 Python爬虫入门知识:解析数据篇
Python爬虫入门知识:解析数据篇
首先,让我们回顾一下入门Python爬虫的四个步骤吧:
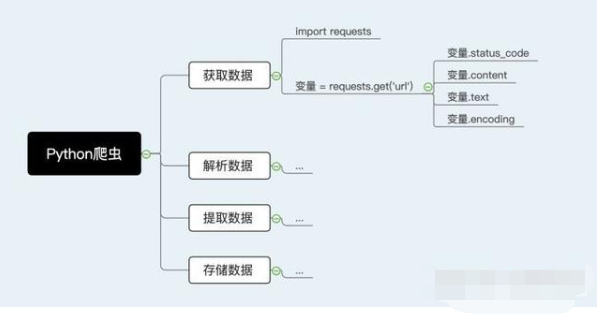
而解析数据,其用途就是在爬虫过程中将服务器返回的HTML源代码转换为我们能读懂的格式。那么,接下来就正式进入到解析数据篇的内容啦。
Part 1:了解HTML
HTML(Hyper Text Markup Language)为超文本标记语言。简单来讲,就是一种用于构建网页的编程语言。其主要组成部分为网页头(《head》元素)与网页体(《body》元素)。一般情况下,网页头部分会定义HTML文档的编码以及网页的标题。而网页体部分则决定着一个网页中的正文内容。

在一个HTML文档内,我们可以看到许多被《》括住的内容,它们被称作一个标签。标签通常是成对出现的。比如网页头部分的代码中含有《head》以及《/head》,网页体部分的代码中含有《body》以及《/body》。
在了解过HTML的基本信息之后,下一步我们就可以去解析这些数据了。
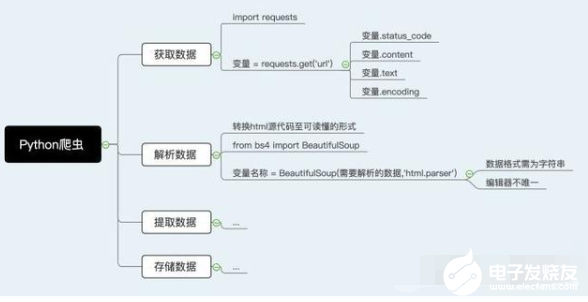
在解析与提取数据的过程中,我们会用到一个强大的工具,即BeautifulSoup库。由于BeautifulSoup不属于Python标准库,因此需要单独进行下载。Mac用户需打开终端,输入代码pip install BeautifulSoup4。Windows用户需运行CMD,输入代码pip install BeautifulSoup4。下载完成后,在编辑器内输入以下代码即可实现BeautifulSoup库的调用。

Part 3:运用BeautifulSoup解析数据
具体用法:变量名称 = BeautifulSoup(需要解析的数据,‘html.parser’)
备注:1. BeautifulSoup()内的第一个参数,即需要解析的数据,类型必须为字符串,否则运行时系统会报错。2. ‘html.parser’为Python内置库中的一个解析器。它的运行速度较快,使用方法也比较简单。但是它并不是唯一的解析器,大家可以使用其它的解析器进行操作,但是具体用法可能会略有不同。

总结:
-
数据
+关注
关注
8文章
6867浏览量
88799 -
网络爬虫
+关注
关注
1文章
52浏览量
8641 -
python
+关注
关注
55文章
4778浏览量
84439
发布评论请先 登录
相关推荐
Python库解析:通过库实现代理请求与数据抓取
详细解读爬虫多开代理IP的用途,以及如何配置!
用pycharm进行python爬虫的步骤
常见的数据采集工具的介绍
python解析netflow数据到csv的流程详解

Python怎么读取STM32串口数据?
如何解决Python爬虫中文乱码问题?Python爬虫中文乱码的解决方法
爬虫的基本工作原理 用Scrapy实现一个简单的爬虫





 工商网监
工商网监
评论