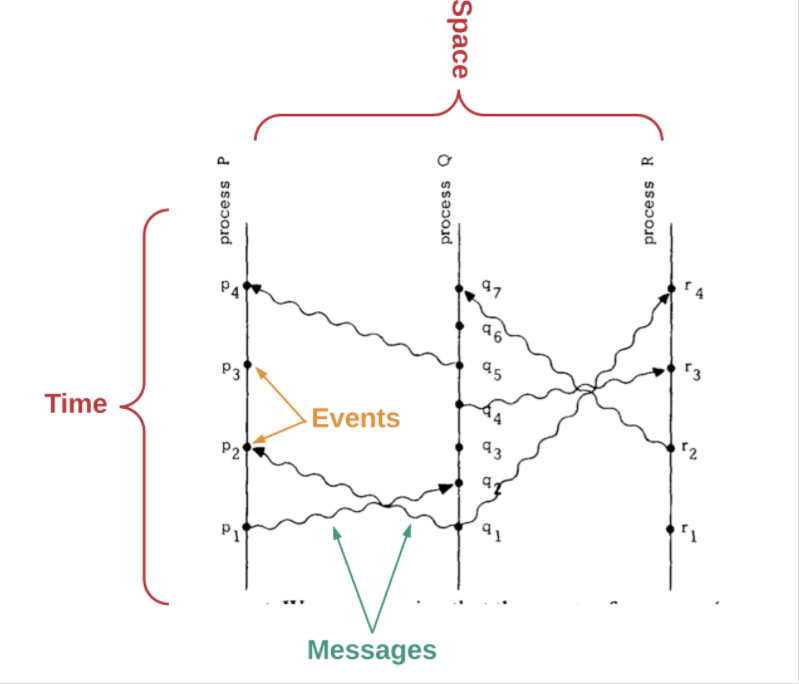
-分布式系统中的时间,时钟和事件排序,来自 Lamport, L (1978)-
B) 全局时钟的缺失
分布式系统要能运转,我们就需要一个确定事件排序的方法。但是,由于分布式系统中的计算机是空间上隔离且并发运行的,有时候很难说清楚两个事件中哪个先发生。换句话说,对于系统中所有计算机而言,没有一个统一的全局时钟来决定事件发生的顺序。
Leslie Lamport 在他的论文《分布式系统中的时间,时钟和事件排序》里,展示了如何通过以下事实来决定事件的先后顺序:
消息总是先发送,而后被接收。
每台计算机都有事件的排序。
通过确定事件之间的相对顺序(哪个先发生,哪个后发生),我们就可以得到关于系统中事件的一个局部排序(partial ordering)。Lamport 的论文描述了一种算法,要求每台计算机都监听其它计算机。这样,所有事件就可以根据这个局部排序得到全局排序。
但是,如果完全基于每个独立计算机监听到的事件进行排序,有可能会碰到这种情况:得出的排序与外部用户的观察不一致。所以,论文提到该算法仍然无法完全排除异常情况。最后,Lamport 讨论了如何通过适当地同步物理时钟避免上述异常。
但是,等一下——这里有个很重要的前提:协调独立的时钟并使之同步是一个非常复杂的计算机科学问题。即使你一开始把一堆时钟调成同步的状态,一段时间后它们的计时也会开始产生偏差。这被称作“时钟偏移”,是一种时钟计时频率发生细微差别的现象。
实质上,Lamport 的论文证明了:在由空间上隔离的一组计算机组成的分布式系统中,时间和事件排序是导致系统可能出错的障碍根源。
C) 单点可能出错
理解分布式系统的一个关键点在于认识到,分布式系统中的组件是会出错的。这也是分布式系统被称作“容错分布式计算”的原因。不出错的系统是不可能存在的。现实当中的系统总是暴露在许多可能的错误和故障风险之下,这些故障包括程序崩溃;消息丢失、实真、重放;网络隔离导致的消息延迟或丢帧;甚至是进程完全失控、恶意发送消息。
错误可以被大致分为三类:
崩溃错误:组件没有预警就停止工作(比如计算机崩溃了)。
遗漏错误:组件发了一个消息但没有被别的节点收到(比如这条消息丢包了)。
拜占庭错误:组件不按既定规则工作。这种类型的错误在可控环境中不会发生(比如谷歌和亚马逊的数据中心),因为一般认为那种环境中系统里不会发生恶意行为。与之相反,拜占庭错误会发生在所谓的“敌对环境”中。简单来说,当一组去中心化的独立参与者作为节点加入某个分布式网络后,这些参与者可以完全不按既定规则行动,也就是说它们可以恶意地更改消息、拦截消息或者根本不发送任何消息。
了解上述概念后,那分布式系统的目标就可以定义为:为一个存在可能出错组件的系统设计协议,期望该系统仍然能完成组件的共同任务并对用户提供可用的服务。
考虑到所有的系统都可能会出错,那我们建立一个分布式系统的核心考量就是,它是否可以在部分组件发生异常(无论是因为非恶意的行为比如崩溃-出错或者遗漏错误,还是因为恶意行为比如拜占庭错误)的情况下继续工作。
粗略地说,建立分布式系统有两种可考虑的模式:
1) 简单容错
在一个简单容错系统中,我们假设系统中所有组件都会处于以下两种状态中的一个:要么严格遵循协议工作,要么不遵循。这种类型的系统可以处理节点下线或者宕机的情况。但是它没法处理不按既定规则工作或者恶意工作的节点。
2A) 拜占庭容错
简单容错系统在非可控环境中用处不大。在一个节点由独立参与者控制,且通过无需权限的开放互联网进行通信的去中心化网络里,我们需要考虑到,网络中可能出现恶意节点(或者说“拜占庭式”节点)。因此,在拜占庭容错系统中,我们假设节点可能会宕机或者作恶。
2B) BAR容错
尽管大多数现实系统都被设计成可以容忍拜占庭错误,有些专家认为,这些设计太过宽泛,并没有考虑到所谓的“利己性”出错,即节点可能因为出于合理的自身利益而采取恶意行为。换句话说,根据不同的激励,节点可能诚实,也可能不诚实。所以如果激励足够多,甚至可能大部分节点都会不诚实。
更正式的定义一下,这就是 BAR 模式-同时考虑了拜占庭出错和利己性出错的情况。BAR 模式假设系统中有下列三种参与者:
拜占庭:这种节点是恶意的并且就是试图让你玩完。
利他:始终遵循系统协议的诚实节点。
利己:这类节点只在遵循协议有利于自身时才会遵循。
D) 消息传递
如我前述,分布式系统总的计算机通过互相之间的“消息传递”来沟通和协作。消息可以通过任何一种消息协议传递,比如 HTTP 或者 RPC,亦或是为特定系统实现的一套定制协议。有两种消息传递的环境:
1) 同步
在同步系统中,我们假定消息会在一个固定且已知的时间范围内接收到。
同步消息传递在概念上更简单,因为用户会有一个时间上的保证:当他们发送某条消息后,接收方会在一定时间内收到它。这就使得用户可以为他们的协议设置一个消息传递的耗时上限。
但是,这种假设在现实生活当中的分布式系统中不切实际:因为组件计算机们可能会崩溃,或者下线,而且消息也可能丢包,重复,延时或者没有按照发送顺序被接收。
2) 异步
在异步消息传递系统中,我们假定系统可能导致某条消息一直被延误,导致消息重放,或者乱序发送消息。换句话说,在这种环境下,消息传递的预期耗时是没有上限的。
-
分布式
+关注
关注
1文章
923浏览量
74606 -
分布式系统
+关注
关注
0文章
146浏览量
19293 -
区块链
+关注
关注
111文章
15563浏览量
106623
发布评论请先 登录
相关推荐






 工商网监
工商网监
评论